Essential Math for Data Science: Visual Introduction to Singular Value Decomposition
This article will cover singular value decomposition (SVD), which is a major topic of linear algebra, data science, and machine learning.
In this article, you’ll learn about Singular value decomposition (SVD), which is a major topic of linear algebra, data science, and machine learning. It is for instance used to calculate the Principal Component Analysis (PCA). You’ll need some understanding of linear algebra basics (feel free to check the previous article and the book Essential Math for Data Science.
You can only apply eigendecomposition to square matrices because it uses a single change of basis matrix, which implies that the initial vector and the transformed vector are relative to the same basis. You go to another basis with  to do the transformation, and you come back to the initial basis with .
to do the transformation, and you come back to the initial basis with .
As eigendecomposition, the goal of singular value decomposition (SVD) is to decompose a matrix into simpler components: orthogonal and diagonal matrices.
You also saw that you can consider matrices as linear transformations. The decomposition of a matrix corresponds to the decomposition of the transformation into multiple sub-transformations. In the case of the SVD, the transformation is converted to three simpler transformations.
You’ll see here three examples: one in two dimensions, one comparing the transformations of the SVD and the eigendecomposition, and one in three dimensions.
Two-Dimensional Example
You’ll see the action of these transformations using a custom function matrix_2d_effect(). This function plots the unit circle (you can find more details about the unit circle in Chapter 05 of Essential Math for Data Science). and the basis vectors transformed by a matrix.
You can find the function here.
To represent the unit circle and the basis vectors before the transformation, let’s use this function using the identity matrix:
I = np.array([
[1, 0],
[0, 1]
])
matrix_2d_effect(I)
# [...] Add labels
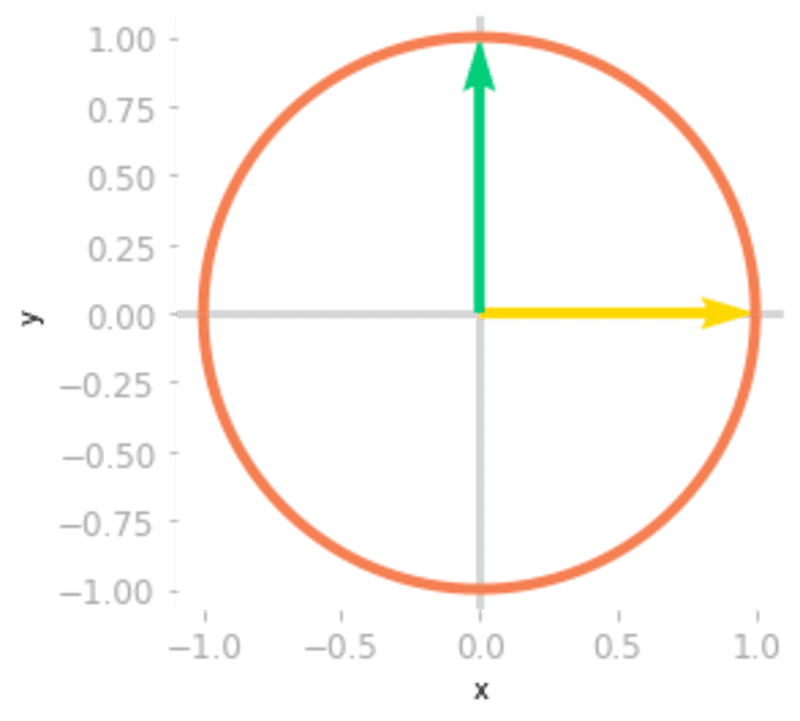
Figure 0: The unit circle and the basis vectors
Let’s now use the function to see the effect of the following matrix .
It will plot the unit circle and the basis vectors transformed by the matrix:
A = np.array([
[2, 5],
[7, 3]
])
matrix_2d_effect(A)
# [...] Add labels
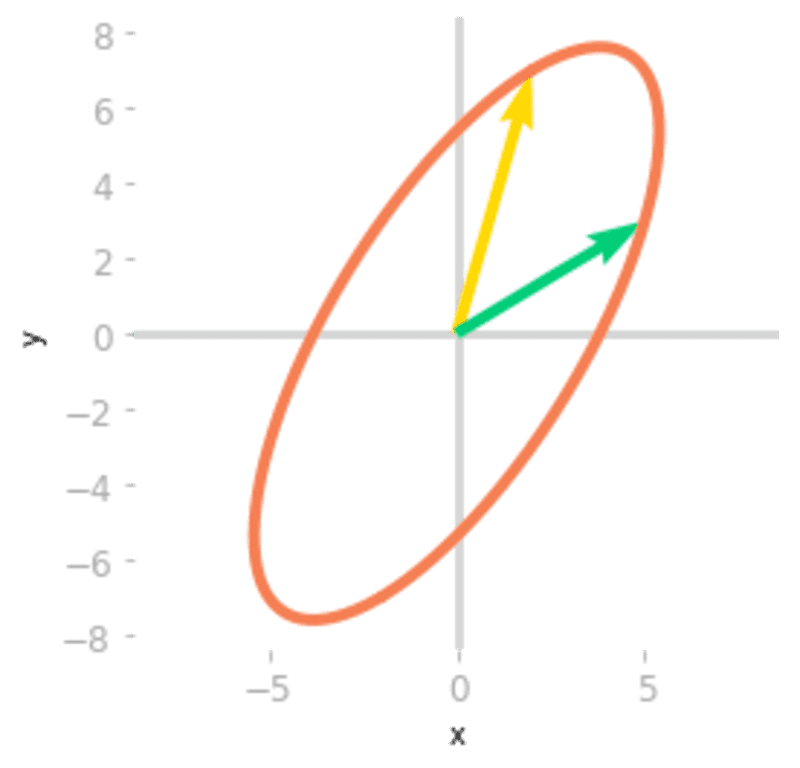
Figure 1: Effect of the matrix AA on the unit circle and the basis vectors.
Figure 1 illustrates the effect of on your two-dimensional space. Let’s compare this to the sub-transformations associated with the matrices of the SVD.
You can calculate the SVD of using Numpy:
U, Sigma, V_transpose = np.linalg.svd(A)
Remember that the matrices , , and contain respectively the left singular vectors, the singular values, and the right singular vectors. You can consider as a first change of basis matrix, as the linear transformation in this new basis (this transformation should be a simple scaling since is diagonal), and UU another change of basis matrix. You can see in Chapter 10 of Essential Math for Data Science that the SVD constraints both change of basis matrices and to be orthogonal, meaning that the transformations will be simple rotations.
To summarize, the transformation corresponding to the matrix is decomposed into a rotation (or a reflection, or a rotoreflection), a scaling, and another rotation (or a reflection, or a rotoreflection).
Let’s see the effect of each matrix successively:
matrix_2d_effect(V_transpose)
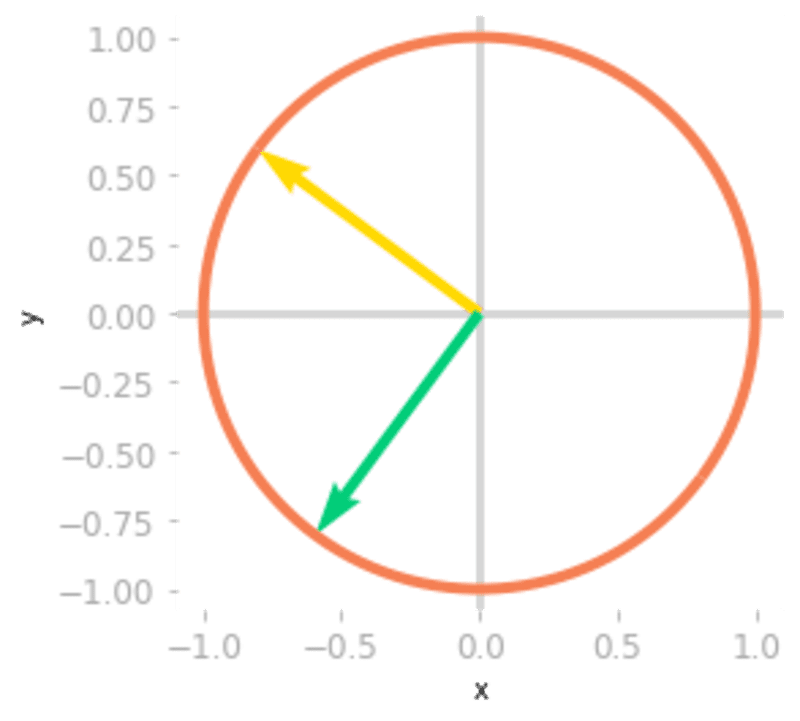
Figure 2: Effect of the matrix
on the unit circle and the basis vectors.You can see in Figure 2 that unit circle and the basis vectors have been rotated by the matrix .
matrix_2d_effect(np.diag(Sigma) @ V_transpose)
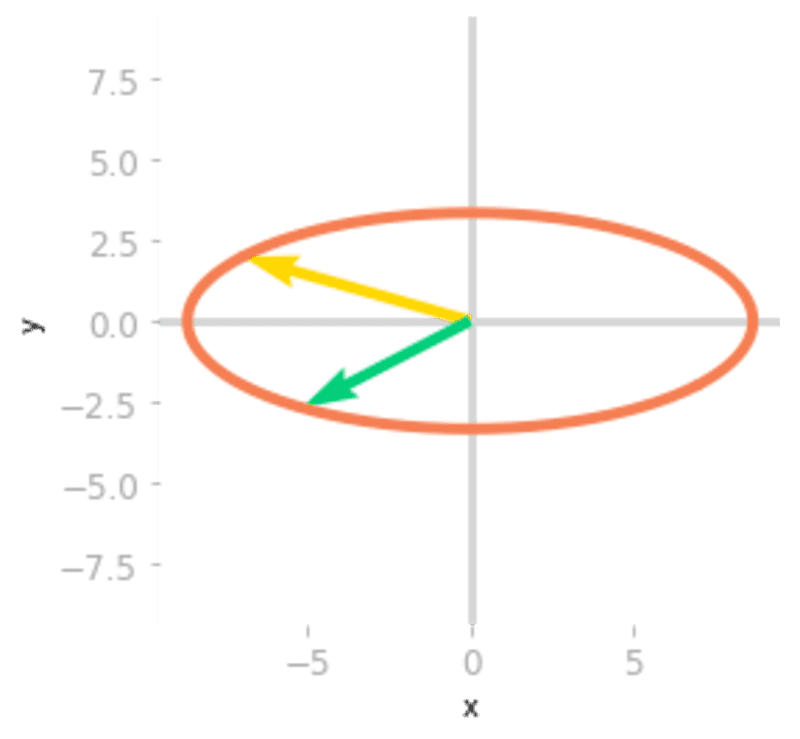
Figure 3: Effect of the matrices
and .Then, Figure 3 shows that the effect of is a scaling of the unit circle and the basis vectors.
matrix_2d_effect(U @ np.diag(Sigma) @ V_transpose)
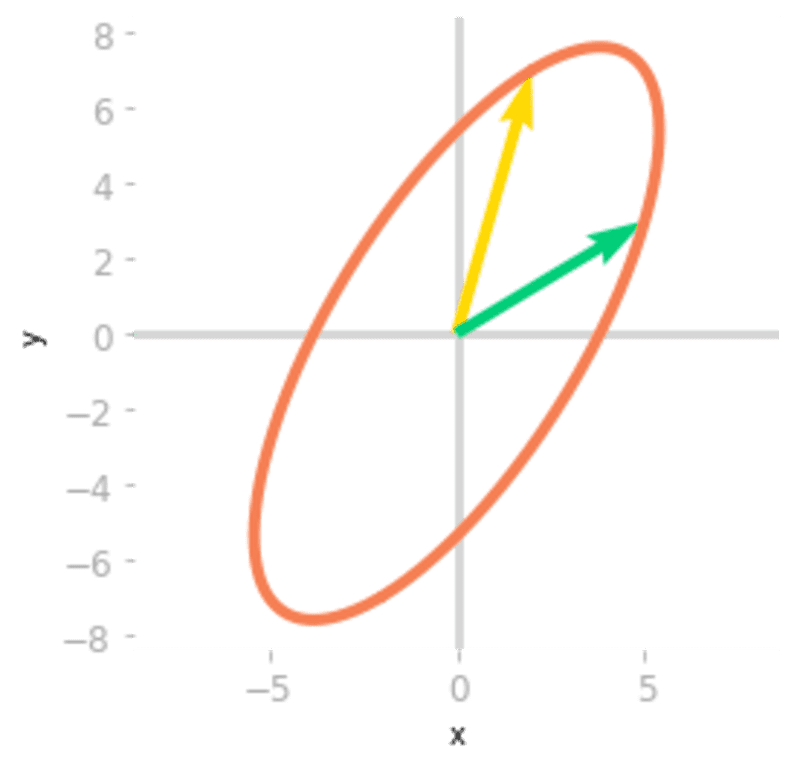
Figure 4: Effect of the matrices
, and Finally, a third rotation is applied by . You can see in Figure 4 that the transformation is the same as the one associated with the matrix . You have decomposed the transformation into a rotation, a scaling, and a rotoreflection (look at the basis vectors: a reflection has been done because the yellow vector is on the left of the green vector, which was not the case initially).
Comparison with Eigendecomposition
Since the matrix was square, you can compare this decomposition with eigendecomposition and use the same type of visualization. You’ll get insights about the difference between the two methods.
Remember from Chapter 09 of Essential Math for Data Science that the eigendecomposition of the matrix AA is given by:
Let’s calculate the matrices and (pronounced “capital lambda”) with Numpy:
lambd, Q = np.linalg.eig(A)
Note that, since the matrix is not symmetric, its eigenvectors are not orthogonal (their dot product is not equal to zero):
Q[:, 0] @ Q[:, 1]
-0.16609095970747995
Let’s see the effect of on the basis vectors and the unit circle:
ax = matrix_2d_effect(np.linalg.inv(Q))
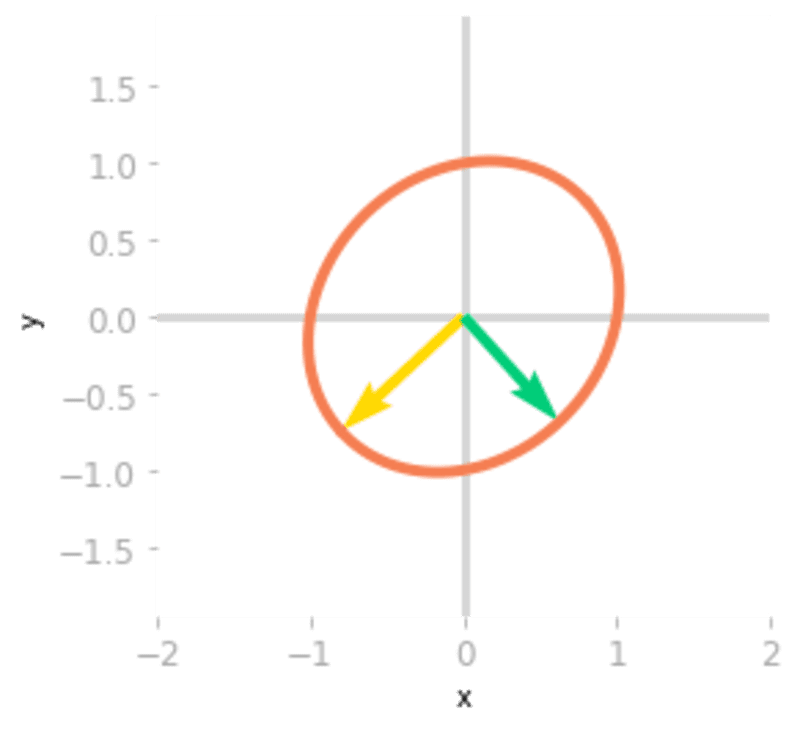
Figure 5: Effect of the matrix
.You can see in Figure 5 that rotates and scales the unit circle and the basis vectors. The transformation of a non-orthogonal matrix is not a simple rotation.
The next step is to apply .
ax = matrix_2d_effect(np.diag(lambd) @ np.linalg.inv(Q))
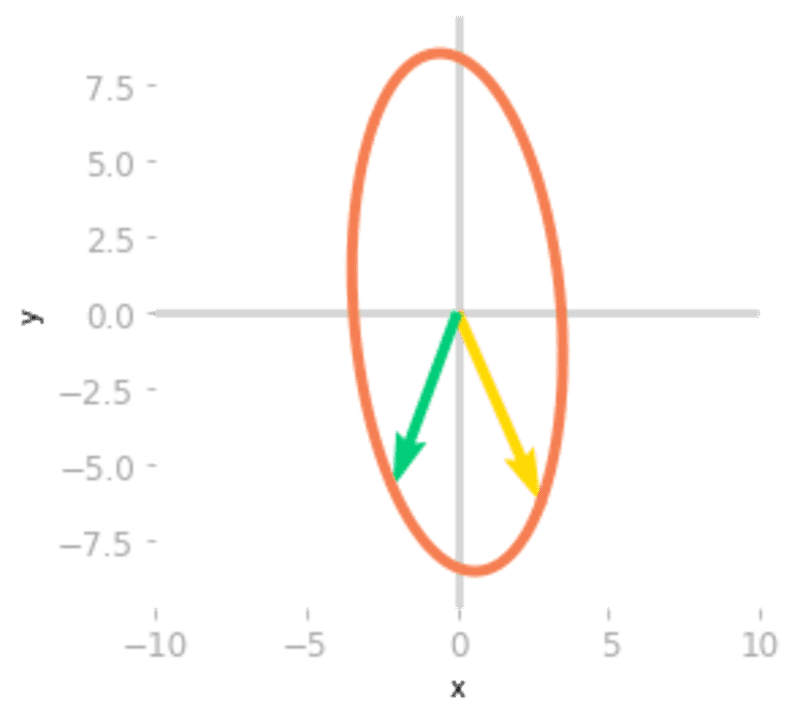
Figure 6: Effect of the matrix
and The effect of , as shown in Figure 6, is a stretching and a reflection through the y-axis (the yellow vector is now on the right of the green vector).
ax = matrix_2d_effect(Q @ np.diag(lambd) @ np.linalg.inv(Q))
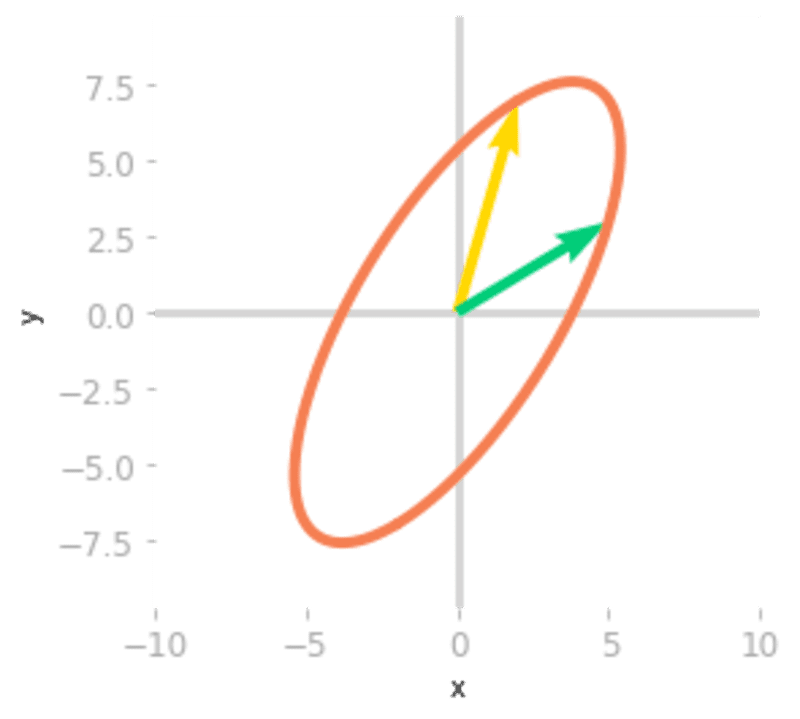
Figure 7: Effect of the matrix
, and .The last transformation shown in Figure 7 corresponds to the change of basis back to the initial one. You can see that it leads to the same result as the transformation associated with : both matrices and are similar: they correspond to the same transformation in different bases.
It highlights the differences between eigendecomposition and SVD. With SVD, you have three different transformations, but two of them are only rotation. With eigendecomposition, there are only two different matrices, but the transformation associated with is not necessarily a simple rotation (it is only the case when is symmetric).
Three-Dimensional Example
Since the SVD can be used with non square matrices, it is interesting to see how the transformations are decomposed in this case.
First, non square matrices map two spaces that have a different number of dimensions. Keep in mind that by matrices map an nn-dimensional space with an -dimensional space.
Let’s take the example of a 3 by 2 matrix, mapping a two-dimensional space to a three-dimensional space. This means that input vectors are two-dimensional and output vectors three-dimensional. Take the matrix :
A = np.array([
[2, 5],
[1, 6],
[7, 3]
])
To visualize the effect of , you’ll use again the unit circle in two dimensions and calculate the output of the transformation for some points on this circle. Each point is considered as an input vector and you can observe the effect of on each of these vectors. The function matrix_3_by_2_effect() can be found here.
ax = matrix_3_by_2_effect(A)
# [...] Add styles axes, limits etc.
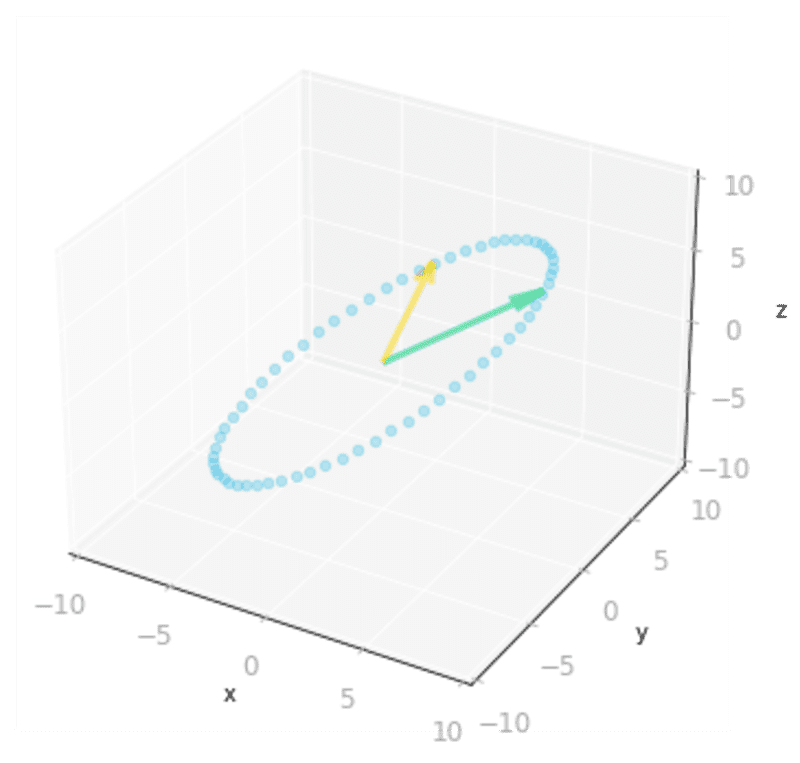
Figure 8: Effect of the matrix
: it transforms vectors on the unit circle and the basis vectors from a two-dimensional space to a three-dimensional space.As represented in Figure 8, the two-dimensional unit circle is transformed into a three-dimensional ellipse.
What you can note is that the output vectors land all on a two-dimensional plane. This is because the rank of is two (more details about the rank of a matrix in Section 7.6 of of Essential Math for Data Science).
Now that you know the output of the transformation by , let’s calculate the SVD of and see the effects of the different matrices, as you did with the two-dimensional example.
U, Sigma, V_transpose = np.linalg.svd(A)
The shape of the left singular vectors () is mm by mm and the shape of the right singular vectors () is by . There are two singular values in the matrix .
The transformation associated with is decomposed into a first rotation in (associated with , in the example, ), a scaling going from to (in the example, from to ), and a rotation in the output space IRmIRm (in the example, ).
Let’s start to inspect the effect of on the unit circle. You stay in two dimensions at this step:
matrix_2d_effect(V_transpose)
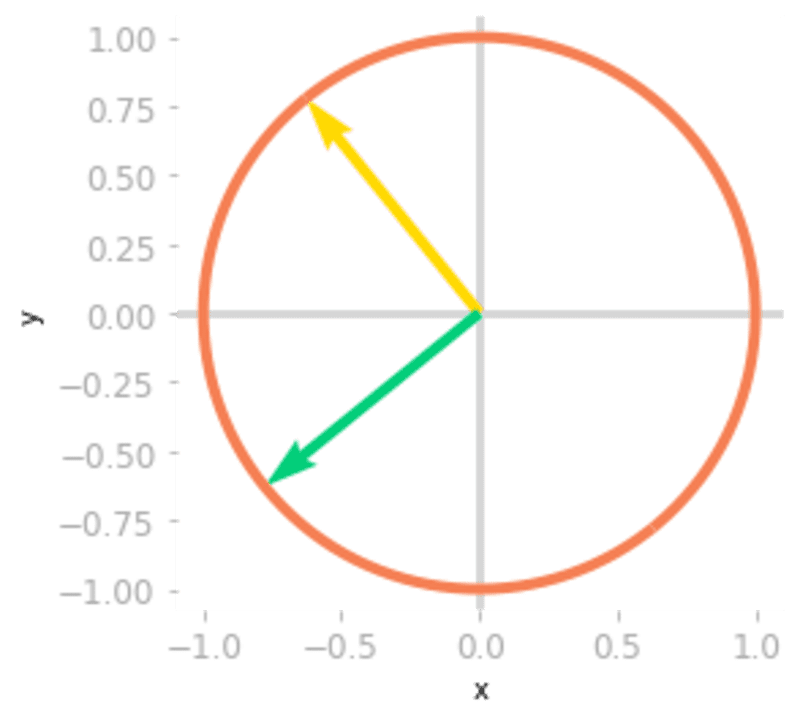
Figure 9: Effect of the matrix
: at this step, you’re still in a two-dimensional space.Then, you need to reshape because the function np.linalg.svd() gives a one-dimensional array containing the singular values. You want a matrix with the same shape as : a 3 by 2 matrix to go from 2D to 3D. This matrix contains the singular values as the diagonal, the other values are zero.
Let’s create this matrix:
Sigma_full = np.zeros((A.shape[0], A.shape[1]))
Sigma_full[:A.shape[1], :A.shape[1]] = np.diag(Sigma)
Sigma_full
array([[9.99274669, 0. ],
[0. , 4.91375758],
[0. , 0. ]])
You can now add the transformation of to see the result in 3D in Figure 10:
ax = matrix_3_by_2_effect(Sigma_full @ V_transpose)
# [...] Add styles axes, limits etc.
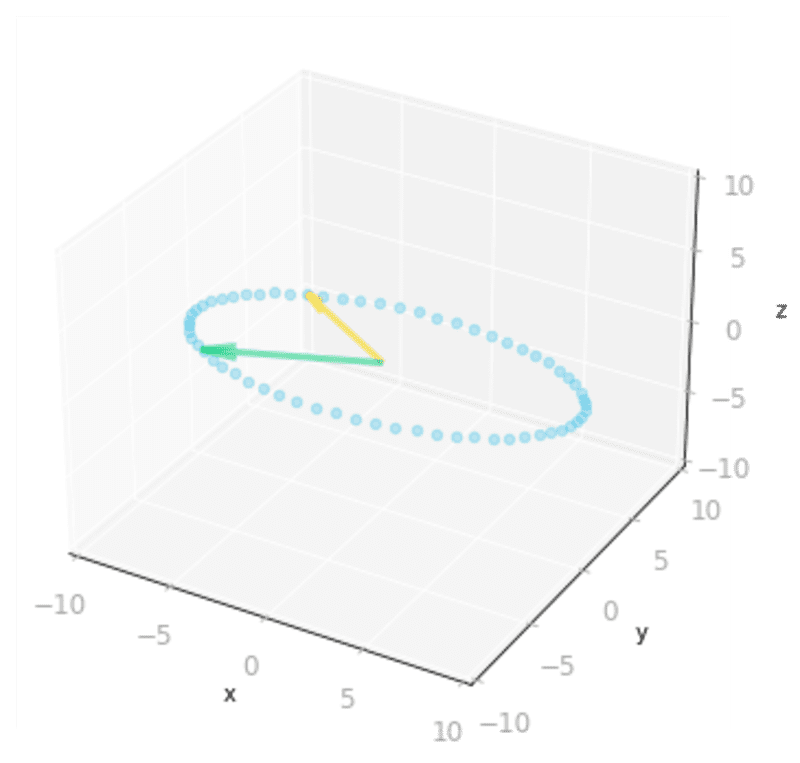
Figure 10: Effect of the matrices
and : since is a three by two matrix, it transforms two-dimensional vectors into three-dimensional vectors.Finally, you need to operate the last change of basis. You stay in 3D because the matrix is a 3 by 3 matrix.
ax = matrix_3_by_2_effect(U @ Sigma_full @ V_transpose)
# [...] Add styles axes, limits etc.
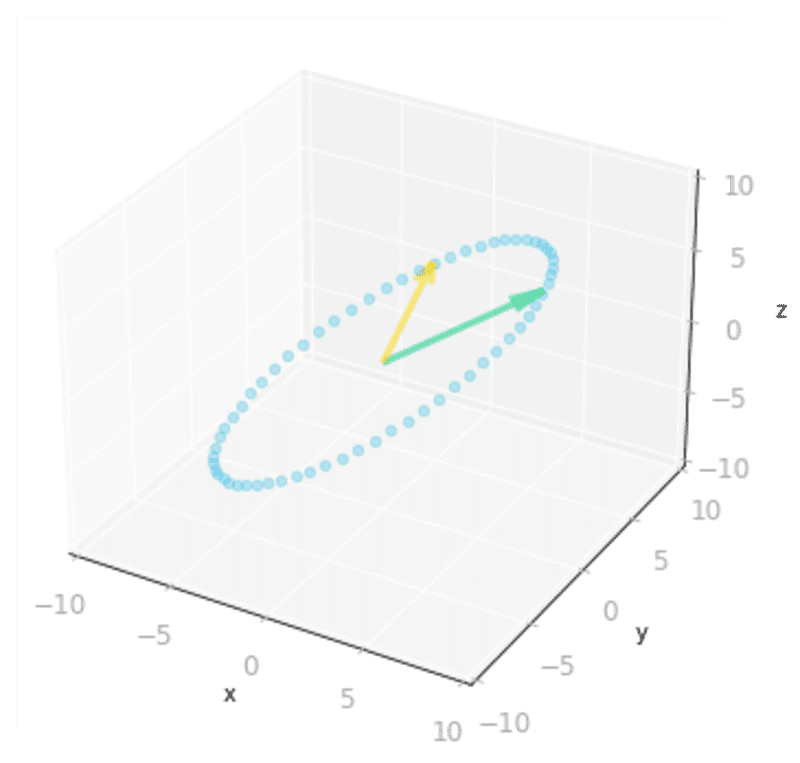
Figure 11: Effect of the three matrices
, and : the transformation is from a three-dimensional space to a three-dimensional space.You can see in Figure 11 that the result is identical to the transformation associated with the matrix .
Summary
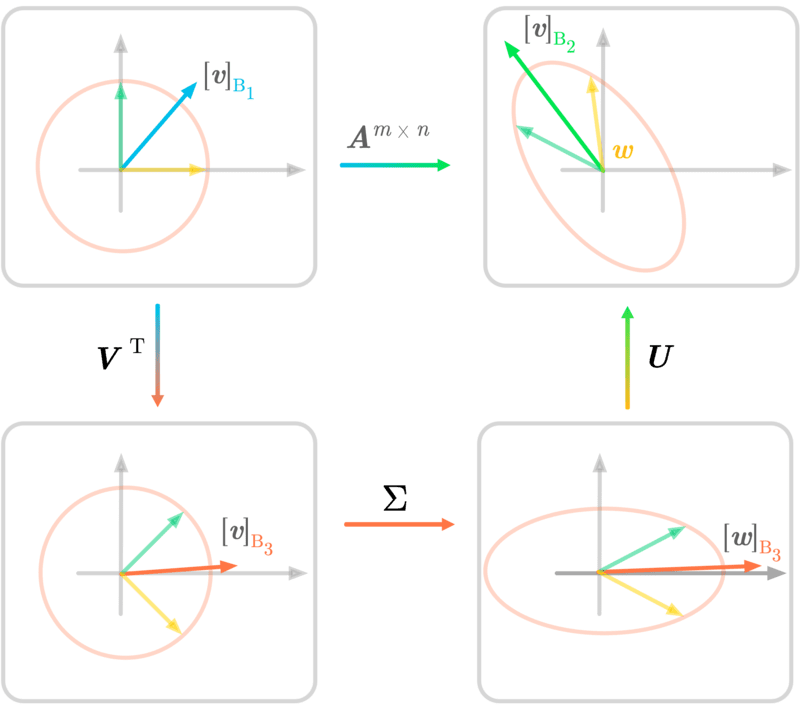
Figure 12: SVD in two dimensions.
Figure 12 summarizes the SVD decomposition of a matrix AA into three matrices. The transformation associated with is done by the three sub-transformations. The notation is the same as in Figure 12 and illustrates the geometric perspective of the SVD.
Singular Value Decomposition can be used for instance to find transformations that approximates well a matrix (see Low-Rank Matrix Approximation in Section 10.4 of of Essential Math for Data Science).
Original. Reposted with permission.
Hadrien Jean is a machine learning scientist. He owns a Ph.D in cognitive science from the Ecole Normale Superieure, Paris, where he did research on auditory perception using behavioral and electrophysiological data. He previously worked in industry where he built deep learning pipelines for speech processing. At the corner of data science and environment, he works on projects about biodiversity assessement using deep learning applied to audio recordings. He also periodically creates content and teaches at Le Wagon (data science Bootcamp), and writes articles in his blog (hadrienj.github.io).