The Hidden Skill Gap: Why Knowing SQL + Python Isn’t Enough Anymore
This article is about the gap between what candidates prepare for and what companies actually need right now.

# SQL + Python Just Isn't Enough
For years, the formula seemed simple: learn SQL + learn Python = get a data job. Especially as mid-sized companies started becoming "data-driven." Hiring managers were happy they could get anyone who could write a half-decent GROUP BY and wrangle a pandas DataFrame without breaking something. You know what PostgreSQL is? Get in, you got the job! This worked for some time. Until it didn't.
If you haven't noticed, the data professional's job market has undergone a structural shift. Yes, SQL and Python are still important; they're on every job description. But they've been demoted from differentiators to prerequisites.
Likely, you're still optimizing for the interview questions you practiced three years ago. Forget about it. This article is about the gap between what candidates prepare for and what companies actually need right now.
# What the Job Market Is Actually Asking For
A January 2026 breakdown by Future Proof Data Science of over 700 data scientist job postings found that Python and SQL are still among the top three skills, but machine learning and AI skills are second and fourth.
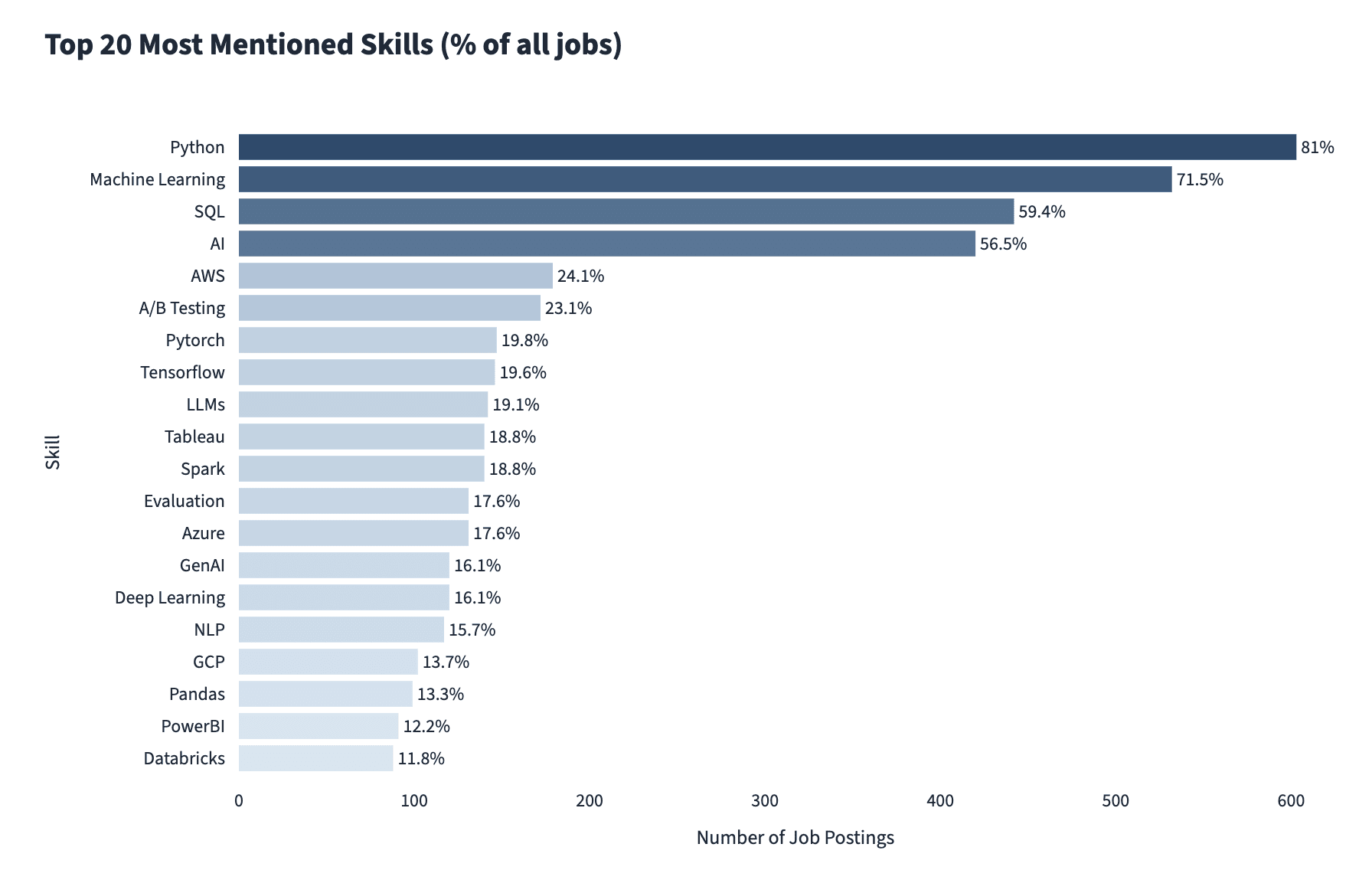
Image Source: Future Proof Data Science
Not all AI-related postings require hands-on AI expertise, but 1 in 3 does. The most required specific AI skills are:
- Large language models (LLMs)
- Retrieval-augmented generation (RAG)
- Prompt engineering
- Vector databases
This speaks to an increasing demand for data professionals who can build and deploy AI systems.
Keep in mind that the direction and the velocity of this change matter. This reminds me of how machine learning went from a niche requirement in 2012 to a near-universal one by 2020.
The second story is less visible but arguably more immediate for most candidates: the foundational engineering bar has risen sharply. Data engineering skills — pipelines, orchestration, cloud platforms, data quality checks — and machine learning in production — model monitoring, drift detection, evaluation design — are now core expectations rather than bonuses in data science job postings.
A glance at any major job board confirms it: along with AI skills, roles titled "Data Scientist" routinely list Snowflake, dbt, Airflow, and ETL pipeline ownership as requirements, not nice-to-haves.
There are four skills that you are probably missing. These are the new differentiators in the current job market.
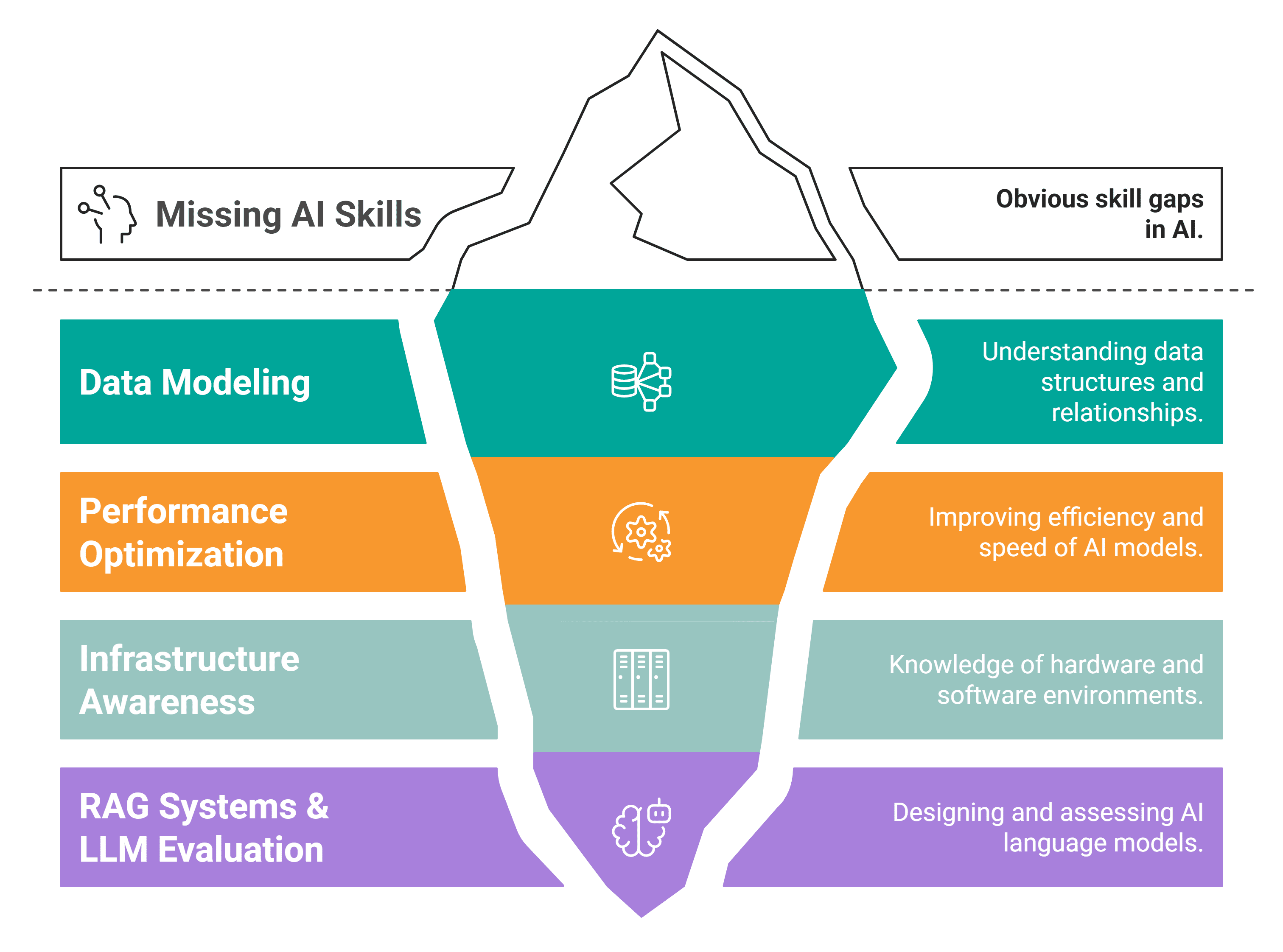
# Skill #1: Data Modeling
// What It Is
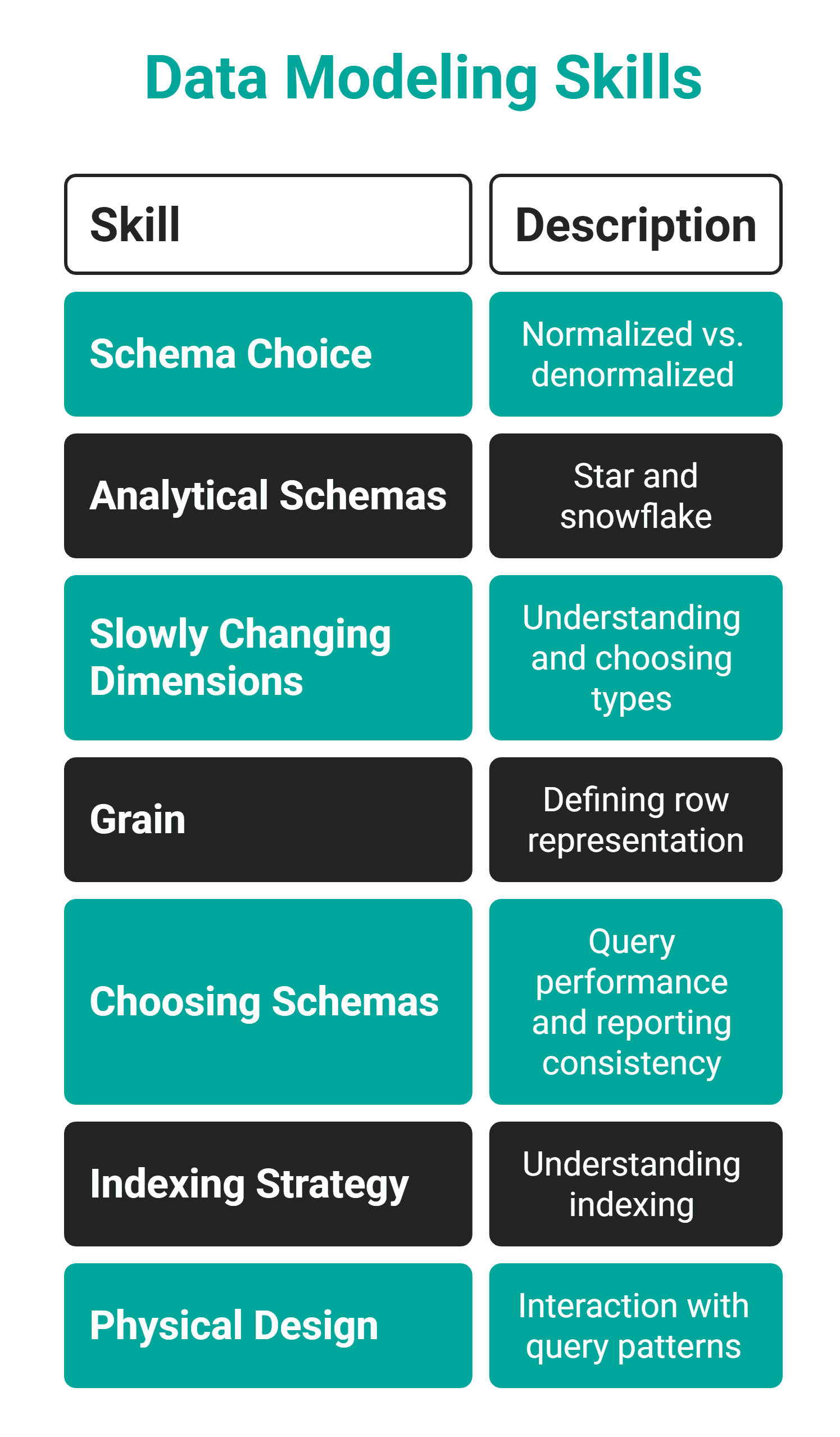
Data modeling is the ability to design how data should be structured, related, and stored. Think of it as deciding what tables to create, what they represent, and how they relate to each other.
// Why It Became a Differentiator
Tooling improvements changed the landscape. Snowflake, dbt, and BigQuery all made it relatively easy for data scientists to own the data transformation layer. In other words, modeling decisions that used to belong to data engineers are now being handed over to data scientists.
Get a data schema wrong, and you're in dangerous waters. Typically, these errors are not obvious immediately. Once they become obvious, it's too late. Your machine learning work has already been impacted by feature engineering built on data of the wrong granularity — a direct consequence of a badly modeled foundation.
// How to Acquire It
Take a real dataset you work with and redesign its schema from scratch. Ask yourself these questions:
- What are the entities?
- What do they relate to?
- What grain makes sense?
- What queries will run most frequently?
After that, read about dimensional modeling. Kimball's approach, detailed in his book The Data Warehouse Toolkit, remains a useful reference point.
# Skill #2: Performance Optimization
// What It Is
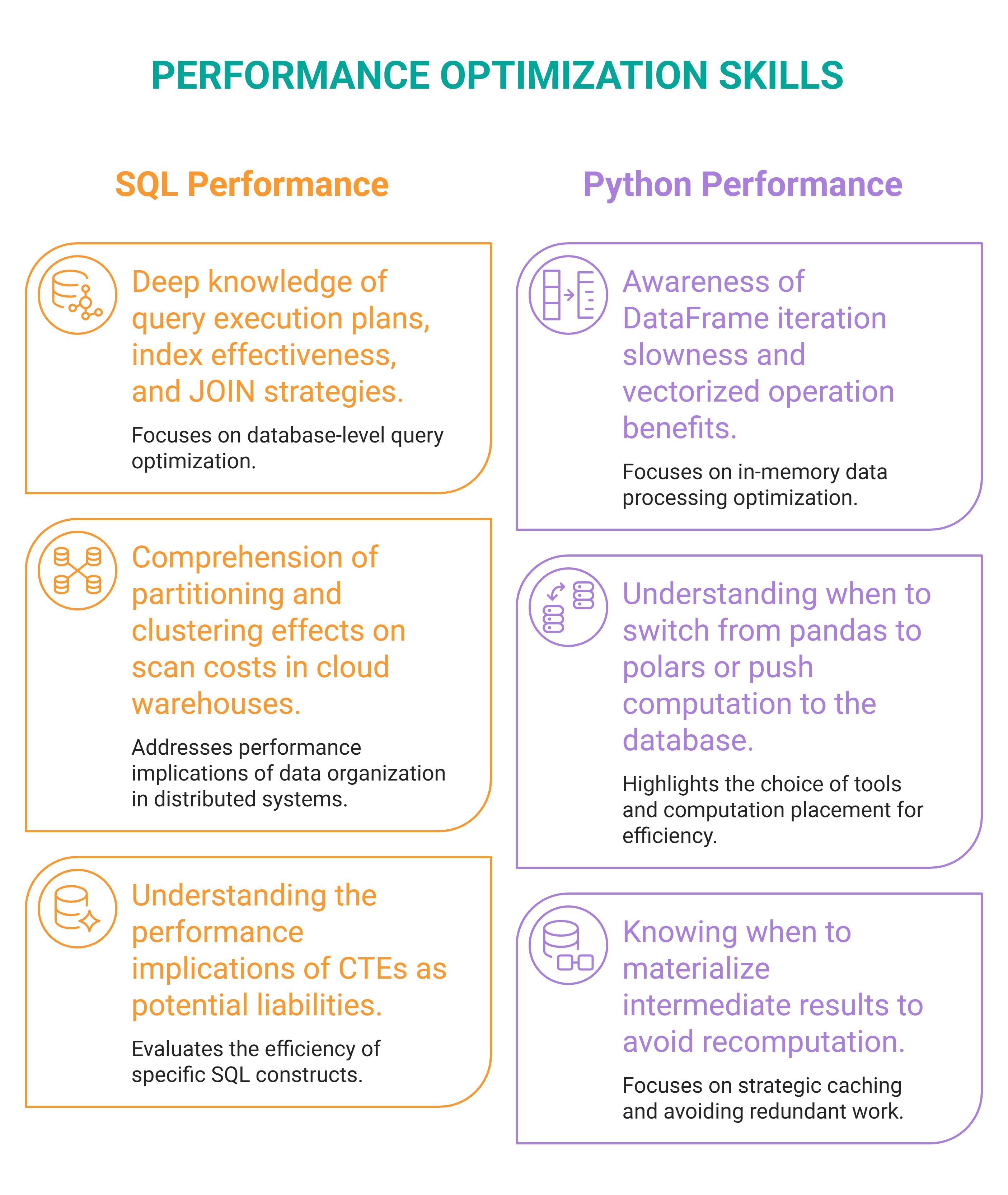
Performance optimization is understanding why a query runs the way it does and how to make it run faster, cheaper, or at greater scale. You can optimize SQL queries, but also Python pipelines and data workflows in general — data scientists increasingly own them end-to-end.
// Why It Became a Differentiator
First, data volumes have grown to the point where a correct but inefficient query can cost hundreds of dollars and time out in production.
Second, as mentioned earlier, data scientists now have to own much more of the pipeline than they did before. Your code has to be production-ready, not just runnable in Jupyter notebooks.
// How to Acquire It
Pick several complex SQL queries you've written, run EXPLAIN ANALYZE on them, and read what the query planner actually did. Then use that to optimize the query. You'll likely find at least one index, restructuring, or rewrite that improves each query.
For a slow Python pipeline, profile it. There are two main tools for time:
- cProfile: Run it with
python -m cProfile -s cumulative your_script.pyand look at the top of the output to see the functions consuming the most cumulative time. - line_profiler: Goes deeper by showing execution time line by line within a specific function. Use it once cProfile has told you which function is slow and you need to know why.
For memory, use memory_profiler.
Find the bottleneck — is it slow because a Python loop should be vectorized? Is data loaded into memory all at once instead of in chunks? — fix it, and measure the difference.
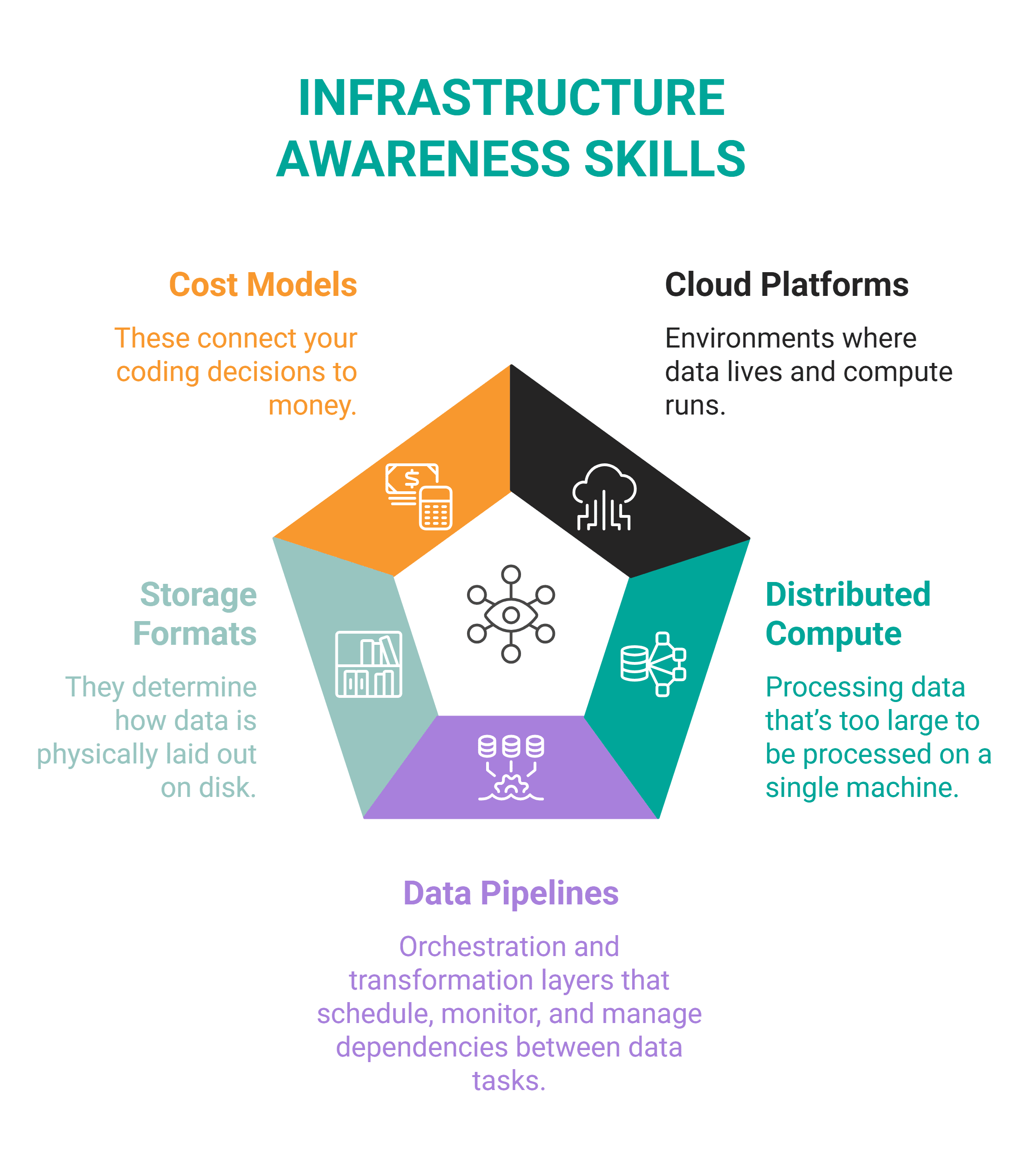
# Skill #3: Infrastructure Awareness
// What It Is
This skill means you understand the systems data lives in and moves through. These systems include cloud platforms, distributed compute, data pipelines, storage formats, and cost models.
You should know enough about the infrastructure to design systems that are deployable into it.
// Why It Became a Differentiator
Again, because a good chunk of a data engineer's job has fallen into a data scientist's lap. If you're dependent on data engineers for every infrastructure decision, you're effectively creating a bottleneck — and that's not something hiring managers are looking for.
Infrastructure awareness includes these main interconnected areas.
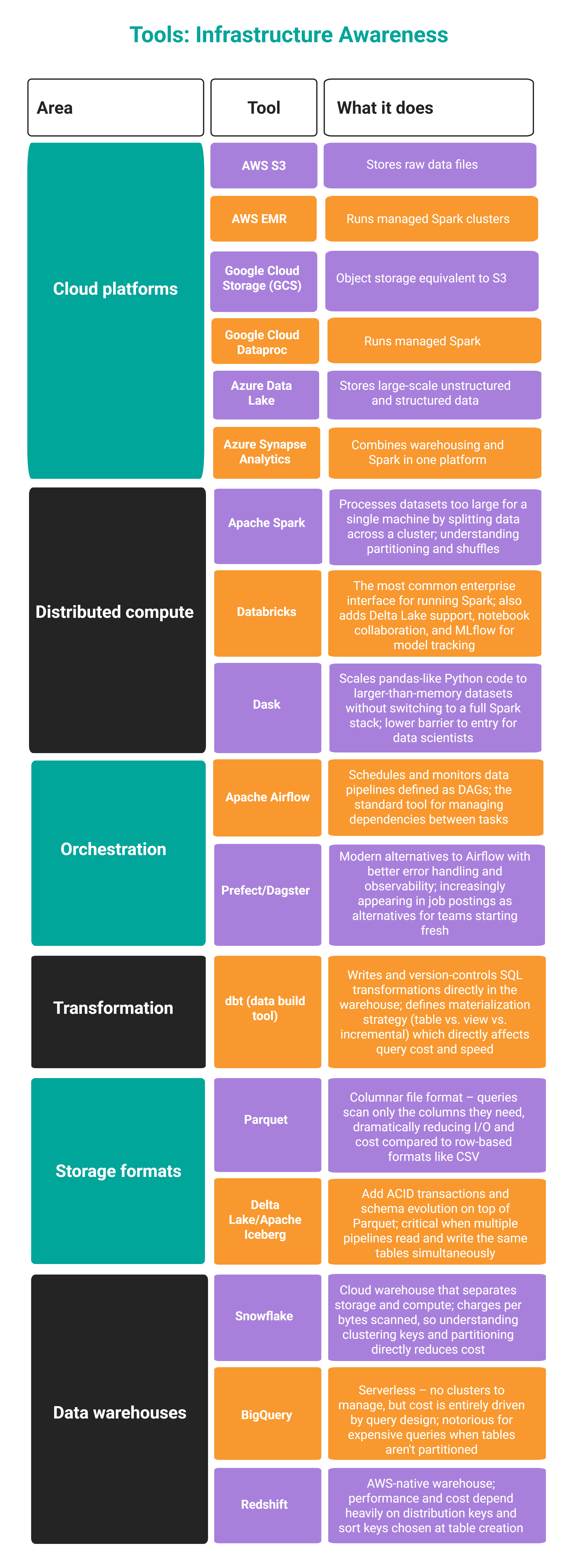
You'll most likely have to familiarize yourself with these tools.
// How to Acquire It
Arrange a session with your data engineering team. Sit with them and ask them to walk you through a pipeline end-to-end. Understand where data lives, how it's partitioned, and what happens when something breaks.
Then step up by building a small pipeline yourself: use a free cloud tier, understand the cost and execution metrics, then deliberately break the pipeline to understand how it fails.
# Skill #4: Designing RAG Systems, Evaluating LLM Outputs, and Running AI Experiments
// What It Is
This cluster of skills relates to practical AI work. You have to know how to design retrieval-augmented generation (RAG) systems (connecting LLMs to real data sources), build evaluation frameworks (measuring whether an LLM-powered feature is actually working), and run experiments on AI features.
// Why It Became a Differentiator
AI tools are the reason. They made it possible to build a RAG pipeline without extensive research knowledge. Frameworks like LangChain and LlamaIndex, combined with cloud-native vector databases, lowered the barrier significantly.
So the question is no longer whether it can be built — yes, it can be. But can it be built well, evaluated, and trusted in production? Answering that question is what you must be able to do: define metrics, design experiments, and measure outcomes.
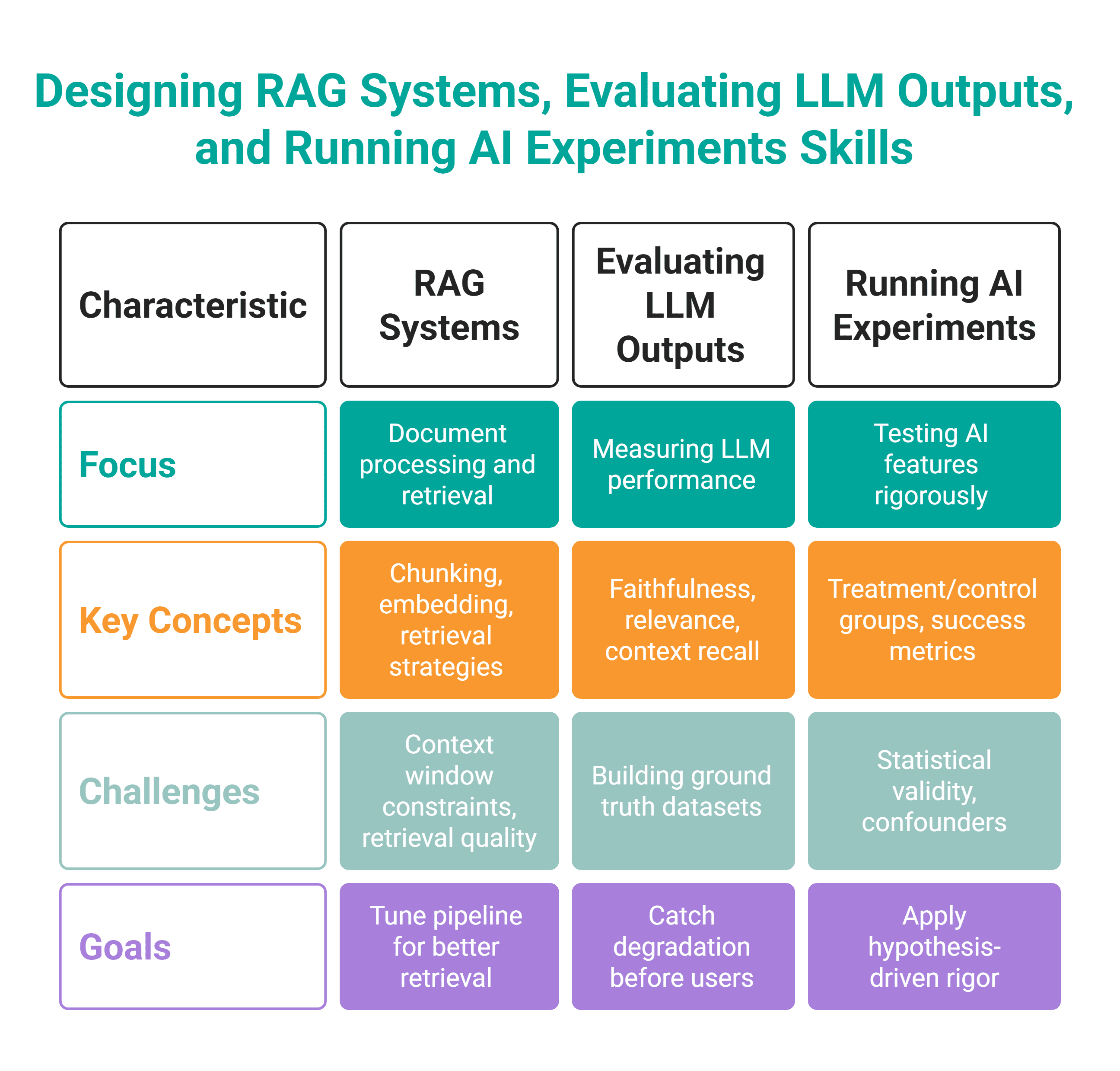
In applying these skills, you will use these tools.

// How to Acquire It
Find some interview questions to help you refine your AI thinking. Here are some examples from AI Product & GenAI interview questions on StrataScratch.
Example #1: Measuring AI Feature Rollout in Retail Stores
How would you measure the impact of an AI-powered inventory recommendation system being rolled out to a sample of retail stores? How would you design the experiment and account for store-level variation?
Example #2: RAG System Architecture
Describe how you would architect a RAG system from scratch. What components are needed, and how would you optimize retrieval quality?
After you've made your thinking clear, build a small RAG application: choose a domain, embed a document corpus, wire up retrieval, and evaluate the outputs using a structured metric.
Also, design an experiment: write out a hypothesis, define the metrics, and think through a valid test to evaluate it.
# Conclusion
The four skills — data modeling, performance optimization, infrastructure awareness, and practical AI skills — are what comprise the gap between you and the job market. Hopefully you won't fall into it. To ensure you don't, this article has included practical advice on how to acquire each one.
Nate Rosidi is a data scientist and in product strategy. He's also an adjunct professor teaching analytics, and is the founder of StrataScratch, a platform helping data scientists prepare for their interviews with real interview questions from top companies. Nate writes on the latest trends in the career market, gives interview advice, shares data science projects, and covers everything SQL.