Data Science Project Infrastructure: How To Create It
The intension for most data science projects is to build something that people use. Creating something purposeful requires a solid infrastructure and processes that keeps problem-solving front-and-center for your audience.

The main starting point for any data science project is a business or any other real-life problem. That’s the single most important thing you need to have in mind when you’re deciding on how your data science project should look like.
It’s the same when you’re building the data science infrastructure for your project. You’re building your project and its infrastructure for other people to use it. Because of that, I will not go too much into technical details about the infrastructure. What I’ll give you here are recommendations that you should have in mind if you want to build a purposeful data science project. That also includes some technology suggestions, of course.
Following those recommendations will keep the problem-solving in the center of your project like it should be. They will also help you build the one and only data science project you’ll need for showcasing your skills.
Four Steps to a Solid Data Science Project Infrastructure
Building a solid data science infrastructure is not easy, especially if you’re not too experienced. But to remain on the safe side, use this checklist to make sure you’re on a good path:
- Get real data using APIs and other technologies
- Use (cloud) databases to store data
- Build a model
- Deploy your model
By following these steps, you’ll generally follow what is called an OSEMN framework. It’s a framework outlining how the process your data science project should go through:

SOURCE: TOWARDS DATA SCIENCE
Now I’ll go into detail and explain every point.
Get Real Data Using APIs and Other Technologies
You’re trying to solve real problems with your project, right? It’s only natural you do that by using real data. By that, I mean data that users produce, the data that is updated in real-time, such as streaming data. If you use such data, your project becomes less theoretical. You’re working with the data that is relevant today, that needs to be updated constantly, which also tests your skills in handling such data. This is where the challenge lies, not in practicing on some historical data-set even though that has its own purpose too.
The main question is where and how you get the real data. You get it by using the APIs. To get the real data you need, you must know how to use, configure, and set up APIs. There’s a simple way to help you visualise what the APIs are and what they do:
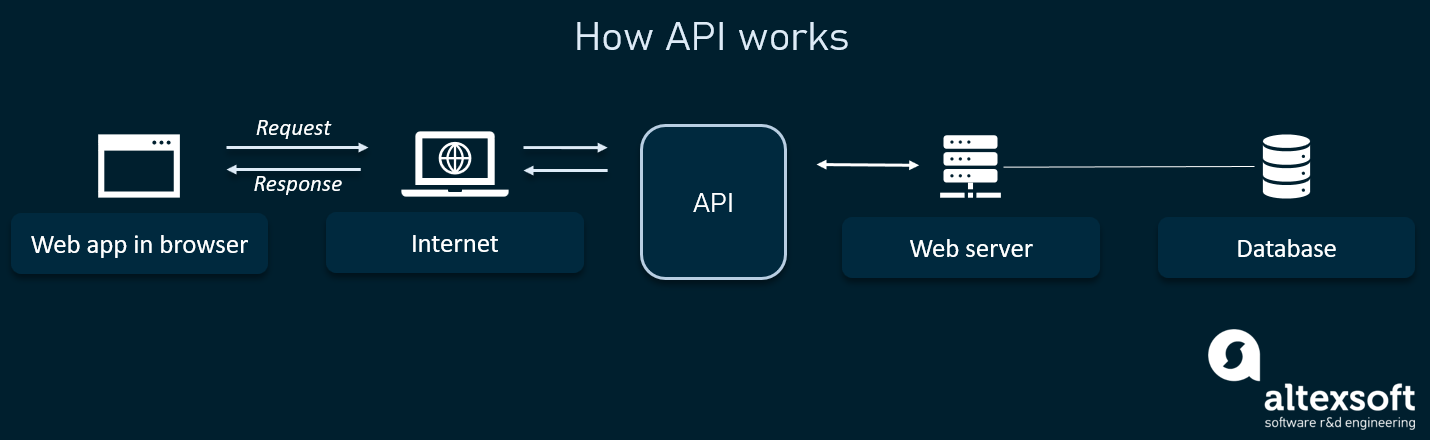
SOURCE: ALTEXSOFT
Some popular APIs are:
Using such technologies will allow you to get data that will include:
- Real-time updates
- Data and timestamps for each record
- Geolocations
- Numbers and text data
Knowing how to use APIs is one of the highly recommended skills in the data science industry. First of all, building a machine-learning model with static data doesn’t make sense. That’s why you’ll (probably) have to know how to use APIs. They’ll allow you to automate the data updates. If you use APIs, you can avoid creating an integration layer since APIs are also a platform for communication between the various systems. If you master APIs, you’ll also be able to deploy your model later, even build the application(s) that will use this actual data.
This Springboard article explains nicely what the APIs are and which ones are recommended for a data scientist. With every recommendation, there are also links to API documentation and tutorial and some online resources to practice with APIs.
When using the APIs, you’ll also need to use other technologies such as:
- Libraries that help you make API calls
- Data structures like JSON and dictionaries to collect and save data from API
Once you get the data, you need to store it somewhere, right? That’s another important step in building an infrastructure.
Use Cloud Databases to Store Data
Since you’re working with real-time data, it’s advisable that you store the data. Otherwise, you’ll have to constantly pull all the data from APIs, including the data you already have and new data that appeared in the meantime.
When you use databases to store your data, you’ll only have to pull the new data, clean it and append it to the already existing clean data in your database. One of the most popular cloud databases are:
But why should you specifically use cloud databases? Suppose you’re working on your own and want to make some relatively serious project on a considerable amount of automatically updated real-time data. In that case, the cloud databases will allow you to have a relatively cheap way to store such data with virtually endless storage capacity. For example, Amazon Web Services and Google Cloud also offer the possibility of running machine learning algorithms. That’s not something you’d be able to do if you used the in-house data storing. And you also won’t have to worry about the backups and availability of data.
If you’re working for some company, especially if it’s some bigger company generating huge amounts of data, the chances are you’ll have to be fluent at (or at least wanting to learn) cloud computing. The companies are moving to the cloud databases for precisely the exact reason why you should do that too. Even if you don’t work somewhere as a data scientist yet, it doesn’t mean you couldn’t. Take a look at this guide on how to get a data science job; I’m sure it’ll get you what you want.
There’s a great article on Pupuweb that you should read if you want to learn about the basic characteristics of cloud databases, their providers, advantages, and disadvantages, so you can decide which option is best for you.
If you don’t want to learn cloud databases on your own, maybe it’s good to try an online course. I think this Coursera course could be a good starting point. It’s a Duke University course, and it’s free. If you take the course, you’ll be working with Amazon Web Services, Azure, and Google Cloud Platform.
Build a Model
Once you have the first two infrastructure elements in place, it’s time to build a model. When building a regression or a machine-learning model, you, again, need to have in mind that the model should solve a real-life problem. To build such a model, you should ask yourself the following questions:
- What am I trying to accomplish with this model? Why did I choose this instead of some other model?
- How do I clean the data, and why that way?
- What validation tests will I perform on the data to make it suitable for the model?
- What are the model assumptions, and how will I validate them?
- How should I optimize the model? What are the trade-off decisions I should make?
- How should I implement tests/controls?
- What is the underlying math in the model, and how it works?
The main tool that’ll make you ask good questions is the experience. However, to gain experience, you need to build some models. And to build them, you’ll need some more technical tools to help you with that. The major categories of tools for building machine learning models are:
- Machine Learning Toolkits
- Machine Learning Platforms
- Analytics Solutions
- Data Science Notebooks
- Cloud-native Machine Learning as a Service (MLaaS)
For a start, I recommend this Forbes article to get familiar with what every category offers.
If you have Python programming, mathematics, and statistics knowledge, along with some Machine Learning basics, some courses could further your model-building skills. For example, there’s a free Udacity course provided by AT&T, focusing precisely on the questions essential for building a good model.
It is often viewed that the data scientist’s only job is to build a model. Even though it’s not exactly true, it’s extremely important. So I don’t think I need to emphasize why you should be good at building models.
Even though building a model could seem to be the last piece of your infrastructure puzzle, it isn’t.
One last step should follow. The step that will ensure the model you built really serves its purpose. Namely, solving a real-life problem.
Deploy Your Model
This is a very important part of building infrastructure for any of your data science projects. This last step really tests your model and its purpose. And you do that by allowing other people to become part of your project. Allow them to use your model and the insights it produces.
Bear in mind your job is to help others by turning data into insights and insights into recommendations. How do you reach other people? Ideally, you deploy your model. You can do that using an application framework such as Django or Flask. Or you can do it using the cloud providers such as Amazon Web Services or Google Cloud.
You could present your insights in the form of a simple dashboard the users could play with. Or maybe it could be API that users can connect to and get your insights and recommendations.
Why is deploying a model an important step and a skill you should master? It will lead to, sometimes radical, changes in the business process. Once manually performed, tasks will be taken over by the algorithm-based solutions. Only through deployment, your model will serve its purpose of solving a real-life problem. Deploying a model will showcase a broader aspect of your skills as a data scientist: not only your technical skills but an understanding of business and its processes itself.
Again, this is something you gain through experience. If you lack experience, it’s always wise to compensate it a little with your technical knowledge. So if you’ve already learned how to use APIs and cloud services to retrieve and store the data for your model, you could also use them to deploy a model.
If you really want to add application frameworks to your skills, I can only encourage you. There’s plenty of both Flask and Django books, tutorials, and sources that can help you in mastering these tools.
If you lack the data science projects ideas, here’s a suggestion of eight projects you can have a go at. Just follow those four guidelines from this article, and you should be fine.
Summary
The main take-home points for creating a data science infrastructure when building a project are:
- Always have in mind your job is not (only) to build a model but to solve a real-life problem.
- Your project infrastructure should be directed at helping you solve a problem.
- The four main components of your project infrastructure should be:
- API for input data
- (Cloud) database
- Model
- API for insights
Structuring the data science infrastructure that way, you’ll make sure you made an impact with your project.
Original. Reposted with permission.
Bio: Nate Rosidi is a Data Scientist and Product Manager.
Related: