Top 5 Machine Learning Practices Recommended by Experts
This article is intended to help beginners improve their model structure by listing the best practices recommended by machine learning experts.

Introduction
Machine learning has been a subject of intense media hype with more organizations adopting this technology to handle their everyday tasks. Machine learning practitioners may be able to present the solution but enhancing the model performance can be very challenging at times. It is something that comes with practice and experience. Even after trying out all the strategies, we often fail to improve the accuracy of the model. Therefore, this article is intended to help beginners improve their model structure by listing the best practices recommended by machine learning Experts.
Best Practices
1. Focusing on the data
The importance of the data cannot be ignored in the world of machine learning. Both the quality and the quantity of the data can lead to stronger model performance. It's often time taking and more complex than crafting the machine learning models themselves. This step is often referred to as data preparation. It can be further classified into the following steps:
- Articulating the Problem - To avoid overcomplicating your project try to get an in-depth knowledge of the underlying problem that you are trying to solve. Categorize your problem into classification, regression, clustering or recommendation, etc. This simple segmentation can help you collect the relevant dataset that is most suitable for your scenario.
- Data Collection - Data collection can be a tedious task. As the name suggests, it is the collection of historic data to find recurring patterns. It can be categorized into structured (excel or .csv files) and unstructured data (photos, videos, etc). Some of the famous sources to borrow your dataset are:
- Data Exploration - This step involves identifying the problems and patterns in the dataset with the help of statistical and visualization techniques. You have to perform various tasks like spotting the outliers, identifying the data distribution and relationship between the features, looking out for inconsistent and missing values, etc. Microsoft Excel is a popular manual tool used for this step.
- Data Cleaning and Validation - It involves weeding out the irrelevant information and addressing the missing values by various imputation tools. Identify and remove the redundant data. A lot of open source options like OpenRefine and Pandera etc are available to cleanse and validate data.
2. Feature Engineering
It is another essential technique to improve model performance and speed up data transformation. Feature engineering involves infusing new features into your model from features that are already available. It can help us identify the robust features and remove the correlated or redundant ones. However, it requires domain expertise and may not be feasible if our initial baseline already includes a diverse set of features. Let's understand it from an example. Consider that you have a dataset containing the length, width, and price of the house as follows:
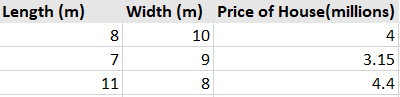
Instead of going with the above dataset, we can introduce another feature named “Area” and measure only the impact of that variable on the Price of the house. This process falls under the category of Feature Creation.

Similarly, Feature Transformation and Feature Extraction can prove valuable depending on our project domain. Feature Transformation involves applying the transformation function on a feature for a better visualization while in Feature Extraction, we compress the amount of data by only extracting the relevant features.
Although, Feature Scaling is also a part of Feature Engineering I have discussed it separately to focus on its importance. Feature Scaling is the method used to normalize the range of independent variables and features. Why is this step so important? Most algorithms like linear regressions, logistic regression, and neural networks make use of gradient descent as an optimization technique. Gradient descent heavily depends upon the range of features to determine the step size towards the minima but most of our data vary drastically in terms of ranges. This thing compels us to normalize or standardize our data before feeding it into the model. The two most important techniques in this regard are:
- Normalization - Normalization is the technique to bound your data typically between ranges [0,1] but you can also define your range [a,b] where a and b are real numbers.

- Standardization - Standardization transforms your data to have a mean of 0 and a variance of 1. We first calculate the standard deviation and mean of the feature and then calculate the new value using this formula:
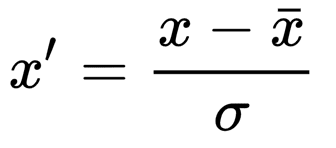
There has been a lot of debate to determine which one is better and some findings showed that for a gaussian distribution, standardization was more helpful as it was not affected by the presence of outliers and vice versa. But, it depends upon the type of problem that you are working on. Hence, it's highly recommended to test both and compare performance to figure out what works best for you.
3. Play with regularization
You might have encountered a situation when your machine learning models perform exceptionally well on your training data but fails to perform well on the test data. This happens when your model is overfitting your training data. Although there are a lot of methods to combat overfitting like dropping out layers, reducing the network capacity, Early stopping, etc but regularization outperforms all. What exactly is Regularization? Regularization is a technique that prevents overfitting by shrinking the coefficients. This results in a simplified model that performs more efficiently while making predictions. There are two types of regularization:
- L1 Regularization - It is also known as Lasso Regression. It forces some of the coefficients estimates to exactly become zero by adding a penalty to the absolute value of the magnitude of coefficients. It forms a sparse model and is useful for feature selection.
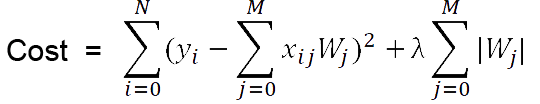
- L2 Regularization - It is also known as Ridge Regression. It penalizes the model by adding the square of the absolute value of the magnitude of the coefficients. Hence, it forces the coefficients to have a value close to zero but not exactly zero. It improves the interpretability of the model.

Although L2 regularization gives a more accurate prediction than L1 it comes at the cost of computational power. L2 may not be the best choice in case of outliers as the cost increases exponentially due to the presence of a square. Hence, L1 is more robust as compared to L2.
4. Identifiying the errors
It is really important that we keep the track of what kind of errors our model is making for optimization purposes. This task can be performed by means of various visualization plots depending upon the type of problem to be solved. Some of them are discussed below:
- Classification - Classification models are the subset of supervised learning that classifies the input into one or more categories based on the generated output. Classification models can be visualized by means of various tools such as:
- Classification Report - It is an evaluation metric that shows the precision, F1 score, Recall, and Support. It gives a good overall understanding of your model’s performance.
- Confusion Matrix - It compares the true values with the predicted ones. As compared to the classification report, It provides a deeper insight into the classification of individual data points rather than top-level scores.
- Regression - A Regression model predicts the relationship between the independent and dependent variables by providing the desired function. It makes the predictions in continuous space and the following are the evaluation metrics used for it:
- Residual Plots - It shows the independent variables along the horizontal axis and the residuals on the vertical axis. If the data points are randomly dispersed across the horizontal axis then a linear model is a more appropriate fit and vice versa.
- Prediction Error Plots - It shows the actual target against the predicted values to give an idea about the variance. A 45-degree line is where the prediction exactly matches the model.
5. Hyperparameter tunining
Hyperparameters are set of parameters that cannot be learned by the algorithm itself and are set before the learning process begins e.g learning_rate (alpha),mini-batch size, No of layers, No of hidden units, etc. Hyperparameter tuning refers to the process of selecting the most optimal hyperparameters for a learning algorithm that minimizes the loss function. In a simpler network, we experiment on separate versions of the model and with different combinations of the hyperparameters but this may not be the suitable option for the more complex networks. In that case, we make the optimal selection based on prior knowledge. Some of the widely used hyperparameter tuning methods to make an appropriate selection from the range of a hyperparameter space are as follows:
- Grid Search - It is the traditional and most commonly used method for hyperparameter tuning. It involves selecting the best set from the grid containing all the possible combinations of hyperparameters. However, it needs more computational power and time to perform its operation.
- Random Search - Instead of trying every combination, it selects the set of values in a random fashion from the grid to find the most optimum ones. It saves unnecessary computational power and time as compared to Grid search. Since no intelligence is being used, so luck plays a part in it and it yields high variance.
- Bayesian Search - It is used in applied machine learning and outperforms Random Search. It makes use of the Bayes theorem and takes into account the result of the previous iteration to improve the result of the next one. It needs an objective function that minimizes the loss. It works by creating a surrogate probability model of the objective function, then finding the best hyperparameters for the surrogate model, it is then applied to the original model and updates the surrogate model, and estimates the objective function. This process is repeated until we find the optimum solution for the original model. It does take less iteration but a longer time is required for each iteration.
In the above-mentioned methods, there is a trade-off between the number of iterations, runtime, and maximizing performance. Hence, the ideal method for your case depends on your priorities.
Conclusion
Machine learning and deep learning require good computational resources and subject matter expertise. Building ML models is an iterative process that involves realizing various tips to improve the overall model performance. I have listed down some of the best practices recommended by the ML experts to access the deficiencies in your current model. However, as I always say everything comes with sufficient practice and patience so keep on learning from your mistakes.
Kanwal Mehreen is aspiring Software Developer who believes in consistent hard work and commitment. She is an ambitious programmer with a keen interest in the field of Data Science and Machine Learning.