Turn Your Laptop Into a Personal Analytics Engine with DuckDB and MotherDuck
Bring the powerful tools to your laptop.

Image Generated with DALL-E
In a time where data analytic processing is the critical difference between a successful business and not, we need a tool stack that could support the needs. The advancement of technology has helped advance all these data tools that we need, namely DuckDB and MotherDuck.
DuckDB is an open-source, in-process SQL Online Analytical Processing (OLAP) database management system. The database system is designed for swiftly handling data analytical queries, regardless of the data size. The system implements in-memory processing and OLAP systems that effectively improve our data analytical process.
DuckDB is perfect for storing and processing tabular data involving data analysis (table join, data aggregation, etc.) and when our workflow usually involves significant changes in the table. On the other hand, DuckDB isn’t suitable for high-volume data activity and multiple concurrent processes in one database.
MotherDuck is a managed DuckDB-in-the-cloud service. It’s free to use and open-source while maintained by the DuckDB Community. It’s a service built by partnering with DuckDB Lab to create a cloud service platform that the public can use.
With a combination of DuckDB and Motherduck, we can create an analytics engine that is readily useable in every scenario. How do we do that? Let’s get into it.
MotherDuck UI
We would use the native MotherDuck UI to give you an example of how the service works and why DuckDB is a powerful tool for data analytics. Please register on the website and acquire the MotherDuck account if you haven’t already.
Once you successfully register for the MotherDuck account, we will be taken to the MotherDuck UI. Try to familiarize yourself with the UI, and you will realize that the UI is similar to the Jupyter Notebook if you ever use one.
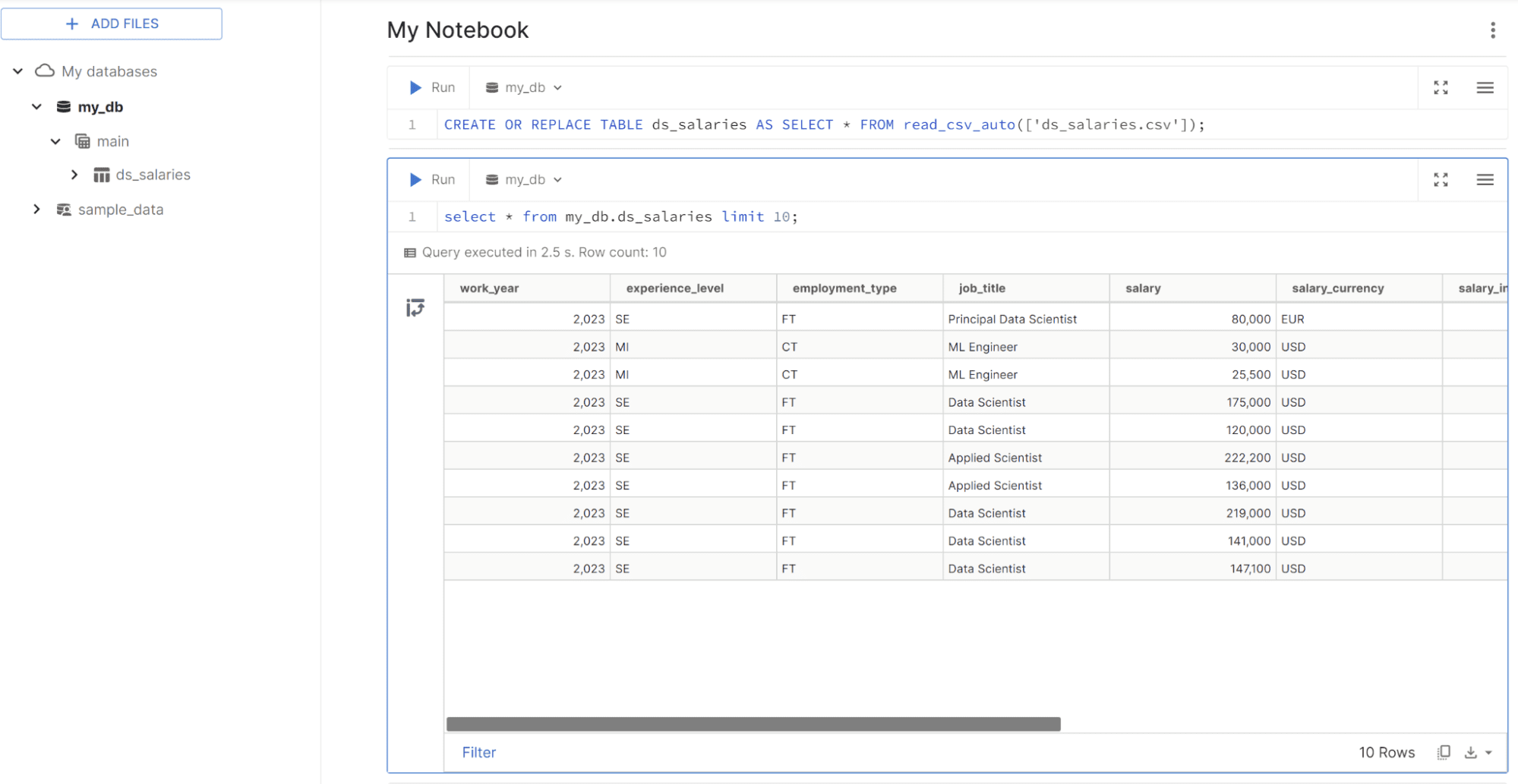
We will experiment with the DBduck power in the MotherDuck UI with the DS Salary data from Kaggle. Upload the data using the Add Files button, and a new cell will be shown with the query to execute. The query should look like this.
CREATE OR REPLACE TABLE ds_salaries AS SELECT * FROM read_csv_auto(['ds_salaries.csv']);
Once you create the table, try to query the data with the following code.
select * from my_db.ds_salaries limit 10;
As you can see, MotherDuck is pretty much like doing data analysis in Notebook, but with SQL queries. Let’s try out the query to do data analysis in the MotherDuck.
select job_title,
avg(salary_in_usd) as average_salary_in_usd
from my_db.ds_salaries
GROUP BY job_title
ORDER BY job_title
You can execute the query in the cell; the table result is shown similarly to the image below.
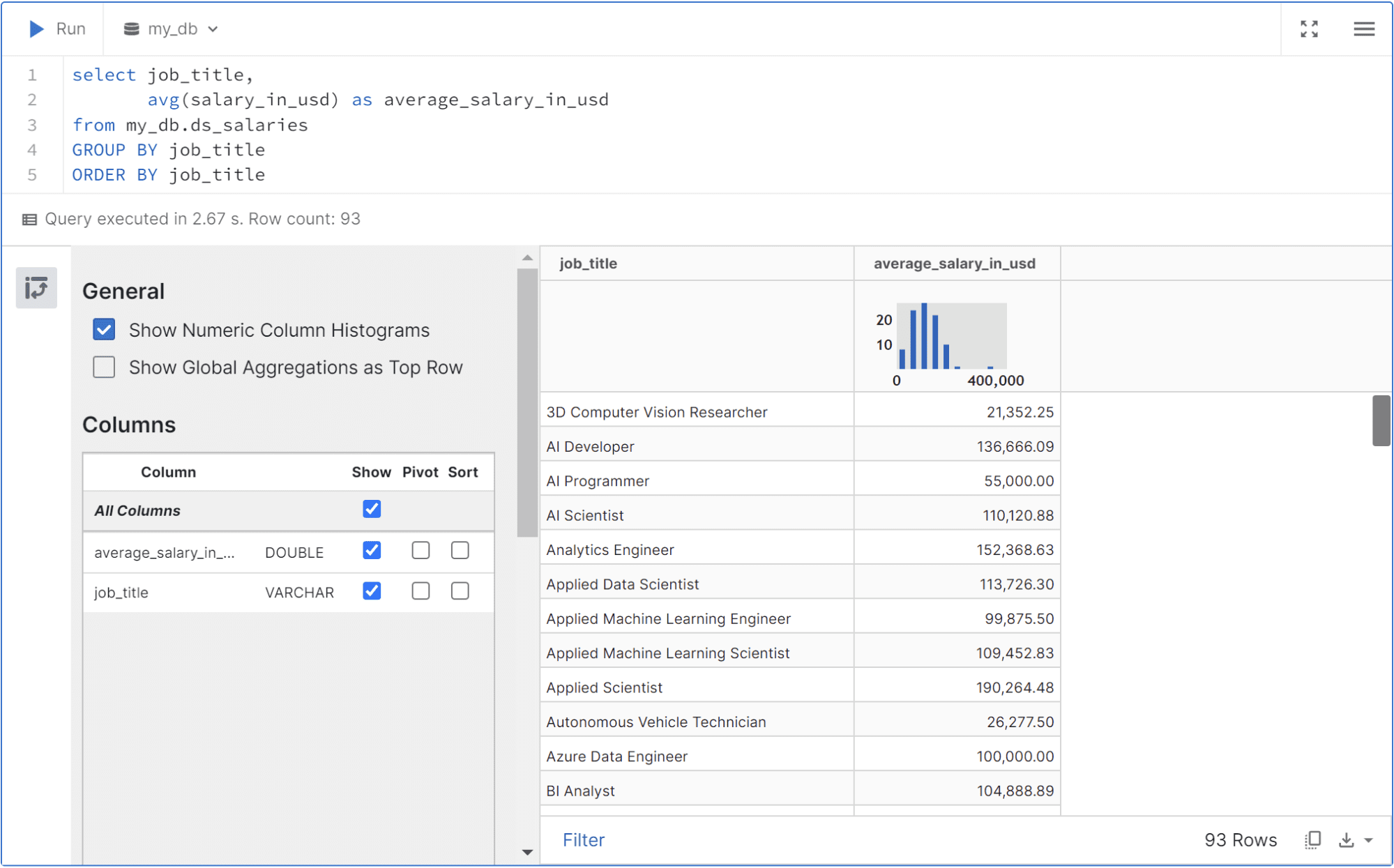
You can filter out the data, pivot the table, or download the result with the selection button available in the UI.
MotherDuck Python
MotherDuck also allows the user to access the database via Python on your Notebook. We need to install the DuckDB package using the following code.
pip install duckdb==v0.9.2
The current version that MotherDuck supports is DuckDB 0.9.2; that’s why we installed that version.
When the installation is successful, we need to connect the DuckDB with the Motherduck. There are a few ways to authenticate the connection, but we would use the service token. This token is acquired in your MotherDuck settings.
import duckdb
token = "insert token here"
# initiate the MotherDuck connection
con = duckdb.connect(f'md:?motherduck_token={token}')
If we didn’t set any database name, MotherDuck would access using the default database, which is my_db. Next, let’s use the same query we did previously in the Notebook.
q = """
select job_title,
avg(salary_in_usd) as average_salary_in_usd
from my_db.ds_salaries
GROUP BY job_title
ORDER BY job_title
"""
con.sql(q).show()
You will see the output similar to the table below.
┌─────────────────────────────────────┬───────────────────────┐
│ job_title │ average_salary_in_usd │
│ varchar │ double │
├─────────────────────────────────────┼───────────────────────┤
│ 3D Computer Vision Researcher │ 21352.25 │
│ AI Developer │ 136666.0909090909 │
│ AI Programmer │ 55000.0 │
│ AI Scientist │ 110120.875 │
│ Analytics Engineer │ 152368.63106796116 │
│ Applied Data Scientist │ 113726.3 │
│ Applied Machine Learning Engineer │ 99875.5 │
│ Applied Machine Learning Scientist │ 109452.83333333333 │
│ Applied Scientist │ 190264.4827586207 │
│ Autonomous Vehicle Technician │ 26277.5 │
│ · │ · │
│ · │ · │
│ · │ · │
│ Principal Data Engineer │ 192500.0 │
│ Principal Data Scientist │ 198171.125 │
│ Principal Machine Learning Engineer │ 190000.0 │
│ Product Data Analyst │ 56497.2 │
│ Product Data Scientist │ 8000.0 │
│ Research Engineer │ 163108.37837837837 │
│ Research Scientist │ 161214.19512195123 │
│ Software Data Engineer │ 62510.0 │
│ Staff Data Analyst │ 15000.0 │
│ Staff Data Scientist │ 105000.0 │
├─────────────────────────────────────┴───────────────────────┤
│ 93 rows (20 shown) 2 columns │
└─────────────────────────────────────────────────────────────┘
With the query above, you can use the following code to process them into the Pandas DataFrame.
import pandas as pd
df = con.sql(q).fetchdf()
Lastly, you can load another dataset to the database using the following query.
con.sql("CREATE TABLE mytable AS SELECT * FROM '~/filepath.csv'")
The above query assumes your data is a CSV file. Other options include S3 or the local DuckDB to the MotherDuck database.
Conclusion
DuckDB is an open-source database system that was developed specifically for data analysis. The system is designed to handle data processing swiftly and efficiently. MotherDuck is an open-source managed cloud-based service for DuckDB.
By combining DuckDB and MotherDuck, we can turn our laptops into a personal analytics engine by having our data in the cloud and quickly processing them with DuckDB.
Cornellius Yudha Wijaya is a data science assistant manager and data writer. While working full-time at Allianz Indonesia, he loves to share Python and data tips via social media and writing media. Cornellius writes on a variety of AI and machine learning topics.