Data Engineering for the LLM Age
Great LLMs need great data. Discover the pipelines, tools, and RAG architecture shaping the future of AI-ready data engineering

Image by Editor
# Introduction
The rise of large language models (LLMs) like GPT-4, Llama, and Claude has changed the world of artificial intelligence. These models can write code, answer questions, and summarize documents with unbelievable competence. For data scientists, this new era is truly exciting, but it also presents a unique challenge, which is that the performance of these powerful models is fundamentally tied to the quality of the data that powers them.
While much of the public discussion focuses on the models themselves, the artificial neural networks, and the mathematics of attention, the overlooked hero of the LLM age is data engineering. The old rules of data management are not being replaced; they are being upgraded.
In this article, we will look at how the role of data is shifting, the critical pipelines required to support both training and inference, and the new architectures, like RAG, that are defining how we build applications. If you are a beginner data scientist looking to understand where your work fits into this new paradigm, this article is for you.
# Moving From BI To AI-Ready Data
Traditionally, data engineering was primarily focused on business intelligence (BI). The goal was to move data from operational databases like transaction records into data warehouses. This data was highly structured, clean, and organized into rows and columns to answer questions like, "What were last quarter's sales?"
The LLM age demands a deeper view. We now need to support artificial intelligence (AI). This involves dealing with unstructured data like the text in PDFs, the transcripts of customer calls, and the code in a GitHub repository. The goal is no longer just to collate this data but to transform it so a model can understand and reason about it.
This shift requires a new kind of data pipeline, one that handles different data types and prepares them for three different stages of an LLM's lifecycle:
- Pre-training and Fine-tuning: Teaching the model or specializing it for a task.
- Inference and Reasoning: Helping the model access new information at the time it is asked a question.
- Evaluation and Observability: Ensuring the model performs accurately, safely, and without bias.
Let's break down the data engineering challenges in each of these phases.
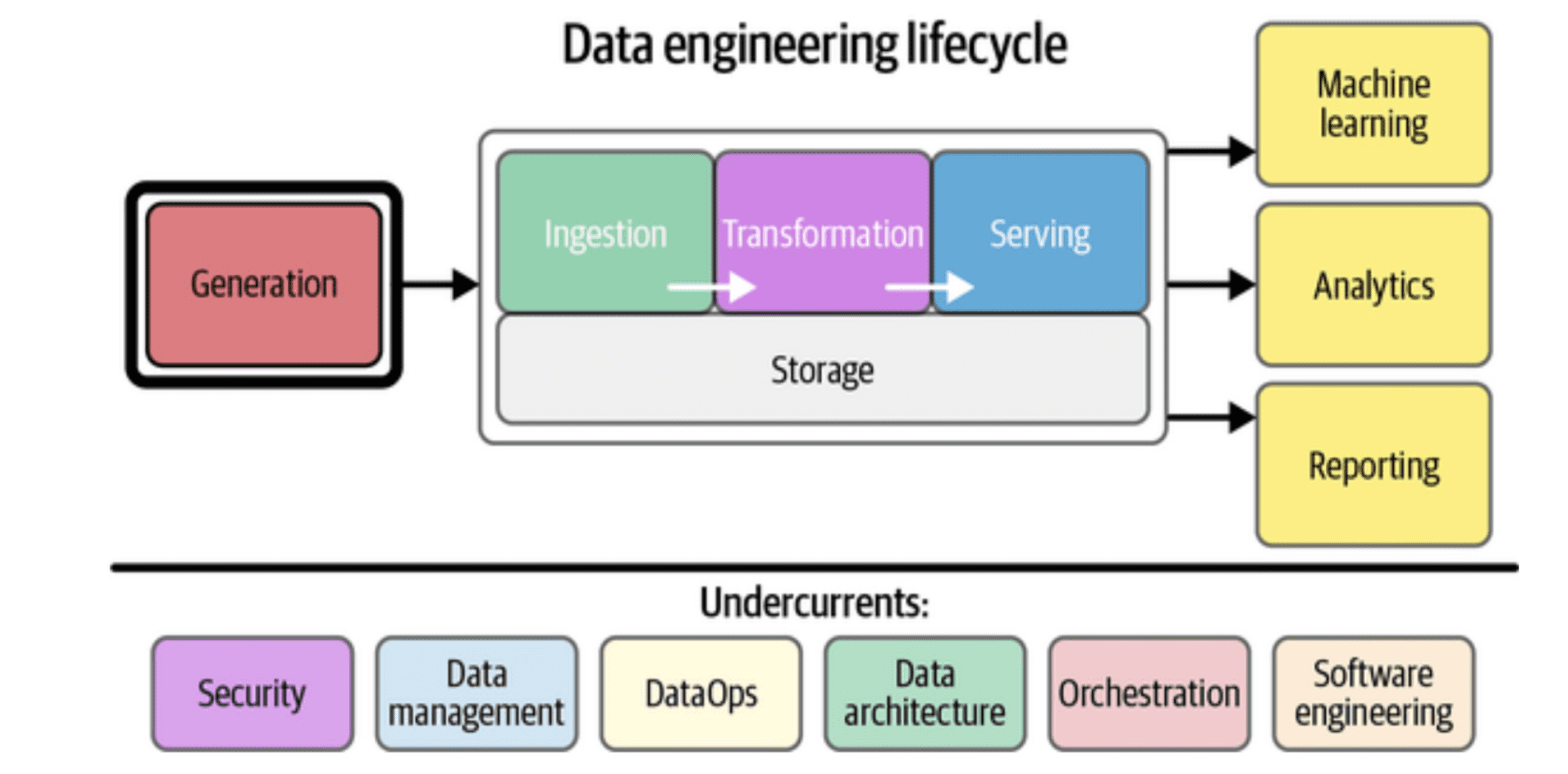
Fig_1: Data Engineering Lifecycle
# Phase 1: Engineering Data For Training LLMs
Before a model can be helpful, it must be trained. This phase is data engineering at a massive scale. The goal is to gather a high-quality dataset of text that represents a significant portion of the world's knowledge. Let’s look at the pillars of training data.
// Understanding the Three Pillars Of Training Data
When building a dataset for pre-training or fine-tuning an LLM, data engineers must focus on three important aspects:
- LLMs learn by statistical pattern recognition. To understand a tiny difference, grammar, and reasoning, they need to be exposed to trillions of tokens (pieces of words). This means consuming petabytes of data from sources like Common Crawl, GitHub, scientific papers, and web archives. The huge volume requires distributed processing frameworks like Apache Spark to handle the data load.
- A model trained only on legal documents will be terrible at writing poetry. A different dataset is important for generalisation. Data engineers must build pipelines that pull from thousands of different domains to create a balanced dataset.
- Quality is the most important factor to consider. This is where the real work begins. The internet is full of noise, spam, boilerplate text (like navigation menus), and false information. A now-famous paper from Databricks, "The Secret Sauce behind 1,000x LLM Training Speedups", highlighted that data quality is commonly more important than model architecture.
- Pipelines must remove low-quality content. This includes deduplication (removing near-identical sentences or paragraphs), filtering out text not in the target language, and removing unsafe or harmful content.
- You must know where your data came from. If a model behaves unexpectedly, you need to trace its behaviour back to the source data. This is the practice of data lineage, and it becomes a critical compliance and debugging tool
For a data scientist, understanding that a model is only as good as its training data is the first step toward building reliable systems.
# Phase 2: Adopting RAG Architecture
While training a foundation model is a massive undertaking, most companies do not need to build one from scratch. Instead, they take an existing model and connect it to their own private data. This is where Retrieval-Augmented Generation (RAG) has become the dominant architecture.
RAG solves a core problem of LLMs being frozen in time at the moment of their training. If you ask a model trained in 2022 about a news event from 2023, it will fail. RAG gives the model a way to "look up" information in real time.
A typical LLM data pipeline for RAG looks like this:
- You have internal documents (PDFs, Confluence pages, Slack archives). A data engineer builds a pipeline to ingest these documents.
- LLMs have a limited "context window" (the amount of text they can process at once). You cannot throw a 500-page manual at the model. Therefore, the pipeline must intelligently chunk the documents into smaller, digestible pieces (e.g., a few paragraphs each).
- Each chunk is passed through another model (an embedding model) that converts the text into a numerical vector, a long list of numbers that represents the meaning of the text.
- These vectors are then stored in a specialized database designed for speed: a vector database.
When a user asks a question, the process reverses:
- The user's query is converted into a vector using the same embedding model.
- The vector database performs a similarity search, finding the chunks of text that are most semantically similar to the user's question.
- Those relevant chunks are passed to the LLM along with the original question, with a prompt like, "Answer the question based only on the following context."
// Tackling the Data Engineering Challenge
The success of RAG depends entirely on the quality of the ingestion pipeline. If the breakdown strategy is poor, the context will be broken. If the embedding model is mismatched to your data, the retrieval will fetch irrelevant information. Data engineers are responsible for controlling these parameters and building the reliable pipelines that make RAG applications work.
# Phase 3: Building The Modern Data Stack For LLMs
To build these pipelines, the procedure is changing. As a data scientist, you will encounter a new "stack" of technologies designed to handle vector search and LLM orchestration.
- Vector Databases: These are the core of the RAG stack. Unlike traditional databases that search for exact keyword matches, vector databases search by meaning.
- Examples: Pinecone, Weaviate, Milvus, and capabilities built into databases like PostgreSQL (pgvector).
- Orchestration Frameworks: These tools help you chain together prompts, LLM calls, and data retrieval into a coherent application.
- Examples: LangChain and LlamaIndex. They provide pre-built connectors for vector stores and templates for common RAG patterns.
- Data Processing: Good old-fashioned ETL (Extract, Transform, Load) is still vital. Tools like Spark are used to clean and prepare the massive datasets needed for fine-tuning.
The key takeaway is that the modern data stack is not a replacement for the old one; it is an extension. You still need your data warehouse (like Snowflake or BigQuery) for structured analytics, but now you need a vector store alongside it to power AI features.

Fig_2: The Modern Data Stack for LLMs
# Phase 4: Evaluating And Observing
The final piece of the puzzle is evaluation. In traditional machine learning, you could measure model performance with a simple metric like accuracy (was this image a cat or a dog?). With generative AI, evaluation is more nuanced. If the model writes a paragraph, is it accurate? Is it clear? Is it safe?
Data engineering plays a role here through LLM observability. We need to track the data flowing through our systems to debug failures.
Consider a RAG application that gives a bad answer. Why did it fail?
- Was the relevant document missing from the vector database? (Data Ingestion Failure)
- Was the document in the database, but the search failed to retrieve it? (Retrieval Failure)
- Was the document retrieved, but the LLM ignored it and made up an answer? (Generation Failure)
To answer these questions, data engineers build pipelines that log the entire interaction. They store the user query, the retrieved context, and the final LLM response. By analyzing this data, teams can identify bottlenecks, filter out bad retrievals, and create datasets to fine-tune the model for better performance in the future. This closes the loop, turning your application into a continuous learning system.
# Concluding Remarks
We are entering a phase where AI is becoming the primary interface through which we interact with data. For data scientists, this represents a massive opportunity. The skills required to clean, structure, and manage data are more valuable than ever.
However, the context has changed. You must now think about unstructured data with the same caution you once applied to structured tables. You must understand how training data shapes model behavior. You must learn to design LLM data pipelines that support retrieval-augmented generation.
Data engineering is the foundation upon which reliable, accurate, and safe AI systems are built. By mastering these concepts, you are not just keeping up with the trend; you are building the infrastructure for the future.
Shittu Olumide is a software engineer and technical writer passionate about leveraging cutting-edge technologies to craft compelling narratives, with a keen eye for detail and a knack for simplifying complex concepts. You can also find Shittu on Twitter.