Datasets Over Algorithms
The average elapsed time between key algorithm proposals and corresponding advances is about 18 years; the average elapsed time between key dataset availabilities and corresponding advances is less than 3 years, 6 times faster.
By Quant Quanto, Space Machine.
Content without method leads to fantasy; method without content to empty sophistry.
- Johann Wolfgang von Goethe (“Maxims and Reflections”, 1892)

“Perhaps the most important news of our day is that datasets — not algorithms — might be the key limiting factor to development of human-level artificial intelligence,” according to Alexander Wissner-Gross in a written response to the question posed by Edge: “What do you consider the most interesting recent scientific news?”
At the dawn of the field of artificial intelligence, two of its founders famously predicted that solving the problem of machine vision would only take a summer. We now know that they were off by half a century. Wissner-Gross began to ponder the question of: “What took the AI revolution so long?” By reviewing the timing of the most publicized AI advances over the past 30 years, he found evidence that suggests a provocative explanation: perhaps many major AI breakthroughs have actually been constrained by the availability of high-quality training datasets, and not by algorithmic advances. Here we summarize the key AI milestones:
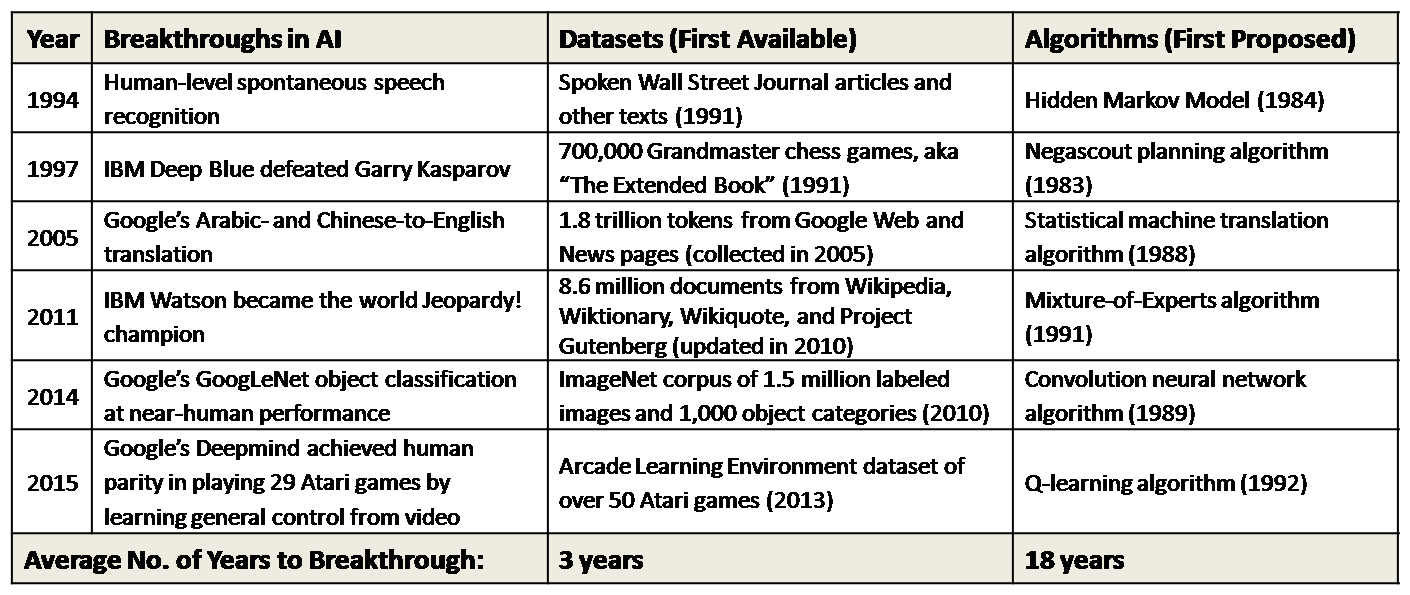
The average elapsed time between key algorithm proposals and corresponding advances was about 18 years, whereas the average elapsed time between key dataset availabilities and corresponding advances was less than 3 years, or about 6 times faster.
If true, this hypothesis have foundational implications for future progress in AI. For example, prioritizing the cultivation of high-quality training datasets might allow an order-of-magnitude speedup in AI breakthroughs over purely algorithmic advances. After all, focusing on dataset rather than algorithm is a potentially simpler approach. “Although new algorithms receive much of the public credit for ending the last AI winter,” concluded Alexander Wissner-Gross, “the real news might be that prioritizing the cultivation of new datasets and research communities around them could be essential to extending the present AI summer.”
We wonder if algorithmic trading systems might similarly benefit from the cultivation of new datasets and research communities around them.
What might that look like?
How do we learn to work with imperfect data?
What are the risks of trusting the data too much?
References:
- Wissner-Gross, Alexander (2016). Datasets Over Algorithms. Edge.
Retrieved from: www.edge.org/response-detail/26587 - Klein, Gary (2016). Blinded by Data. Edge.
Retrieved from: www.edge.org/response-detail/26692
Bio: Quant Quanto comes from a humble single-PC origin, and aspires to be a fully automatic, artificially intelligent fifth generation robot trader running in real time 24/7 on the latest x86 machines, with scalable computing power up to 46,464 cores in 22 racks at 3 locations (Quant Quanto is the nomme de plume of the mysterious, insightful, and prolific blogger at Space Machine).
Original. Reposted with permission.
Related:
- From Insight-as-a-Service to Insightful Applications
- Survey: Why Companies Still Fail to Get Full Value From Big Data
- How banks can beat new finance boys with data