KDnuggets: Personal History and Nuggets of Experience
After 28+ years of publishing and editing KDnuggets, I am retiring and transitioning KDnuggets to Matthew Mayo, who will become the new editor-in-chief. I want to share with you my story of KDnuggets and highlight some of the useful nuggets of experience I learned along this amazing journey.
Dear KDnuggets Readers,
I have big news! After 40+ years of full-time work, 32+ years of data mining/ KDD/ data science, 28+ years of publishing and editing KDnuggets, and 20+ years of being self-employed and running a business, I am retiring and moving on to new challenges.
I am pleased to say that I am leaving KDnuggets in the capable hands of Matthew Mayo who has been my partner running KDnuggets for the last five and a half years. He will become Editor in Chief at the end of December, and will take over the editor1@kdnuggets.com email. I will continue to transition KDnuggets operations to Matthew Mayo for the rest of 2021 and will be an advisor thereafter.
KDnuggets is now part of Padre Media, a technology focused media company which publishes other online properties such as MachineLearningMastery.com.
KDnuggets is doing better than ever, with over 800,000 unique visitors per month this year, over 70,000 email subscribers, and over 300,000 followers on social media. KDnuggets is widely recognized for the quality of its content, and was recently named as no. 2 global publication in AI by Onalytica.
KDnuggets will continue to find and publish interesting and useful stories, tutorials, and opinions on AI, Machine Learning, and Data Science.
How did KDnuggets get to where it is today?
I want to share with you my story of KDnuggets and highlight some of the useful lessons (nuggets of experience) I drew from this amazing journey. While these ideas may seem obvious in retrospect, they were not obvious to me at the time, and executing these ideas is not easy.
KDnuggets Prehistory: KDD Workshops, 1989 - 1993
KD in KDnuggets stands for Knowledge Discovery, which comes from the name of Knowledge Discovery in Databases (KDD-89) workshop that I organized at IJCAI-89 in Detroit. What is the origin of this workshop?
I got my Ph.D. in 1984 from NYU on the topic of a Self-Organizing Database System. I was working in 1980s at a small company developing database systems, and after I got my PhD I joined GTE Labs. GTE was a telephone company, (it is now part of Verizon), and GTE Labs was a smaller and less glamorous version of AT&T Labs. Still, we had some great researchers there, including including Oliver Selfridge and not yet famous Rich Sutton, now widely recognized as one of the founders of Reinforcement Learning. At GTE Labs I was working on a project developing natural language interfaces to databases. I was interested in AI since my youth and I loved sci-fi stories about robots, so it was natural for me to try to apply Machine Learning ideas to databases.
Optimizing database queries was tricky, but in one case I found a pattern in data that allowed me to speed up that query by a factor of 100,000. My thought was:
Can we find such patterns in data automatically? Are there other useful patterns in data?
There were already some early papers on data mining, but "data mining" was generally considered a bad thing by statisticians, and disparaged with names like “data fishing” or “data dredging”. It is true that searching for patterns without statistical safeguards can easily lead to finding spurious patterns (even in random data), but I thought one can do good data mining using appropriate statistics and find valid and useful patterns.
I also thought that the term “data mining” was not sexy enough and came up with the name “Knowledge Discovery In Databases”, which emphasized the result – “Knowledge” - rather than the process of “Mining”.
I could not get my management at GTE Labs interested in the idea of analyzing databases for interesting and useful patterns. One big manager told me – “we already have SQL, so the the problem of finding patterns in data is solved, isn’t it?”
I have attended an earlier workshop in 1986 on Expert Database Systems , which was interesting but rather unfocused. I thought that I could organize a workshop on Knowledge Discovery in Databases as a way to convince my management that a project on KDD would be a good idea.
Nugget: If you have a great idea, and your elders / managers tell you: "This problem has already been solved it" or "It is not interesting", give it a try anyway!
I have reached out to a few top researchers in the field, and to my surprise most have agreed to take part in the KDD-89 workshop, including Jaime Carbonell, Larry Kershberg, Ross Quinlan, and Pat Langley. The workshop was a lot more work than I anticipated, but it was a big success – it had the largest attendance of all IJCAI workshops that year. Those interested in history can see my KDD-89 workshop report here.
The success of the KDD workshop has convinced GTE Labs management to approve my project at GTE and thus the first project in the world on “Knowledge Discovery in Data” was launched. My team at GTE worked on several interesting tasks, including telecom churn prediction, fraud detection, and healthcare data analysis (see our book chapter and demo on KEFIR - Key Findings Reporter).
KDnuggets beginnings at GTE Labs: 1993-1997
I organized follow-up KDD workshops in 1991 and 1993, but a workshop every two years is not a way to build a community.
There were a few other email newsletters, but not one on KDD, and I thought a newsletter would be a good way to help KDD researchers to keep in touch. So on July 20, 1993, I emailed the very first issue of Knowledge Discovery Nuggets to about 50 researchers who attended KDD-93 (Knowledge Discovery in Databases) workshop I organized in Anaheim, CA.
Around 1994 the first web browser called Mosaic has appeared and web sites were popping up. In summer of 1994 we created a website at GTE, called Knowledge Discovery Mine which was the 2nd website in the world on the topic of data mining and knowledge discovery. With the data mining and KDD field rapidly growing, we started to keep a directory of software, companies, meetings, other websites, and everything that was relevant to KDD.
Most of the work on Knowledge Discovery Mine was done by Christopher Matheus, a brilliant young researcher I hired for my KDD project. Chris was a better programmer than I was and he frequently had very specific ideas on how things should be done. He was difficult to work with, and eventually left my project to start his own. However, he made a very major contribution to the KDnuggets prototype website, for which I am very grateful.
Nugget: If you work with talented but difficult people, focus on channeling their talent into useful projects, and learn to bypass personal differences.
Early KDnuggets: The dot-com bubble years and Y2K, 1997-2001
The dot-com bubble started around 1996. Many startups were being created and in early 1997 I left GTE Labs to join as a Chief Scientist a startup which was building data mining and CRM applications in financial area. I moved the content of Knowledge Discovery Mine to a new domain www.kdnuggets.com in February of 1997.
KDnuggets stood for Knowledge Discovery nuggets. The logo showed a database with ones and zeros on the left (ones and zeros have a hidden meaning, but I leave it to curious readers to figure this out), a human head with some knowledge structure on the right, and the arrow with KDD on top, suggesting that KDD process would go from data to knowledge.
The early KDnuggets website was a directory of everything related to Knowledge Discovery, from “Siftware” (this was a pun on the software for mining, hence “Sift”-ware), to companies, other websites, next KDD conference, and more. I also published an approximately bi-weekly newsletter with short items related to research and applications in KDD and Data Mining.
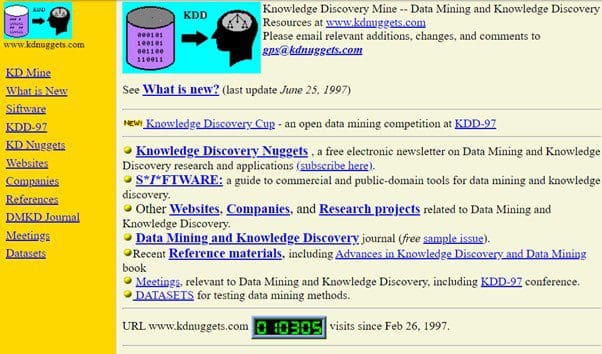
A snapshot of KDnuggets homepage from July of 1997, taken from the Wayback machine.
I enjoyed publishing KDnuggets and got the startup to agree that I can continue spending a day a week on it. Of course, this did not work out, since the startup took more than 40 hours a week, so I would frequently start working on KDnuggets only after 10 pm, after putting our kids to bed.
So far all KDnuggets activity was on a purely volunteer, unpaid, basis. However, things changed in the fall of 1999, when our startup was hit by Y2K freeze. Y2K, for young readers, was the problem at the end of 1990s, caused by using 2 digits for the year in many old software applications. Such software would stop working correctly in the year 2000, because "00" would be smaller than "99". So many large companies, including all of our clients, have poured a lot of resources into fixing this problem, and then froze all new development in the 2nd half of 1999. As a result, both our work and our salaries at that startup were cut significantly.
With more time and less money, I experimented with putting some ads on KDnuggets, which by that time grew to several thousand email subscribers.
The adventures in the land of dot-com bubble have continued. The clients have returned after Y2K has passed and our small startup was bought for $50M by a larger startup in April of 2000. I received significant stock options, but they required 12 months of vesting. The larger startup, propelled by several acquisitions, had briefly reached $1B in value, but before I or any of my colleagues could sell any stock options, the large startup collapsed and the value of my stock options went all the way from 2 million down to zero.
KDnuggets between consulting and KDD Conferences: 2001-2009
I left the collapsing startup in June 2001, a couple of months before it declared bankruptcy, and started publishing KDnuggets and and started the grand adventure of being self-employed. I was continuing to maintain KDnuggets as a directory of everything in KDD and Data Mining (the term Data Scientist has not appeared yet) and email KDnuggets News about every 2 weeks.
I was also actively doing data mining consulting. One of the most memorable projects as an expert witness for Tiffany vs eBay. At that time (around 2003) there were many items of Tiffany jewelry that appeared on eBay. However, most of them were counterfeit. When Tiffany complained to eBay, eBay said something like - we cannot check the validity of each item. Tiffany said – “you can use data mining algorithms to do that” and hired me as an expert. My approach was to focus not on items but on sellers and analyze them and their networks to find fakes. So for a few weeks one summer I would get up very early, before eBay control team in California, and accompanied by my cat “Ryzhaishii” (which means “The Most Orange Cat” in Russian), would collect data on several thousand Tiffany items for sale that morning. “Ryzhaishii” would purr for the whole hour non-stop, and I get to look at beautiful jewelry (does not matter that most of it was fake). What could be better work for a data mining consultant?
Next day I would see that predictions of my algorithm were mostly correct by checking which items were withdrawn manually the previous day by eBay control team. Although Tiffany lost this case in court, eBay has implemented stricter controls focusing on the sellers rather than items, and that helped reduce significantly the counterfeit jewelry items for sale.
I also worked with SPSS and MIT Broad Institute to capture the best practices for Microarray Data Analysis and encode them in application templates, fortunately named CATs (Clementine Application Templates). The main problem was avoiding false positives, since there were typically only a hundred or so samples (patients), but for each sample we had data for many thousands of columns. So to improve accuracy we trained multiple neural networks in a nested cross-validation loop, used bagging to combine the results, and also identified potentially mislabelled data samples. Our approach was described in KDD-2003 paper "Capturing Best Practice for Microarray Gene Expression Data Analysis", by G. Piatetsky-Shapiro, T. Khabaza, S. Ramaswamy, which won honorary mention for the best application paper. Sridhar Ramasamy had a paper with Eric Lander and Eric Lander's Erdos number is two, so my Erdos number is 4.
However, Clementine template language was hard to use and was not freely available, so this project was shelved by SPSS.
Still it was a valuable experience and you can see my main assistants in this work here.

Another memorable consulting project was looking for biomarkers of Alzheimer in Mass Spectrometry data. Alzheimer is a very widespread disease in the elderly and finding early biomarkers can greatly help in early diagnosis and treatment. We had data for a few hundred elderly Alzheimer patients and a similar number of non-Alzheimer seniors and about 20,000 columns of biomarker for each. My analysis quickly found about 8 biomarkers that perfectly separated Alzheimer from non-Alzheimer patient. One of these biomarkers was even biologically plausible – it implied that non-Alzheimer patients had much higher levels of vitamin C. The results – 8 perfect predictors were too good to be true, and were probably caused by contamination of non-Alzheimer samples somewhere in the process. Still, for a while my friends and I were drinking extra doses of orange juice to get that vitamin C “protection”. However, when the company got a second set of data, there predictors from the first set did not apply, and there were no good predictors in the second set.
Nugget: If the results of data analysis seem too good to be true, they usually are. Look for data quality issues all the way from data collection to data pre-processing and prediction.
In the meantime, I was working on KDnuggets, mainly maintaining it as a directory for all things related to data mining and KDD.
Here is a snapshot of KDnuggets from 2002, where you can see a poll in the right column.

KDnuggets Homepage from 2002, taken from the Wayback machine.
Polls were very important feature of KDnuggets, especially polls on most popular data mining software, which were run from 2000 to 2019: Python leads the 11 top Data Science, Machine Learning platforms.
In parallel, I was also very involved in organizing KDD meetings. Organizing the 1989, 1991, 1993 workshops was a lot of work, and one of my best decisions ever was to ask Usama Fayyad and Sam Uthurusamy to take over the 1994 workshop.
The following year, being more ambitious than me, they have upgraded 1995 workshop to a full KDD-95 conference which tool place in Montreal, and KDD Conferences had a great run ever since, remaining a leading research conference in the field.
This also reminds me of a favorite saying of the president of the startup, where I worked from 1997 to 2000. He used to tell me that my job as the Director was to hire people smarter than me. I was always tempted to reply, "It is easy for you to do", but never did. He was quite right and followed his advice. Most of my successes happened when I was able to hire or involve very smart people, that exceeded me in some (sometimes all) aspects. Another version of this maxim is "A people hire other A people, but B people hire C people".
Nugget: Good leaders hire people smarter / more capable than they are
I served as a chair of KDD Steering committee until 2001 when the KDD was brought ACM umbrella. I was elected as ACM SIGKDD Director in 2001 and as Chair in 2005. This was quite time-consuming, especially when I decided to organize a KDD conference in Paris, the first conference outside of North America. I had to find both a US co-chair and a French co-chair and spend too much time learning about VAT tax issues in Europe. However, the KDD-2009 conference in Paris was great, with great technical content, and reception at Hotel de Ville in Paris. As Henry IV said about Paris, “Paris vaut bien une messe” (look it up).
I was involved in organizing KDD conferences for 20 years, from 1989 to 2009. It was all volunteer activity, frequently very time-consuming, but ultimately very rewarding because of the opportunity to interact with many very smart people, being able to bring a great conference to many different places. The conference activity also helped a lot with growing KDnuggets. However, when my term as KDD Chair ended in 2009, I was able to breathe a really big sigh of relief.
Nugget: Do volunteer work! It will make you feel good and sometimes it also pays off in unexpected benefits.
KDnuggets becomes a blog and takes off: 2010-2021
When my term as KDD Chair ended in 2009, I turned my full attention to KDnuggets. Its audience was stuck at around 30,000 visitors per month and was declining. At that time KDnuggets was mainly a directory of data mining-related content (like Software, Datasets, Jobs, etc). KDnuggets News newsletter was emailed about every 2 weeks. I realized that KDnuggets needed to publish new content daily, blog-style.
However, I was not smart enough to realize that I need to move it to the cloud.
So, I wrote my own hand-crafted PHP-style content management system, which worked great on my laptop. Starting in November 2009 I started to publish new KDnuggets blogs daily.
But the problem was - my hand-crafted system only worked on my laptop! With the growing KDnuggets work, how could I get someone else to help me?
The obvious solution was to move to a web-based CMS, and so in 2013 after a long and torturous conversion I finally moved KDnuggets to WordPress.
Nugget: Use cloud / web-based tools that enable collaboration!
With KDnuggets hosted on WordPress I was able to hire good interns and assistants, starting with Amnol Rajpurohit who wrote many excellent blogs and did many interviews with interesting people for KDnuggets.
I also joined Twitter in 2009 and was able to grow @KDnuggets from zero to nearly 200,000 followers today. A few years later I added a KDnuggets LinkedIn group which now has nearly 100,000 members. We also have a KDnuggets Facebook page.
The "Big Data" wave started around 2012. It was followed by "Data Science" wave (Data Scientist was proclaimed the sexiest job of the 21st century), then Machine Learning, and then Deep Learning wave. KDnuggets was well-positioned to ride each of those waves and to cover these overlapping topics with a range of interesting opinions and practical tutorials. This brought us widespread recognition. Over the last 10 years KDnuggets has received many awards and mentions as a leading publication / influencer in AI, Big Data, Data Science, Data Mining, and Machine Learning.
Based on KDnuggets posts that I was publishing on my LinkedIn profile, I was selected me as no. 1 on the LinkedIn Top Voices 2018: Data Science & Analytics.
KDnuggets has adopted a Responsive, Mobile-Friendly Design in 2016 and moved to secure, https access in 2017.
It is amazing to me that KDnuggets not only survived but thrived for 28+ years. We were able to do that by having a great team, and by adapting and reacting to many external and internal changes.
Nugget: There are always new and unexpected changes and being successful requires being able to adapt and react to them quickly
Since 2014 KDnuggets has been distributed and in the cloud, so fortunately we did not have to change our operations when COVID hit in March 2020. Our readership has actually kept increasing, perhaps because so many people were working from home.
KDnuggets Clients
Of course, KDnuggets as a self-supporting business would have been impossible without the support and sponsorship of many companies who were willing to work with a unique and non-typical blog that KDnuggets was, and wanted to reach our audience. The most frequent and longest advertisers over the last 20 years are 11ants, Amazon, Adgenuk, Anaconda, Angoss, Anna Anisin/Formulated, Bayesia, Cloudfactory, Corinium, DSTI, DataRobot, Databricks, Datacamp, Dataiku, Domino Data Labs, Elder Research, H2O.AI, IE group, Insightful, JMP, KNIME, KXEN, Megaputer, Metis, Miner3d, Mode, NVIDIA, NYU, Northwestern University, ODSC, O'Reilly, PAW (Predictive Analytics World), PNY, Provectus, Prudsys, RE.Work, ROIDNA, RapidMiner, Rapidinsight, Rice Analytics, SAS, SPSS, Salford Systems, Simplilearn, Stanford, Statsoft, TDWI, Textanalytics, The Modeling Agency, Thinkanalytics, USFCA, Viscovery, Wharton, Fairisaac/FICO, and Provalis / Wordstat, and many others.
I want to especially thank Laura Wilson from SAS and Eric King from The Modeling Agency who have advertised on KDnuggets for almost 20 years! We have also quite a few companies/organizations that have advertised for 10 years and many have advertised for 5 years continuously.
From the beginning of KDnuggets as a business I have adopted an approach of extending trust to advertisers, and doing the work first and sending the invoices afterwards. This has worked quite well while KDnuggets had relatively few clients, many of whom I knew personally from KDD conferences. But once we have grown to more clients, and after having experience of sending dozens of reminders and collection letters especially to some clients outside of US (you know who you are ), I had to formalize our approach and started asking for signed insertion orders before the advertising starts.
Nugget: Business based on trust can work on a small scale, but once business grows you need a more formal approach
Conclusion
KDnuggets platform and technology has changed many times. But our mission has remained essentially unchanged - to cover what is interesting in the field, and even though the names kept changing - Data Mining / Knowledge Discovery in Data / KDD / Predictive Analytics / Data Science / Machine Learning, the essence has remained the same - understanding the world around us objectively, via data, and using this data to extract useful knowledge, including predicting the future. Data Science, Machine Learning and AI are perhaps the most important technologies of our time. We cover them, writing for the practitioners. Of course, with over 800,000 monthly visitors, we now have more tutorials and opinions aimed at beginning Data Scientists, but we continue to publish more advanced content as well.
We are not always serious - check our cartoons.

Data Scientist: "I thought I had the sexiest job of the 21st century"
Some KDnuggets Cartoons even ended in textbooks, including in Let's Meet Up!, Anglais 1re, a English textbook designed to help French high-school readers to learn English via popular culture.
I think our success was also due to our aiming at high quality while keeping the volume low - finding and selecting only a few interesting and relevant "nuggets" to share with our audience.
KDnuggets would not be possible without help I have received from many people over the years, including Chris Matheus who helped start the initial Knowledge Discovery Mine at GTE, Michael Beddows who helped run it in 1990s, Anmol Rajpurohit who helped run KDnuggets in 2014-16, Manu Jeevan who worked on KDnuggets in 2019, and our interns and contributors, including Devendra Desale, Grant Marshall, Geethika Bhavya, Ilan Reinstein, Jitendra Mudhol, Pedro Lopez, Prasad Pore, Ran Bi, Reena Shaw, Schweta Bhatt, Thuy Pham, Zack Lipton, Dan Clark, and many others.
By far the best KDnuggets author and editor is Matthew Mayo who joined KDnuggets in April of 2016.
KDnuggets growth in the last 5 years is due in large part to his excellent work and I am very happy that he will become KDnuggets Editor in Chief at the end of December, and will guide KDnuggets for many more years.
Of course, the main source of our success is our authors and contributors who send us many good blogs!
Please read submission guidelines and send us your blogs!
The authors of top 8 most-viewed blogs each month will receive KDnuggets Blog Rewards.
Related:
- Happy 25th Birthday, KDnuggets
- Data Science History and Overview
- Exclusive: OpenAI summarizes KDnuggets