Introducing Objectiv: Open-source product analytics infrastructure
Collect validated user behavior data that’s ready to model on without prepwork. Take models built on one dataset and deploy & run them on another.

Designed for advanced modeling and ML
Objectiv is open-source product analytics infrastructure built specifically for data teams that want to go beyond the scope of their SaaS analytics tools. It is designed to collect validated, high quality user behavior data that's structured with effective modeling in mind. As a result, it is well-suited for advanced analysis projects & machine learning.
Model on the raw data without prepwork
Objectiv’s tracker validates incoming data against an open analytics taxonomy. This results in a raw dataset that is super clean, well-organized and follows a generic but strict event structure. You can start modeling straight away without any prepwork.
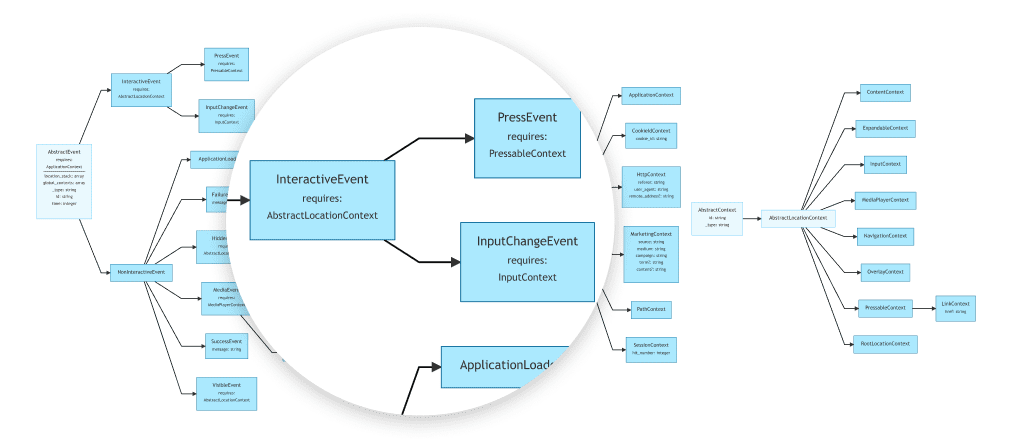
Build on the knowledge and practises of others
The design of the open analytics taxonomy is based on the knowledge and practises of over 50 data teams from different companies. It has been tested thoroughly to ensure your dataset covers a wide range of advanced analytics & ML use cases, so you can stop worrying about data coverage for any analyses that you may want to do in the future.
Learn more about the open taxonomy here
Build models on one dataset, deploy & run it on another
Datasets collected with Objectiv carry a generic event structure. As a result, all models can be reused between projects, platforms, data platforms and even companies. That user segmentation model you've developed for your Android app? You can share that with the team responsible for the iOS app or web app, and they can deploy and run it without making changes.
Create pandas-like models that run on your full dataset
Objectiv includes a modeling library that enables you to build models with Pandas-like operations that run on your full SQL dataset. This means you can build advanced models without composing complicated SQL queries and run them on production data without having to manually port them first.
It comes with the open model hub: a toolkit that contains functions and models that can be combined to quickly build advanced compound models with little effort.
Get involved
Join our growing community on Slack, or check out the codebase on GitHub.