Research Leaders on Data Mining, Data Science, and Big Data key trends, top papers
We asked global research leaders in Data Science and Big Data what are the most interesting research papers/advances of 2014 and what are the key trends they see in 2015. Here are their answers.
By Gregory Piatetsky @kdnuggets,
and Anmol Rajpurohit @hey_anmol
Jan 2015.
In December 2014 KDnuggets reached to a number of Data Mining, Data Science, and KDD research leaders and asked them 2 questions:
1. What was the most important research paper on Data Science, Data Mining, Databases in 2014?
Or if you don't want to select from papers of others, what was your most favorite paper in 2014?
2. Which Data Science, Data Mining, Big Data trend do you expect to dominate in 2015?
The most popular trends among mentioned were
AI, Deep Learning, Healthcare informatics/analytics.

As for the papers, we found that many researchers were so busy that they did not really have the time to read many papers by others.
Of course, top researchers learn about works of others from personal interactions, including conferences and meetings, but we hope that professors have enough students who do read the papers and summarize the important ones for them!
Here are the answers.
Charu Aggarwal, Distinguished Research Staff Member at the IBM T. J. Watson:
Individual papers are rather incremental these days and broad advancements can only be understood in the context of collections of papers. Furthermore, most of these advancements existed before 2014, but 2014 saw a significant push in these directions. The three most important areas of growth in the data science field are as follows:
 1. While the IoT (Internet of Things) phenomenon started around 2011 or 2012, it has greatly sped up in 2014, especially in terms of its impact on data science. This is because of the confluence between the area of big data, data streams, and the natural data intensive applications in the IoT paradigm. Smart healthcare, social sensing, smart cities are examples of these phenomenon and there is also significant commercial interest. History has shown us that advancements are most permanent when they are supported by commercial interests.
1. While the IoT (Internet of Things) phenomenon started around 2011 or 2012, it has greatly sped up in 2014, especially in terms of its impact on data science. This is because of the confluence between the area of big data, data streams, and the natural data intensive applications in the IoT paradigm. Smart healthcare, social sensing, smart cities are examples of these phenomenon and there is also significant commercial interest. History has shown us that advancements are most permanent when they are supported by commercial interests.
2. There has been an increase in the number of papers written on the interplay between big data/data streams and more complex data types. In the past, most of the streaming papers were focused on the notion of multidimensional data, which is an important but limited paradigm. The temporal and streaming aspects are now being studied in the context of complex data types such as graphs, social networks, and social streams. This area of analysis is rich and remains largely unexplored.
 3. The focus on healthcare data analytics has also become increasingly prominent in 2014. The key areas of focus include smart technologies, electronic health records, data integration/fusion, and privacy. The issue of privacy remains the primary challenge for data scientists and also the greatest opportunity for new research.
3. The focus on healthcare data analytics has also become increasingly prominent in 2014. The key areas of focus include smart technologies, electronic health records, data integration/fusion, and privacy. The issue of privacy remains the primary challenge for data scientists and also the greatest opportunity for new research.
The future developments are likely to mirror recent advancements. Research is a continuous process, and one cannot expect the advancements to be decoupled from the recent developments.
In the longer term, as processing power increases, I expect data science to play a key role in the development of amazing artificial intelligence applications. For example, the defeat of human champions by the automated Watson system in Jeopardy was a landmark in artificial intelligence. How far can one go?
I believe that the development of more efficient processors and compact storage systems will open frontiers, which were previously considered unattainable.
Mohammed J. Zaki a Professor of Computer Science at RPI:
1) I think the emphasis on Big Data will continue, with newer/better systems and algorithms for big DM and ML.
2) There will be increased focus on health informatics data, i.e., electronic health records and personal health data management/analysis
3) Focus on "data mining for social good" will continue to make waves, i.e., open source Gov data mining, smart cities, smart utilities, etc.
Bing Liu , Professor, UIC; Chair, SIGKDD:
I feel one of the key research issues for data science is how to make use of the big data in a novel way to go beyond what data mining researchers have done using a large amount of data in the past (e.g., scaling-up machine learning and data mining algorithms and data stream mining).
In my opinion, one of the long term trends is or should be to use the big and diverse data to discover common sense knowledge for continuous machine learning and data mining, i.e., to retain the results and knowledge learned in the past and use them to help future learning and problem solving. Without this lifelong learning capability, no system will ever be intelligent.
More intelligence is what the data science should go for in the big data era. Although standalone or pure statistical machine learning and data mining algorithms, which represent principled guessing, can still be improved, they have their limits. The question is how to go beyond such pure algorithmic approaches to push machine learning and data mining forward. I believe we should go for more intelligence, i.e., to learn as humans do.
(GP: continuous machine learning is the goal of CMU NELL: Never-Ending Language Learning system)
Johannes Gehrke, Tisch University Professor, Cornell:
Paper: Show and tell: A neural image caption generator, by Vinyals, Toshev, Bengio, and Erhan (Google) Arxiv 1411.4555
GP: This paper from Google researchers presents an amazing system which combines deep learning, computer vision and machine translation to automatically generate natural sentences describing an image. This paper was widely covered, and was in KDnuggets Top Tweets in November 2014.
Trends: Deep networks
Qiang Yang, Professor, HKUST and the head of Noah's Ark Lab:
Paper: Data Science and its relation to Big Data and data-driven decision making. F. Provost and T. Fawcett. Big Data 1(1), 2013.
Trends: "Open Source Systems" and "Feature Engineering" are two trendy keywords that we will see more often in the coming year. Disk Centric and Network Centric Issues are questions concerned most by practitioners and will have big impact in the practical field.
Eamonn Keogh, Professor at UCR, a world leader in time series analysis:
Paper: I am a bit of a contrarian. I like papers that show a flaw or weakness in existing work, or show that a common assumption was unwarranted.
"Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images", by Anh Nguyen, Jason Yosinski, Jeff Clune, is the most interesting such paper I have read in years. As an aside, the authors have done a spectacular job in presentation. Not only is the paper very well written, but there is a great supporting webpage with a video and even a useful FAQ.
Trends:
Not trends in data science per se, but two nice meta-trends in how we do data science research are:
1) Some nice empirical work on how good is peer review, i.e. the NIPS consistency experiment
2) A movement towards insisting on reproducibility, i.e. ACM SIGMOD 2015 Reproducibility
GP: See also KDnuggets Interview with Eamonn Keogh: SPOTLIGHT: Can Data Science Save Humanity from Mosquitoes and other Deadly Insects?
Philip S. Yu, UIC Distinguished Professor and Wexler Chair in Information Technology:
Paper:
Detecting anomalies in dynamic rating data: a robust probabilistic model for rating evolution. , by Stephan Gunnemann, Nikou Gunnemann, Christos Faloutsos. KDD 2014: 841-850
Trends:
Fusion data from heterogeneous data sources.
If you look at the papers in the major conferences, quite a few of them are fusing multiple data sources to improve the prediction. I think it will be an important trend going forward.
Jian Pei, Professor, Simon Fraser University:
Paper: (from Jian Pei group)
L. Duan, G. Tang, J. Pei, J. Bailey, G. Dong, A. Campbell, and C. Tang. "Mining Contrast Subspaces". In Proceedings of the 18th Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD'14), Tainan, Taiwan, May 13-16, 2014.
The paper proposes a new research problem that we met again and again in a series of practical applications. It won the best paper award in the PAKDD 2014 conference.
Trends:
Big data will go deeper into traditional offline domains, and will come closer to customers in their daily life. Novel, big data enabled business models become a key in unlocking the power of big data.
Jeff Ullman, Professor of Computer Science (Emeritus), Stanford:
Paper:
I'm not sure I can select best 2014 paper, but I want to plug my son Jonathan's recent work with Moritz Hardt: "Preventing False Discovery in Interactive Data Analysis is Hard", 2104 FOCS, pp. 454-463. arXiv 1408.1655
The idea is that any algorithm that asks a sequence of queries of a database of size n, where one query depends on the outcome of previous queries, can be led to false conclusions after O(n^3) queries. They believe this can be reduced to O(n^2) but can't prove it. Essentially all interesting data-analysis algorithms have this property, e.g., gradient descent. You can think of it as a stronger Bonferroni's principle for non-independent trials.
Trends:
I suspect that "deep learning" is going to be all the rage in 2015, but that like with most approaches to data analysis, it will have a few successes that are widely trumpeted and lots of failures that never see the light of day.
Jiawei Han, Abel Bliss Professor, Univ. of Illinois at Urbana-Champaign:
Papers (from Jiawei Han group:)
Xiang Ren, Jialu Liu, Xiao Yu, Urvashi Khandelwal, Quanquan Gu, Lidan Wang, and Jiawei Han, "ClusCite: Effective Citation Recommendation by Information Network-Based Clustering", in Proc. 2014 ACM SIGKDD Int. Conf. on Knowledge Discovery and Data Mining (KDD'14), New York, NY, Aug. 2014.
The following paper dated in 2015 but was accepted in Oct. 2014 is an even more favorable one by me but it is officially dated in 2015.
Ahmed El-Kishky, Yanglei Song, Chi Wang, Clare R. Voss, Jiawei Han, "Scalable Topical Phrase Mining from Text Corpora", PVLDB 8(3): 305 - 316, 2015. (Also, in Proc. 2015 Int. Conf. on Very Large Data Bases (VLDB'15), Hawaii, Sept. 2015)
Trends:
I believe statistical learning-based mining methods could become more dominant next year. In the long run, I expect heterogeneous information network creation and mining will become a key thing to turn structured or unstructured data to organized knowledge.
Lise Getoor, Professor, UCSC:
Paper:
Experimental evidence of massive-scale emotional contagion through social networks
Not necessarily the best data science paper, but certainly important for the discussions it brought up about data science ethics.
(GP: this paper describes a massive and very controversial Facebook experiment)
Trends:
Pedro Domingos, Professor, U. of Washington:
Paper:
1. Szegedy et al., "Intriguing properties of neural networks", ICLR-14.
 (GP: this paper was also covered in KDnuggets: see Does Deep Learning Have Deep Flaws?. It found that for every correctly classified image, one can generate an "adversarial", visually indistinguishable image that will be misclassified. This suggests potential deep flaws in all neural networks, including possibly a human brain. )
(GP: this paper was also covered in KDnuggets: see Does Deep Learning Have Deep Flaws?. It found that for every correctly classified image, one can generate an "adversarial", visually indistinguishable image that will be misclassified. This suggests potential deep flaws in all neural networks, including possibly a human brain. )
Trends:
Deep learning will continue to rack up successes and increase in popularity.
GP: See also KDnuggets Interview: Pedro Domingos: the Master Algorithm, new type of Deep Learning, great advice for young researchers
Dimitrios Gunopulos, Professor, University of Athens.
Papers:
I liked the following three papers from KDD 2014:
Trends:
Analysis and linking of heterogeneous streams, and Systems Security
In December 2014 KDnuggets reached to a number of Data Mining, Data Science, and KDD research leaders and asked them 2 questions:
1. What was the most important research paper on Data Science, Data Mining, Databases in 2014?
Or if you don't want to select from papers of others, what was your most favorite paper in 2014?
2. Which Data Science, Data Mining, Big Data trend do you expect to dominate in 2015?
The most popular trends among mentioned were
AI, Deep Learning, Healthcare informatics/analytics.
As for the papers, we found that many researchers were so busy that they did not really have the time to read many papers by others.
Of course, top researchers learn about works of others from personal interactions, including conferences and meetings, but we hope that professors have enough students who do read the papers and summarize the important ones for them!
Here are the answers.
Charu Aggarwal, Distinguished Research Staff Member at the IBM T. J. Watson:
Individual papers are rather incremental these days and broad advancements can only be understood in the context of collections of papers. Furthermore, most of these advancements existed before 2014, but 2014 saw a significant push in these directions. The three most important areas of growth in the data science field are as follows:
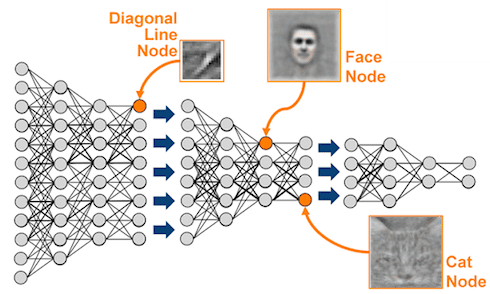
 1. While the IoT (Internet of Things) phenomenon started around 2011 or 2012, it has greatly sped up in 2014, especially in terms of its impact on data science. This is because of the confluence between the area of big data, data streams, and the natural data intensive applications in the IoT paradigm. Smart healthcare, social sensing, smart cities are examples of these phenomenon and there is also significant commercial interest. History has shown us that advancements are most permanent when they are supported by commercial interests.
1. While the IoT (Internet of Things) phenomenon started around 2011 or 2012, it has greatly sped up in 2014, especially in terms of its impact on data science. This is because of the confluence between the area of big data, data streams, and the natural data intensive applications in the IoT paradigm. Smart healthcare, social sensing, smart cities are examples of these phenomenon and there is also significant commercial interest. History has shown us that advancements are most permanent when they are supported by commercial interests.
2. There has been an increase in the number of papers written on the interplay between big data/data streams and more complex data types. In the past, most of the streaming papers were focused on the notion of multidimensional data, which is an important but limited paradigm. The temporal and streaming aspects are now being studied in the context of complex data types such as graphs, social networks, and social streams. This area of analysis is rich and remains largely unexplored.
 3. The focus on healthcare data analytics has also become increasingly prominent in 2014. The key areas of focus include smart technologies, electronic health records, data integration/fusion, and privacy. The issue of privacy remains the primary challenge for data scientists and also the greatest opportunity for new research.
3. The focus on healthcare data analytics has also become increasingly prominent in 2014. The key areas of focus include smart technologies, electronic health records, data integration/fusion, and privacy. The issue of privacy remains the primary challenge for data scientists and also the greatest opportunity for new research.
The future developments are likely to mirror recent advancements. Research is a continuous process, and one cannot expect the advancements to be decoupled from the recent developments.
In the longer term, as processing power increases, I expect data science to play a key role in the development of amazing artificial intelligence applications. For example, the defeat of human champions by the automated Watson system in Jeopardy was a landmark in artificial intelligence. How far can one go?
I believe that the development of more efficient processors and compact storage systems will open frontiers, which were previously considered unattainable.
Mohammed J. Zaki a Professor of Computer Science at RPI:
1) I think the emphasis on Big Data will continue, with newer/better systems and algorithms for big DM and ML.
2) There will be increased focus on health informatics data, i.e., electronic health records and personal health data management/analysis
3) Focus on "data mining for social good" will continue to make waves, i.e., open source Gov data mining, smart cities, smart utilities, etc.
Bing Liu , Professor, UIC; Chair, SIGKDD:
I feel one of the key research issues for data science is how to make use of the big data in a novel way to go beyond what data mining researchers have done using a large amount of data in the past (e.g., scaling-up machine learning and data mining algorithms and data stream mining).
In my opinion, one of the long term trends is or should be to use the big and diverse data to discover common sense knowledge for continuous machine learning and data mining, i.e., to retain the results and knowledge learned in the past and use them to help future learning and problem solving. Without this lifelong learning capability, no system will ever be intelligent.
More intelligence is what the data science should go for in the big data era. Although standalone or pure statistical machine learning and data mining algorithms, which represent principled guessing, can still be improved, they have their limits. The question is how to go beyond such pure algorithmic approaches to push machine learning and data mining forward. I believe we should go for more intelligence, i.e., to learn as humans do.
(GP: continuous machine learning is the goal of CMU NELL: Never-Ending Language Learning system)
Johannes Gehrke, Tisch University Professor, Cornell:
Paper: Show and tell: A neural image caption generator, by Vinyals, Toshev, Bengio, and Erhan (Google) Arxiv 1411.4555
GP: This paper from Google researchers presents an amazing system which combines deep learning, computer vision and machine translation to automatically generate natural sentences describing an image. This paper was widely covered, and was in KDnuggets Top Tweets in November 2014.

Trends: Deep networks
Qiang Yang, Professor, HKUST and the head of Noah's Ark Lab:
Paper: Data Science and its relation to Big Data and data-driven decision making. F. Provost and T. Fawcett. Big Data 1(1), 2013.
Trends: "Open Source Systems" and "Feature Engineering" are two trendy keywords that we will see more often in the coming year. Disk Centric and Network Centric Issues are questions concerned most by practitioners and will have big impact in the practical field.
Eamonn Keogh, Professor at UCR, a world leader in time series analysis:
Paper: I am a bit of a contrarian. I like papers that show a flaw or weakness in existing work, or show that a common assumption was unwarranted.
"Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images", by Anh Nguyen, Jason Yosinski, Jeff Clune, is the most interesting such paper I have read in years. As an aside, the authors have done a spectacular job in presentation. Not only is the paper very well written, but there is a great supporting webpage with a video and even a useful FAQ.
Trends:
Not trends in data science per se, but two nice meta-trends in how we do data science research are:
1) Some nice empirical work on how good is peer review, i.e. the NIPS consistency experiment
2) A movement towards insisting on reproducibility, i.e. ACM SIGMOD 2015 Reproducibility
GP: See also KDnuggets Interview with Eamonn Keogh: SPOTLIGHT: Can Data Science Save Humanity from Mosquitoes and other Deadly Insects?
Philip S. Yu, UIC Distinguished Professor and Wexler Chair in Information Technology:
Paper:
Detecting anomalies in dynamic rating data: a robust probabilistic model for rating evolution. , by Stephan Gunnemann, Nikou Gunnemann, Christos Faloutsos. KDD 2014: 841-850
Trends:
Fusion data from heterogeneous data sources.
If you look at the papers in the major conferences, quite a few of them are fusing multiple data sources to improve the prediction. I think it will be an important trend going forward.
Jian Pei, Professor, Simon Fraser University:
Paper: (from Jian Pei group)
L. Duan, G. Tang, J. Pei, J. Bailey, G. Dong, A. Campbell, and C. Tang. "Mining Contrast Subspaces". In Proceedings of the 18th Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD'14), Tainan, Taiwan, May 13-16, 2014.
The paper proposes a new research problem that we met again and again in a series of practical applications. It won the best paper award in the PAKDD 2014 conference.
Trends:
Big data will go deeper into traditional offline domains, and will come closer to customers in their daily life. Novel, big data enabled business models become a key in unlocking the power of big data.
Jeff Ullman, Professor of Computer Science (Emeritus), Stanford:
Paper:
I'm not sure I can select best 2014 paper, but I want to plug my son Jonathan's recent work with Moritz Hardt: "Preventing False Discovery in Interactive Data Analysis is Hard", 2104 FOCS, pp. 454-463. arXiv 1408.1655
The idea is that any algorithm that asks a sequence of queries of a database of size n, where one query depends on the outcome of previous queries, can be led to false conclusions after O(n^3) queries. They believe this can be reduced to O(n^2) but can't prove it. Essentially all interesting data-analysis algorithms have this property, e.g., gradient descent. You can think of it as a stronger Bonferroni's principle for non-independent trials.
Trends:
I suspect that "deep learning" is going to be all the rage in 2015, but that like with most approaches to data analysis, it will have a few successes that are widely trumpeted and lots of failures that never see the light of day.
Jiawei Han, Abel Bliss Professor, Univ. of Illinois at Urbana-Champaign:
Papers (from Jiawei Han group:)
Xiang Ren, Jialu Liu, Xiao Yu, Urvashi Khandelwal, Quanquan Gu, Lidan Wang, and Jiawei Han, "ClusCite: Effective Citation Recommendation by Information Network-Based Clustering", in Proc. 2014 ACM SIGKDD Int. Conf. on Knowledge Discovery and Data Mining (KDD'14), New York, NY, Aug. 2014.
The following paper dated in 2015 but was accepted in Oct. 2014 is an even more favorable one by me but it is officially dated in 2015.
Ahmed El-Kishky, Yanglei Song, Chi Wang, Clare R. Voss, Jiawei Han, "Scalable Topical Phrase Mining from Text Corpora", PVLDB 8(3): 305 - 316, 2015. (Also, in Proc. 2015 Int. Conf. on Very Large Data Bases (VLDB'15), Hawaii, Sept. 2015)
Trends:
I believe statistical learning-based mining methods could become more dominant next year. In the long run, I expect heterogeneous information network creation and mining will become a key thing to turn structured or unstructured data to organized knowledge.
Lise Getoor, Professor, UCSC:
Paper:
Experimental evidence of massive-scale emotional contagion through social networks
Not necessarily the best data science paper, but certainly important for the discussions it brought up about data science ethics.
(GP: this paper describes a massive and very controversial Facebook experiment)
Trends:
- Causality & decision making
- Interpretability
- Ethics and data science
Pedro Domingos, Professor, U. of Washington:
Paper:
1. Szegedy et al., "Intriguing properties of neural networks", ICLR-14.
 (GP: this paper was also covered in KDnuggets: see Does Deep Learning Have Deep Flaws?. It found that for every correctly classified image, one can generate an "adversarial", visually indistinguishable image that will be misclassified. This suggests potential deep flaws in all neural networks, including possibly a human brain. )
(GP: this paper was also covered in KDnuggets: see Does Deep Learning Have Deep Flaws?. It found that for every correctly classified image, one can generate an "adversarial", visually indistinguishable image that will be misclassified. This suggests potential deep flaws in all neural networks, including possibly a human brain. )
Trends:
Deep learning will continue to rack up successes and increase in popularity.
GP: See also KDnuggets Interview: Pedro Domingos: the Master Algorithm, new type of Deep Learning, great advice for young researchers
Dimitrios Gunopulos, Professor, University of Athens.
Papers:
I liked the following three papers from KDD 2014:
-
Reducing the Sampling Complexity of Topic Models, by Aaron Q Li (CMU), Amr Ahmed (Google), Sujith Ravi (Google), Alexander J Smola (CMU and Google), KDD-2014 Best paper award.
This paper presents an approximate sampler for topic models that theoretically and experimentally outperforms existing samplers thereby allowing topic models to scale to industry-scale datasets. - Towards Scalable Critical Alert Mining, Bo Zong, Yinghui Wu, Jie Song, Ambuj K. Singh, Hasan Cam, Jiawei Han, and Xifeng Yan
- Grouping Students in Educational Settings, Rakesh Agrawal, Behzad Golshan, Evimaria Terzi
Trends:
Analysis and linking of heterogeneous streams, and Systems Security