Visual ChatGPT: Microsoft Combine ChatGPT and VFMs
Microsoft announces Visual ChatGPT for talking, drawing, and editing with visual foundation models.

Image by Author
Just when we thought we digested enough news about Large Language Models (LLMs), the Microsoft Research Asia team brought us Visual ChatGPT. Visual ChatGPT overcomes the current limitations in ChatGPT of not being able to process visual information as it’s trained with a single language modality.
What is Visual ChatGPT?
Visual ChatGPT is a system that incorporates Visual Foundation Models (VFM) to help ChatGPT better understand, generate and edit visual information. VFM have the ability to specify input-output formats, convert visual information to language format, and handle VFM histories, priorities, and conflicts.
Therefore, Visual ChatGPT is an AI model that acts as a bridge between the limitations of ChatGPT and allowing users to communicate via chat and generate visuals.
Limitations of ChatGPT
ChatGPT has been in the majority of peoples conversation in the past few weeks and months. However, due to its linguistic training capabilities, it does not allow for the processing and generating of images.
Whereas you have visual foundation models such as Visual Transformers and Steady Diffusion which have amazing visual capabilities. This is where the combination of language and image models have created Visual ChatGPT.
What are Visual Foundation Models?
Visual Foundation Models is used to group fundamental algorithms that are used in computer vision. They take standard computer vision skills and transfer them onto AI applications to deal with more complex tasks.
The Prompt Manager in Visual ChatGPT consists of 22 VFMs, which includes Text-to-Image, ControlNet, Edge-To-Image, and more. This helps ChatGPT to convert all visual signals of an image into language for ChatGPT to better comprehend. So how does Visual ChatGPT work?
How Does Visual ChatGPT Work?
Visual ChatGPT is made up of different components to help the Large Language Model ChatGPT understand visuals.
Architectural Components of Visual ChatGPT
- User Query: This is where the user will submit their query
- Prompt Manager: This converts the users visual queries into language format, so that the ChatGPT model can understand.
- Visual Foundation Models: This combines a variety of VFMs, such as BLIP (Bootstrapping Language-Image Pre-training), Stable Diffusion, ControlNet, Pix2Pix, and more.
- System Principle: This provides the basic rules and requirements for Visual ChatGPT.
- History of Dialogue: This is the first point of interaction and conversation that the system has with the user.
- History of Reasoning: This uses previous reasoning that the different VFMs have had in the past to solve complex queries.
- Intermediate Answer: With the use of VFMs, the model will attempt to output several intermediate answers that have logical understating.
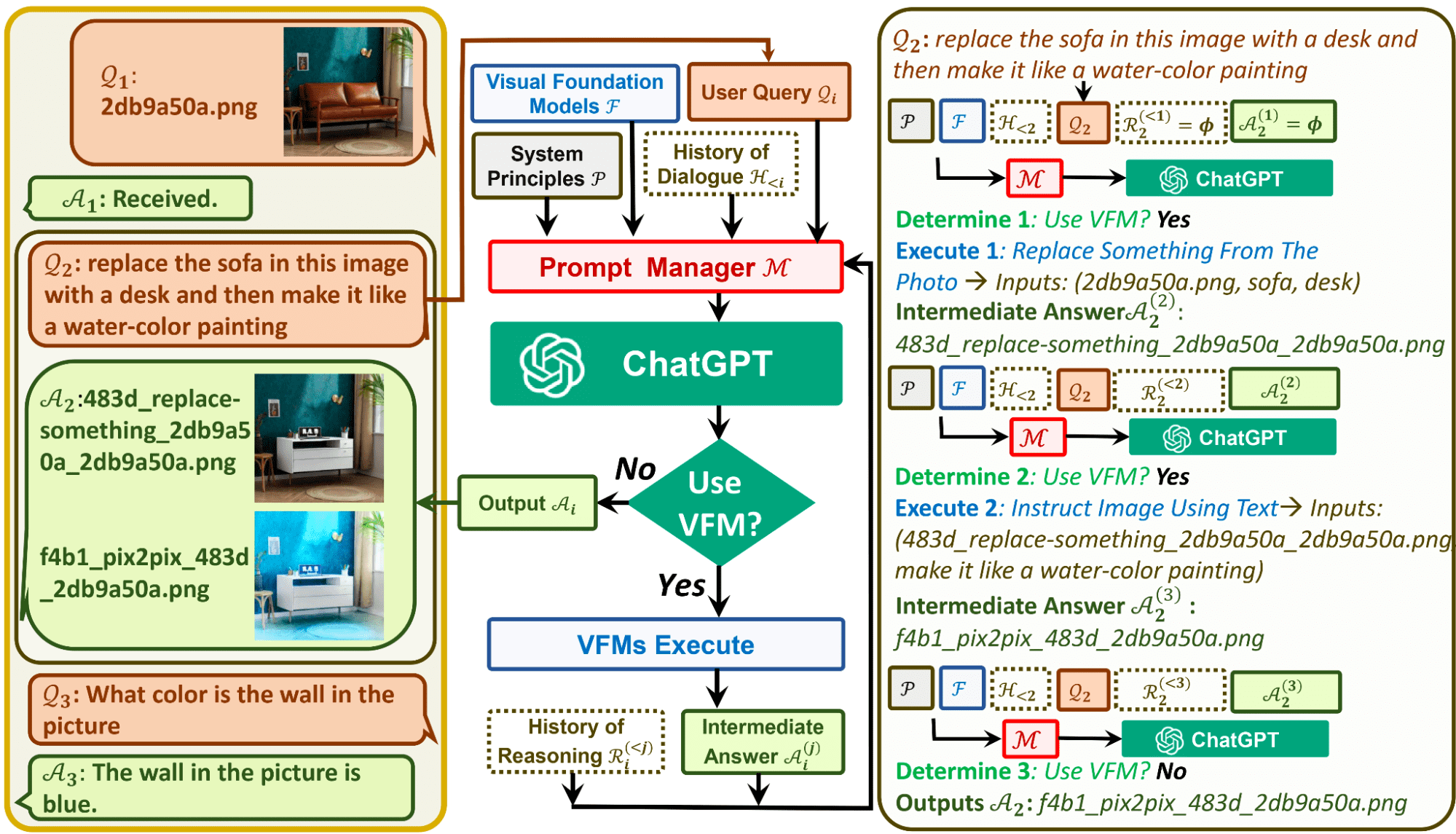
Image by Microsoft GitHub
More About the Prompt Manager
Some of you may be thinking that this is a forced workaround for ChatGPT to deal with visuals, as it still converts all visual signals of an image into language. When uploading images, the Prompt Manager synthesizes an internal chat history that includes information such as file name so that ChatGPT can better understand what the query is referring to.
For example, the name of an inputted image by the user will act as an operation history and then the prompt manager will assist the model to go through ‘Reasoning Format’ to figure out what needs to be done with the image. You can consider this as the model's inner thoughts before ChatGPT selects the correct VFM operation.
In the image below, you can see how the Prompt Manager initiates the rules for Visual ChatGPT:
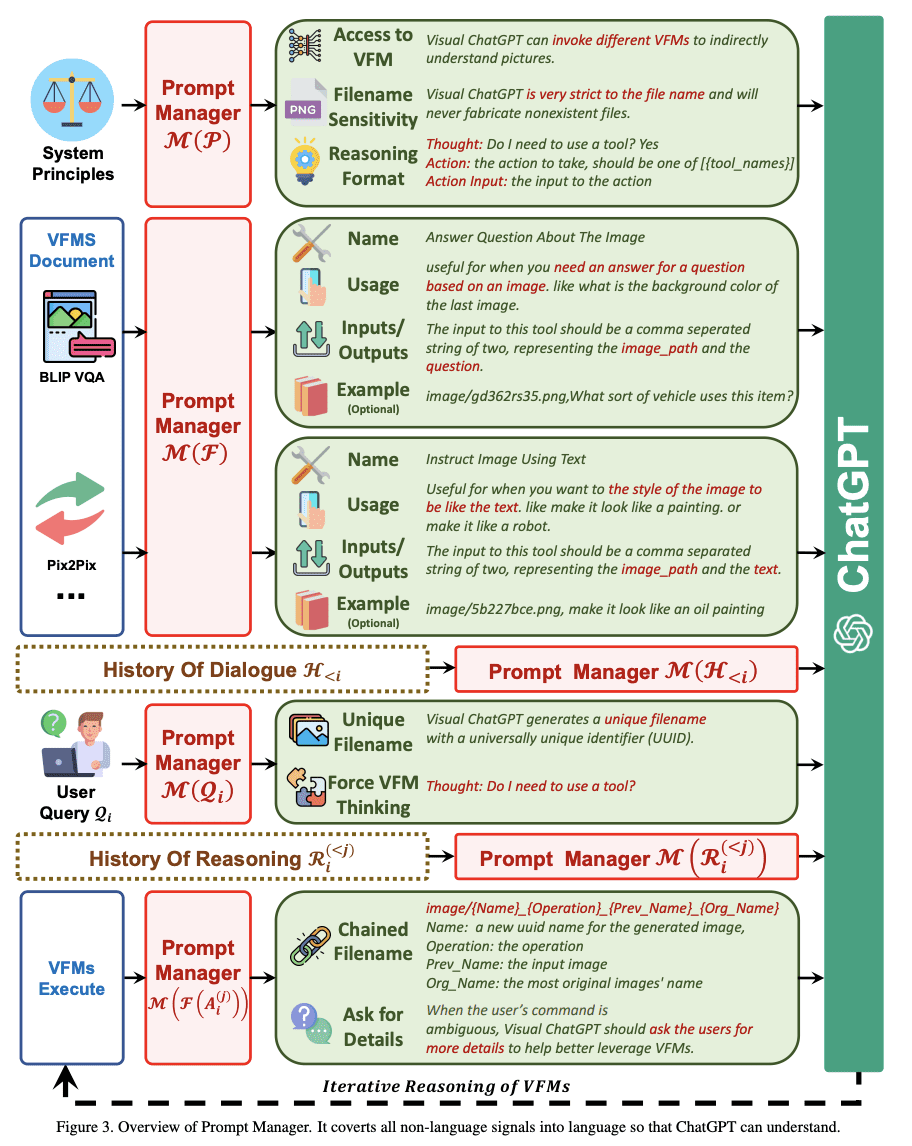
Image by Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
Get Started with Visual ChatGPT
To kickstart your Visual ChatGPT journey, you will need to run the Visual ChatGPT demo first:
# create a new environment
conda create -n visgpt python=3.8
# activate the new environment
conda activate visgpt
# prepare the basic environments
pip install -r requirement.txt
# download the visual foundation models
bash download.sh
# prepare your private openAI private key
export OPENAI_API_KEY={Your_Private_Openai_Key}
# create a folder to save images
mkdir ./image
# Start Visual ChatGPT !
python visual_chatgpt.py
You can also learn more on Microsoft's Visual ChatGPT GitHub. Ensure you look at their GPU memory usage on each of the Visual Foundation Models.
Use Cases of Visual ChatGPT
So what can Visual ChatGPT do?
Image Generation
You can ask Visual ChatGPT to create an image from scratch, providing a description. Your image will be generated within seconds, depending on the computing power available. Its Synthetic Image Generation using text data is based on Stable Diffusion.
Changing Image Background
Again, using stable diffusion, Visual ChatGPT can change the background of your inputted image. The user can provide the assistant with any description on what they want the background to be changed to, and the stable diffusion model will inpaint the background of the image.
Changing Colour Image and other Effects
You will also be able to change the color of your image and apply effects, based on providing the application with description. Visual ChatGPT will use a variety of pretrained models and OpenCV, to change image colors, highlight edges of an image, and more.
Make Changes to an Image
Visual ChatGPT allows you to remove or replace aspects of your image by editing and modifying objects in the image with directed text description to the application. However, it is good to note that this feature requires more computing power.
Limitations of Visual ChatGPT
As we know, there will always be some form of imperfections that organizations will need to work on to improve their services.
Combination of Computer Vision and Large Language Models
Visual ChatGPT is heavily reliant on ChatGPT and VFMs, therefore, the accuracy and reliability of these individual aspects influence the performance of Visual ChatGPT. The combination of using a Large Language Model and Computer Vision requires a high amount of prompt engineering, and can be difficult to achieve proficient performance.
Privacy and Security
Visual ChatGPT has the ability to easily plug and unplug VFMs, which may be a concern to some users about the security and privacy concerns. Microsoft will need to look more into how sensitive data is not compromised.
Self Correction Module
One of the limitations that the researchers of Visual ChatGPT came across was the inconsistent generated outcomes due to the failure of VFMs and diversity of the prompts. Therefore, they concluded that they will need to work on a self-correction module which will ensure that the outputs generated are in line with what the user has requested, and be able to make necessary corrections.
High Amount of GPU Required
In order to benefit from Visual ChatGPT and make use of the 22 VFMs, you will need a high amount of GPU RAM, for example A100. Depending on the task at hand, ensure that you understand how much GPU is required to effectively complete the task.
Wrapping Up
Visual ChatGPT still has its limitations, however this is a major breakthrough in the use of Large Language Models and Computer Vision simultaneously. If you would like to learn more about Visual ChatGPT, have a read of this paper: Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
Is Visual ChatGPT similar to ChatGPT4? If you’ve tried the two, what’s your opinion? Drop a comment below!
Nisha Arya is a Data Scientist, Freelance Technical Writer and Community Manager at KDnuggets. She is particularly interested in providing Data Science career advice or tutorials and theory based knowledge around Data Science. She also wishes to explore the different ways Artificial Intelligence is/can benefit the longevity of human life. A keen learner, seeking to broaden her tech knowledge and writing skills, whilst helping guide others.