
7 SQL Concepts You Should Know For Data Science
The post explains all the key elements of SQL that you must know as a data science practitioner.

Image by Editor
Introduction
As the world is progressing towards digitalization, most companies are now data-driven. The huge amount of data they collect is stored in a database. The management, analysis, and processing of this data is made through a DBMS(Database Management System). As a consequence of this shift, data science came forward as one of the most emerging fields with countless job opportunities. A data scientist needs to extract the data from the database and this is where SQL comes into play. You must have heard about the topmost data science skills to master this field and SQL is one of them. Now, the question is: Do I really need to master SQL as a good data scientist?
The answer is NO, but essential knowledge of SQL is required as it has become a standard for many database systems. This article is intended to mention all the key elements of SQL that you must know and are recommended by data science practitioners.
Need of SQL in Data Science
SQL stands for Structured Query Language and is aimed to manage the relational database. Let us first understand the need for SQL in data science. What makes it unique and one of the most sought-after skills in data science? Below are some of the points to help you understand its importance:
- Wide Usage: Although it is approximately 40 years old, it is used for querying in the majority of relational database systems and has become the standard tool to experiment with data.
- Simplifies Understanding of Data: SQL is very handy in navigating through the database content. It makes you understand the peculiarities in an effective manner.
- Easy to Learn: It is the perfect starting point for the newbie with simple English-like syntax and you can extract valuable insights with just a few lines of code.
- Enables processing of big data masses: SQL enables you to manage a huge amount of data in an organized way making it an ideal choice for data science applications.
- Compatibility with other programming languages & applications: Integrating SQL with languages like Python, C++, R, etc is very convenient. It also supports business intelligence and data visualization tools like Power BI, and Tableau making the development process a little bit easier.
Seven SQL Concepts
1) Understanding of Basic Commands
Knowledge of basic commands builds the foundation for lifelong learning. Otherwise, you will just be memorizing the facts without understanding how they fit together. Some of the most commonly used SQL commands are as follows:
- SELECT & FROM: to retrieve the attributes of data from the mentioned table.
- SELECT DISTINCT: it eliminates duplicate rows and displays only the unique records.
- WHERE: it filters the record and shows only the ones that satisfy the given condition.
- AND, OR, NOT: not execute the query when the condition is not True. While, AND and OR are used to apply multiple conditions.
- ORDER BY: it sorts the data in ascending or descending order
- GROUP BY: it groups identical data.
- HAVING: data aggregated by Group By can be further filtered out here.
- Aggregate functions: aggregate functions like COUNT(), MAX(), MIN(), AVG(), and SUM() are used to perform operations on the given data.
Let's take an example to apply them to an Employee table,
| ID | Name | Department | Salary ($) | Gender |
| 1 | Julia | Admin | 20000 | F |
| 2 | Jasmine | Admin | 15000 | F |
| 3 | John | IT | 20000 | M |
| 4 | Mark | Admin | 17000 | M |
Now, we want to get the Average salary of females working in the Admin Department.
SELECT Department,
AVG(Salary)
FROM Employees
WHERE Gender="F"
GROUP BY Department
HAVING Department = "Admin";
Output:
Admin | 17500.0
2) Case When
It is a really powerful and flexible statement in SQL used to write complex conditional statements. It offers the functionality of the IF.THEN.ELSE statements. Let's have a look at its syntax,
CASE expression
WHEN value_1 THEN result_1
WHEN value_2 THEN result_2
...
WHEN value_n THEN result_n
ELSE result
END
It executes the statements in order and returns the value as soon as the condition becomes True. If none of the conditions is satisfied the ELSE block is executed and if it's not there, NULL is returned.
Let's suppose, we have a Students Database and we want to grade them based on their marks then the following SQL statement can be used:
SELECT student_name,
marks,
CASE
WHEN marks >= 85 THEN 'A'
WHEN marks >= 75
AND marks < 85 THEN 'B+'
WHEN marks >= 65
AND marks < 75 THEN 'B'
WHEN marks >= 55
AND marks < 65 THEN 'C'
WHEN marks >= 45
AND marks < 55 THEN 'D'
ELSE 'F'
END AS grading
FROM Students;
3) Subqueries
As a data scientist, the knowledge of subqueries is essential as they need to work with different tables and the result of one query may be used again to further restrict the data in the main query. It is also known as the nested or the inner query. The subquery must be enclosed in the parenthesis and it is executed before the main query. If it returns more than one row, then it is called a multi-line subquery and multi-line operators must be used with it.
Suppose that the insurance company introduces a new policy and it cancels the insurance of people whose age has exceeded 80. This can be done with the help of the subquery as follows:
DELETE
FROM INSURANCE_CUSTOMERS
WHERE AGE IN
(SELECT AGE
FROM INSURANCE_CUSTOMERS
WHERE AGE > 80 );
The inner subquery selects all the customers above 80 years of age and then the Delete operation is performed on this group.
4) Joins
SQL joins are used to combine the rows from multiple tables based on the logical relationship between them. The 4 types of SQL joins are listed below:
- Inner Join: inner join shows only those rows from both tables that meet the given condition. It can be referred to as an intersection in terms of set terminology.

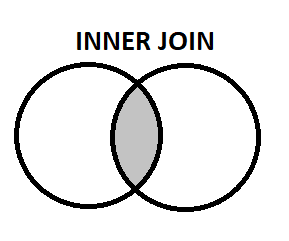
SELECT Student.Name
FROM Student
INNER JOIN Sports ON Student.ID = Sports.ID;
It returns those students who have registered themselves in sports. Note: Sports ID is the same as the registration ID of the Student.
- Left Join: it returns all the records from the LEFT table while only the matching records from the right table are displayed.
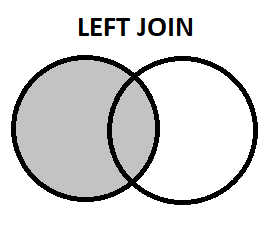
SELECT Student.Name
FROM Student
LEFT JOIN Sports ON Student.ID = Sports.ID;
- Right Join: It is just the opposite of what left join does.
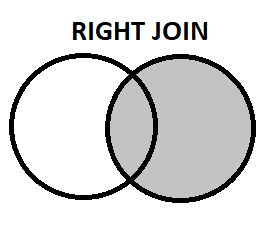
SELECT Student.Name
FROM Student
RIGHT JOIN Sports ON Student.ID = Sports.ID;
- Full Join: it contains all the rows from both the table and if it does not have a corresponding matching entry a NULL value is displayed.
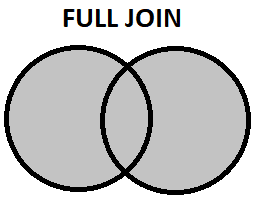
SELECT Student.Name
FROM Student
FULL JOIN Sports ON Student.ID = Sports.ID;
5) Stored Procedures
Stored procedures allow us to store multiple SQL statements in our database to use them later on. It enables reusability and can also accept the parameter values when called. It enhances the performance and it is easier to make any modifications with it.
CREATE PROCEDURE SelectStudents @Major nvarchar(30),
@Grade char(1) AS
SELECT *
FROM Students
WHERE Major = @Major
AND Grade = @Grade GO;
EXEC SelectStudents @Major = 'Data Science',
@Grade = 'A';
This procedure allows us to extract the students of different majors based on their grades. For example, we are trying to extract all the students with majors in Data Science that have an A grade. Note that CREATE PROCEDURE is just like the function declaration and it needs to be called using EXEC for execution purposes.
6) String Formatting
We all know that the raw data needs to be cleaned to increase overall productivity resulting in quality decision-making. String formatting plays a huge role in this context and it involves manipulating the strings to remove irrelevant things. SQL offers a wide range of string functions to transform and work with strings. The 5 most commonly used among them are as follows:
- CONCAT: it is used to add two or more strings together.
SELECT CONCAT(Name, ' has a major of ', Major)
FROM Students
WHERE student_Id = 37;
- SUBSTR: it returns the portion of the string and takes the starting position and the length of the substring to be returned in its parameters.
SELECT student_name,admission_date,
SUBSTR(admission_date, 4, 2) AS day
FROM Students
The day column will appear separately that is extracted from admission_date.
- TRIM: the main job of trim is to remove the characters from the beginning of strings, the ending of strings or both if specified. You must specify the leading, trailing, or both, then the character to remove followed by the string to remove from.
SELECT age,
TRIM(trailing ' years' FROM age)
FROM Students
It will change “26 years” to “26”.
- INSERT: it allows us to insert the string within the given string at the specified position. You have to mention the position and length of the new substring that you want to write. Note that this new string will overwrite the previous text.
SELECT INSERT("OldWebsite.com", 1, 9, "NewWebsite");
It will be updated to NewWebsite.come.
- COALESCE: it can be used to replace the null values with user-defined values that are often required in data science.
SELECT COALESCE (NULL, NULL, 10, 'John’')
This will return 10.
7) Window Functions
Window functions are similar to the aggregate functions but it does not cause your rows to collapse into a single row after the calculation. Instead, the rows retain their separate identities. They are grouped into three main categories:
- Aggregate functions: it displays the aggregate values from the numerical columns like AVG(), COUNT(), MAX(), MIN(), SUM(), etc.
SELECT name,
AVG(salary) over (PARTITION BY department)
FROM Employees;
It displays the avg salary of different departments from the Employees Table.
- Value functions: each partition is assigned some values using the value window functions. Some of the most commonly used value functions are LAG(),LEAD(), FIRST_VALUE(), LAST_VALUR(), and NTH_VALUE().
SELECT
bank_branch, month, income,
LAG(income,1) OVER (
PARTITION BY bank_branch
ORDER BY month
) income_next_month
FROM Bank;
We compare the income of different branches of the bank for the current month with the previous one.
- Ranking Functions: they are useful to assign a ranking to rows based on some predefined ordering.ROW_NUMBER(), RANK(), DENSE_RANK(),PERCENT_RANK(),NTILE() are the few to mention.
SELECT
product_name, price,
RANK () OVER (
ORDER BY list DESC
) price_hightolow
FROM Products;
Products are ranked based on their prices using RANK().
Conclusion
I hope you enjoyed reading the article and it gives you a comprehensive understanding of how much SQL you need to know as a data scientist. Here are a few resources to help you out if you want to dig deeper into these concepts:
W3Schools
Kanwal Mehreen is an aspiring software developer with a keen interest in data science and applications of AI in medicine. Kanwal was selected as the Google Generation Scholar 2022 for the APAC region. Kanwal loves to share technical knowledge by writing articles on trending topics, and is passionate about improving the representation of women in tech industry.