Building Practical MLOps for a Personal ML Project
A step-by-step guide to turning a notebook-based analysis into a reproducible, deployable, and portfolio-ready MLOps project

Image by Author
# Introduction
You’ve probably done your fair share of data science and machine learning projects.
They are great for sharpening skills and showing off what you know and have learned. But here’s the thing: they often stop short of what real-world, production-level data science looks like.
In this article, we take a project — the U.S. Occupational Wage Analysis — and turn it into something that says, “This is ready for real-world use.”
For this, we will walk through a simple but solid machine learning operations (MLOps) setup that covers everything from version control to deployment.
It’s great for early-career data people, freelancers, portfolio builders, or whoever wants their work to look like it came out of a professional setup, even if it did not.
In this article, we will go beyond notebook projects: we will set up our MLOps structure, learn how to set up reproducible pipelines, model artifacts, a simple local application programming interface (API), logging, and finally, how to produce useful documentation.

Image by Author
# Understanding the Task and the Dataset
The scenario for the project consists of a national U.S. dataset that has annual occupational wage and employment data in all 50 U.S. states and territories. The data details employment totals, mean wages, occupational groups, wage percentiles, and also geographic identifiers.

Your main objectives are:
- Comparing differences in wages across different states and job categories
- Running statistical tests (T-tests, Z-tests, F-tests)
- Building regressions to understand the relationship between employment and wages
- Visualizing wage distributions and occupation trends
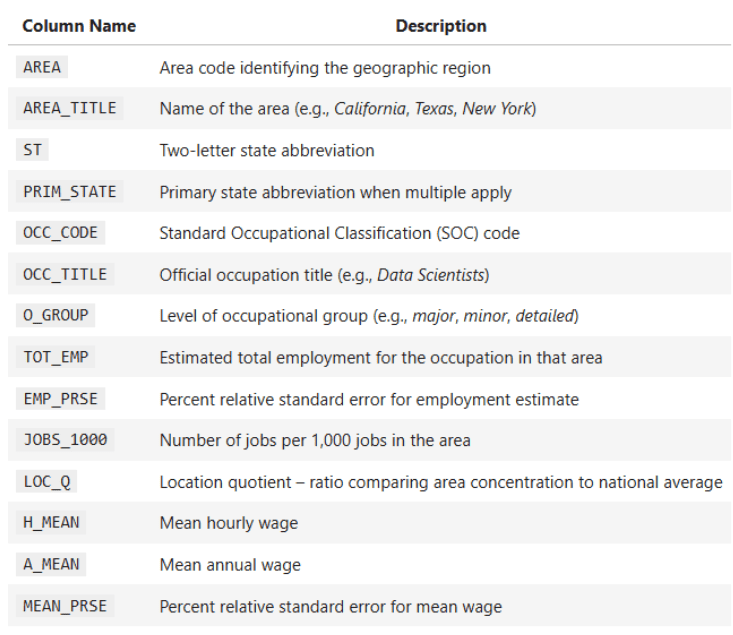
Some key columns of the dataset:
OCC_TITLE— Occupation nameTOT_EMP— Total employmentA_MEAN— Average annual wagePRIM_STATE— State abbreviationO_GROUP— Occupation category (Major, Total, Detailed)
Your mission here is to produce reliable insights about wage disparities, job distribution, and statistical relationships, but it does not stop there.
The challenge is also to structure the project in a way that it becomes reusable, reproducible, and clean. This is a very important skill required for all data scientists nowadays.
# Starting with Version Control
Let’s not skip the basics. Even small projects deserve a clean structure and proper version control. Here’s a folder setup that’s both intuitive and reviewer-friendly:

A few best practices:
- Keep raw data immutable. You do not need to touch it, just copy it for processing.
- Consider using Git LFS if your datasets get big and chunky.
- Keep each script in
src/focused on one thing. Your future self will thank you. - Commit often and use clear messages like:
feat: add T-test comparison between management and production wages.
Even with this simple structure, you are showing hiring managers that you’re thinking and planning like a professional, not like a junior.
# Building Reproducible Pipelines (and Leaving Notebook Chaos Behind)
Notebooks are amazing for exploration. You try something, tweak a filter, re-run a cell, copy a chart, and before you know it, you’ve got 40 cells and no idea what actually produced the final answer.
To make this project feel “production-ish”, we’ll take the logic that already lives in the notebook and wrap it in a single preprocessing function. That function becomes the one, canonical place where the U.S. occupational wage data is:
- Loaded from the Excel file
- Cleaned and converted to numeric
- Normalized (states, occupation groups, occupation codes)
- Enriched with helper columns like total payroll
From then on, every analysis — plots, T-tests, regressions, correlations, Z-tests — will reuse the same cleaned DataFrame.
// From Top-of-Notebook Cells to a Reusable Function
Right now, the notebook roughly does this:
- Loads the file:
state_M2024_dl.xlsx - Parses the first sheet into a DataFrame
- Converts columns like
A_MEAN,TOT_EMPto numeric - Uses those columns in:
- State-level wage comparisons
- Linear regression (
TOT_EMP→A_MEAN) - Pearson correlation (Q6)
- Z-test for tech vs non-tech (Q7)
- Levene test for wage variance
We’ll turn that into a single function called preprocess_wage_data that you can call from anywhere in the project:
from src.preprocessing import preprocess_wage_data
df = preprocess_wage_data("data/raw/state_M2024_dl.xlsx")
Now your notebook, scripts, or future API call all agree on what “clean data” means.
// What the Preprocessing Pipeline Actually Does

For this dataset, the preprocessing pipeline will:
1. Load the Excel file once.
xls = pd.ExcelFile(file_path)
df_raw = xls.parse(xls.sheet_names[0])
df_raw.head()

2. Convert key numeric columns to numeric.
These are the columns your analysis actually uses:
- Employment and intensity:
TOT_EMP,EMP_PRSE,JOBS_1000,LOC_QUOTIENT - Wage measures:
H_MEAN,A_MEAN,MEAN_PRSE - Wage percentiles:
H_PCT10,H_PCT25,H_MEDIAN,H_PCT75,H_PCT90,A_PCT10,A_PCT25,A_MEDIAN,A_PCT75,A_PCT90
We coerce them safely:
df = df_raw.copy()
numeric_cols = [
"TOT_EMP", "EMP_PRSE", "JOBS_1000", "LOC_QUOTIENT" ….]
for col in numeric_cols:
if col in df.columns:
df[col] = pd.to_numeric(df[col], errors="coerce")
If a future file contains weird values (e.g. '**' or 'N/A'), your code will not explode, it will just treat them as missing, and the pipeline will not break.
3. Normalize text identifiers.
For consistent grouping and filtering:
PRIM_STATEto uppercase (e.g. "ca" → "CA")O_GROUPto lowercase (e.g. "Major" → "major")OCC_CODEto string (for.str.startswith("15")in the tech vs non-tech Z-test)
4. Add helper columns used in analyses.
These are simple but handy. The helper for the total payroll per row is, approximate, using the mean wage:
df["TOTAL_PAYROLL"] = df["A_MEAN"] * df["TOT_EMP"]
The wage-to-employment ratio is useful for spotting high wage / low employment niches, with protection against division by zero:
df["WAGE_EMP_RATIO"] = df["A_MEAN"] / df["TOT_EMP"].replace({0: np.nan})
5. Return a clean DataFrame for the rest of the project.
Your later code for:
- Plotting top/bottom states
- T-tests (Management vs Production)
- Regression (
TOT_EMP→A_MEAN) - Correlations (Q6)
- Z-tests (Q7)
- Levene’s test
can all start with:
df = preprocess_wage_data("state_M2024_dl.xlsx")
Full preprocessing function:
Drop this into src/preprocessing.py:
import pandas as pd
import numpy as np
def preprocess_wage_data(file_path: str = "state_M2024_dl.xlsx") -> pd.DataFrame:
"""Load and clean the U.S. occupational wage data from Excel.
- Reads the first sheet of the Excel file.
- Ensures key numeric columns are numeric.
- Normalizes text identifiers (state, occupation group, occupation code).
- Adds helper columns used in later analysis.
"""
# Load raw Excel file
xls = pd.ExcelFile(file_path)
Check the rest of the code here.
# Saving Your Statistical Models and Artifacts
What are model artifacts? Some examples: regression models, correlation matrices, cleaned datasets, and figures.
import joblib
joblib.dump(model, "models/employment_wage_regression.pkl")
Why save artifacts?
- You avoid recomputing results during API calls or dashboards
- You preserve versions for future comparisons
- You keep analysis and inference separate
These small habits elevate your project from exploratory to production-friendly.
# Making It Work Locally (With an API or Tiny Web UI)
You don’t need to jump straight into Docker and Kubernetes to “deploy” this. For a lot of real-world analytics work, your first API is simply:
- A clean preprocessing function
- A few well-named analysis functions
- A small script or notebook cell that wires them together
That alone makes your project easy to call from:
- Another notebook
- A Streamlit/Gradio dashboard
- A future FastAPI or Flask app
// Turning Your Analyses Into a Tiny “Analysis API”
You already have the core logic in the notebook:
- T-test: Management vs Production wages
- Regression:
TOT_EMP→A_MEAN - Pearson correlation (Q6)
- Z-test tech vs non-tech (Q7)
- Levene’s test for wage variance
We’ll wrap at least one of them into a function so it behaves like a tiny API endpoint.
Example: “Compare management vs production wages”
This is a function version of the T-test code that’s already in the notebook:
from scipy.stats import ttest_ind
import pandas as pd
def compare_management_vs_production(df: pd.DataFrame):
"""Two-sample T-test between Management and Production occupations."""
# Filter for relevant occupations
mgmt = df[df["OCC_TITLE"].str.contains("Management", case=False, na=False)]
prod = df[df["OCC_TITLE"].str.contains("Production", case=False, na=False)]
# Drop missing values
mgmt_wages = mgmt["A_MEAN"].dropna()
prod_wages = prod["A_MEAN"].dropna()
# Perform two-sample T-test (Welch's t-test)
t_stat, p_value = ttest_ind(mgmt_wages, prod_wages, equal_var=False)
return t_stat, p_value
Now this test can be reused from:
- A main script
- A Streamlit slider
- A future FastAPI route
without copying any notebook cells.
// A Simple Local Entry Point
Here’s how all the pieces fit together in a plain Python script, which you can call main.py or run in one notebook cell:
from preprocessing import preprocess_wage_data
from statistics import run_q6_pearson_test, run_q7_ztest # move these from the notebook
from analysis import compare_management_vs_production # the function above
if __name__ == "__main__":
# 1. Load and preprocess the data
df = preprocess_wage_data("state_M2024_dl.xlsx")
# 2. Run core analyses
t_stat, p_value = compare_management_vs_production(df)
print(f"T-test (Management vs Production) -> t={t_stat:.2f}, p={p_value:.4f}")
corr_q6, p_q6 = run_q6_pearson_test(df)
print(f"Pearson correlation (TOT_EMP vs A_MEAN) -> r={corr_q6:.4f}, p={p_q6:.4f}")
z_q7 = run_q7_ztest(df)
print(f"Z-test (Tech vs Non-tech median wages) -> z={z_q7:.4f}")
This does not look like a web API yet, but conceptually it is:
- Input: the cleaned DataFrame
- Operations: named analytical functions
- Output: well-defined numbers you can surface in a dashboard, a report, or, later, a REST endpoint.
# Logging Everything (Even the Details)
Most people overlook logging, but it is how you make your project debuggable and trustworthy.
Even in a beginner-friendly analytics project like this one, it’s useful to know:
- Which file you loaded
- How many rows survived preprocessing
- Which tests ran
- What the key test statistics were
Instead of manually printing everything and scrolling through notebook output, we’ll set up a simple logging configuration that you can reuse in scripts and notebooks.
// Basic Logging Setup
Create a logs/ folder in your project, and then add this somewhere early in your code (e.g. at the top of main.py or in a dedicated logging_config.py):
import logging
from pathlib import Path
# Make sure logs/ exists
Path("logs").mkdir(exist_ok=True)
logging.basicConfig(
filename="logs/pipeline.log",
level=logging.INFO,
format="%(asctime)s - %(levelname)s - %(message)s"
)
Now, every time you run your pipeline, a logs/pipeline.log file will be updated.
// Logging the Preprocessing and Analyses
We can extend the main example from Step 5 to log what’s happening:
from preprocessing import preprocess_wage_data
from statistics import run_q6_pearson_test, run_q7_ztest
from analysis import compare_management_vs_production
import logging
if __name__ == "__main__":
logging.info("Starting wage analysis pipeline.")
# 1. Preprocess data
df = preprocess_wage_data("state_M2024_dl.xlsx")
logging.info("Loaded cleaned dataset with %d rows and %d columns.", df.shape[0], df.shape[1])
# 2. T-test: Management vs Production
t_stat, p_value = compare_management_vs_production(df)
logging.info("T-test (Mgmt vs Prod) -> t=%.3f, p=%.4f", t_stat, p_value)
# 3. Pearson correlation (Q6)
corr_q6, p_q6 = run_q6_pearson_test(df)
logging.info("Pearson (TOT_EMP vs A_MEAN) -> r=%.4f, p=%.4f", corr_q6, p_q6)
# 4. Z-test (Q7)
z_q7 = run_q7_ztest(df)
logging.info("Z-test (Tech vs Non-tech median wages) -> z=%.3f", z_q7)
logging.info("Pipeline finished successfully.")
Now, instead of guessing what happened last time you ran the notebook, you can open logs/pipeline.log and see a timeline of:
- When preprocessing started
- How many rows/columns you had
- What the test statistics were
That’s a small step, but a very “MLOps” thing to do: you’re not just running analyses, you’re observing them.
# Telling the Story (AKA Writing for Humans)
Documentation matters, especially when dealing with wages, occupations, and regional comparisons, topics real decision-makers care about.
Your README or final notebook should include:
- Why this analysis matters
- A summary of wage and employment patterns
- Key visualizations (top/bottom states, wage distributions, group comparisons)
- Explanations of each statistical test and why it was chosen
- Clear interpretations of regression and correlation results
- Limitations (e.g. missing state records, sampling variance)
- Next steps for deeper analysis or dashboard deployment
Good documentation turns a dataset project into something anyone can use and understand.
# Conclusion
Why does all of this matter?
Because in the real world, data science doesn't live in a vacuum. Your beautiful model isn’t helpful if no one else can run it, understand it, or trust it. That’s where MLOps comes in, not as a buzzword, but as the bridge between a cool experiment and an actual, usable product.
In this article, we started with a typical notebook-based assignment and showed how to give it structure and staying power. We introduced:
- Version control to keep our work organized
- Clean, reproducible pipelines for preprocessing and detection
- Model serialization so we can re-use (not re-train) our models
- A lightweight API for local deployment
- Logging to track what’s going on behind the scenes
- And finally, documentation that speaks to both techies and business folks
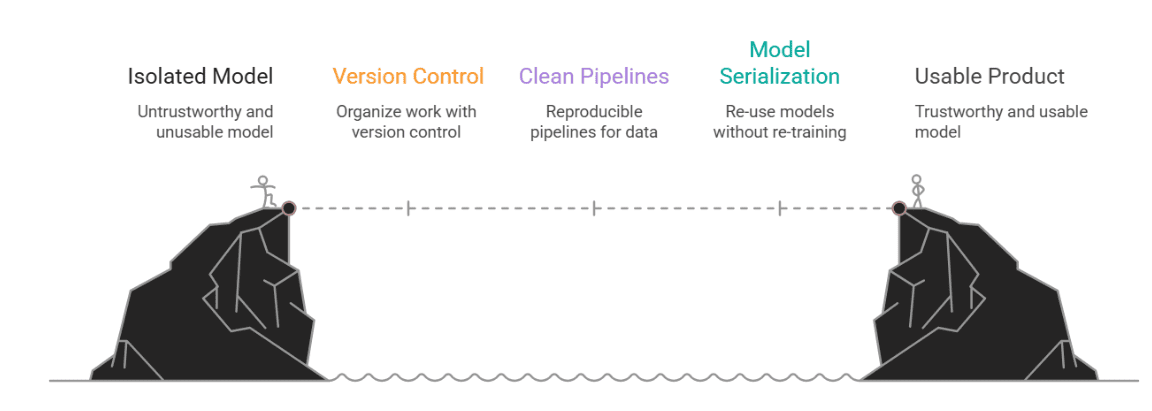
Image by Author
Nate Rosidi is a data scientist and in product strategy. He's also an adjunct professor teaching analytics, and is the founder of StrataScratch, a platform helping data scientists prepare for their interviews with real interview questions from top companies. Nate writes on the latest trends in the career market, gives interview advice, shares data science projects, and covers everything SQL.