An Excellent Resource To Learn The Foundations Of Everything Underneath ChatGPT
In this article, you will learn the fundamentals of what constitutes the core of ChatGPT (and the Large Language Models).

Image by Freepik
OpenAI, ChatGPT, the GPT-series, and Large Language Models (LLMs) in general – if you are remotely associated with the AI profession or a technologist, chances are high that you’d hear these words in almost all your business conversations these days.
And the hype is real. We can not call it a bubble anymore. After all, this time, the hype is living up to its promises.
Who would have thought that machines could understand and revert in human-like intelligence and do almost all those tasks previously considered human forte, including creative applications of music, writing poetry, and even programming applications?
The ubiquitous proliferation of LLMs in our lives has made us all curious about what lies underneath this powerful technology.
So, if you are holding yourself back because of the gory-looking details of algorithms and the complexities of the AI domain, I highly recommend this resource to learn all about “What Is ChatGPT Doing … and Why Does It Work?”
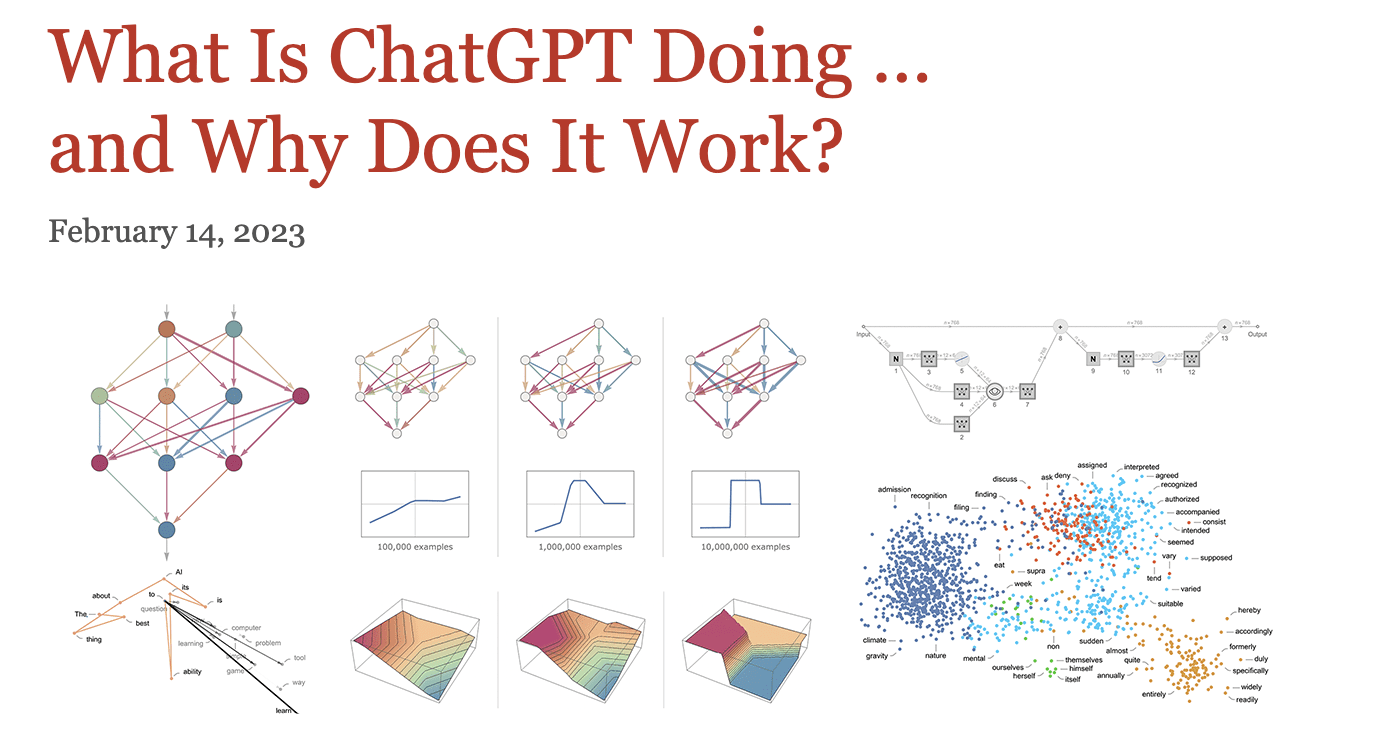
Image from Stephen Wolfram Writings
Yes, that's the title of the article by Wolfram.
Why am I recommending this? Because it is crucial to understand the absolute essentials of machine learning and how deep neural networks are related to human brains before learning about Transformers, LLMs, or even Generative AI.
It looks like a mini-book which is literature on its own, but take your time with the length of this resource.
In this article, I will share how to start reading it to make the concepts easier to grasp.
Understanding the ‘Model’ Is Crucial
Its key highlight is the focus on the ‘model’ part of “Large Language Models”, illustrated by an example of the time it takes the ball to reach the ground from each floor.
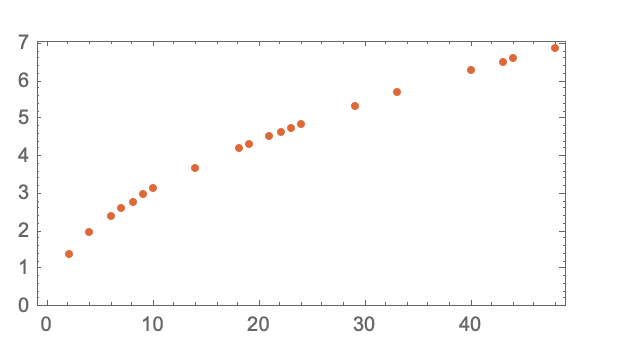
Image from Stephen Wolfram Writings
There are two ways to achieve this – repeating this exercise from each floor or building a model that could compute it.
In this example, there exists an underlying mathematical formulation that makes it easier to calculate, but how would one estimate such a phenomenon using a ‘model’?
The best bet would be to fit a straight line for estimating the variable of interest, in this case, time.
A more profound read into this section would explain that there is never a “model-less model”, which seamlessly takes you to the varied deep learning concepts.
The Core Of Deep Learning
You will learn that a model is a complex function that takes in certain variables as input and results in an output, say a number in digit recognition tasks.
The article goes from digit recognition to a typical cat vs. dog classifier to lucidly explain what features are picked by each layer, starting with the outline of the cat. Notably, the first few layers of a neural network pick out certain aspects of images, like the edges of objects.

Image by Freepik
Key Terminologies
In addition to explaining the role of multiple layers, multiple facets of deep learning algorithms are also explained, such as:
Architecture Of Neural Networks
It is a mix of art and science, says the post – “But mostly things have been discovered by trial and error, adding ideas and tricks that have progressively built significant lore about how to work with neural nets”.
Epochs
Epochs are an effective way to remind the model of a particular example to get it to “remember that example”
Since repeating the same example multiple times isn’t enough, it is important to show different variations of the examples to the neural net.
Weights (Parameters)
You must have heard that one of the LLMs has whopping 175B parameters. Well, that shows how the structure of the model varies based on how the knobs are adjusted.
Essentially, parameters are the “knobs you can turn” to fit the data. The post highlights that the actual learning process of neural networks is all about finding the right weights – “In the end, it’s all about determining what weights will best capture the training examples that have been given”
Generalization
The neural networks learn to “interpolate between the shown examples in a reasonable way”.
This generalization helps to predict unseen records by learning from multiple input-output examples.
Loss Function
But how do we know what is reasonable? It is defined by how far the output values are from the expected values, which are encapsulated in the loss function.
It gives us a “distance between the values we’ve got and the true values”. To reduce this distance, the weights are iteratively adjusted, but there must be a way to systemically reduce the weights in a direction that takes the shortest path.
Gradient Descent
Finding the steepest path to descent on a weight landscape is called gradient descent.
It is all about finding the correct weights that best represent the ground truth by navigating the weight landscape.
Backpropagation
Continue reading through the concept of backpropagation, which takes the loss function and works backward to progressively find weights to minimize the associated loss.
Hyperparameters
In addition to weights (aka the parameters), there are hyperparameters that include different choices of the loss function, loss minimization, or even choosing how big a “batch” of examples should be.
Neural Networks For Complex Problems
The use of neural networks for complex problems is widely discussed. Still, the logic underneath such an assumption was unclear until this post which explains how multiple weight variables in a high-dimensional space enable various directions that can lead to the minimum.
Now, compare this with fewer variables, which implies the possibility of getting stuck in a local minimum with no direction to get out.
Conclusion
With this read, we have covered a lot of ground, from understanding the model and how human brains work to taking it to neural nets, their design, and associated terminologies.
With this read, we have covered a lot of ground, from understanding the model and how human brains work to taking it to neural nets, their design, and associated terminologies.
Stay tuned for a follow-up post on how to build upon this knowledge to understand how chatgpt works.
Vidhi Chugh is an AI strategist and a digital transformation leader working at the intersection of product, sciences, and engineering to build scalable machine learning systems. She is an award-winning innovation leader, an author, and an international speaker. She is on a mission to democratize machine learning and break the jargon for everyone to be a part of this transformation.