SQL Window Functions Beyond Basics: Solving Real Business Problems
You know window functions, but do you know how to use them to solve business problems? You will after you read this article.

# Introduction
Most of you use SQL window functions, but you're only scratching the surface — a ROW_NUMBER() here, a SUM() OVER() there. The window functions' real potential is revealed when you apply them to harder problems. I will walk you through four patterns that show window functions at their most useful.

The examples are all real interview questions you can practice on StrataScratch.
# Running Totals
Calculating running totals is one of the most common business uses of window functions. The finance people absolutely love it! It is used to track cumulative monthly revenue, which then easily moves into calculating where you're at compared to the annual revenue target.
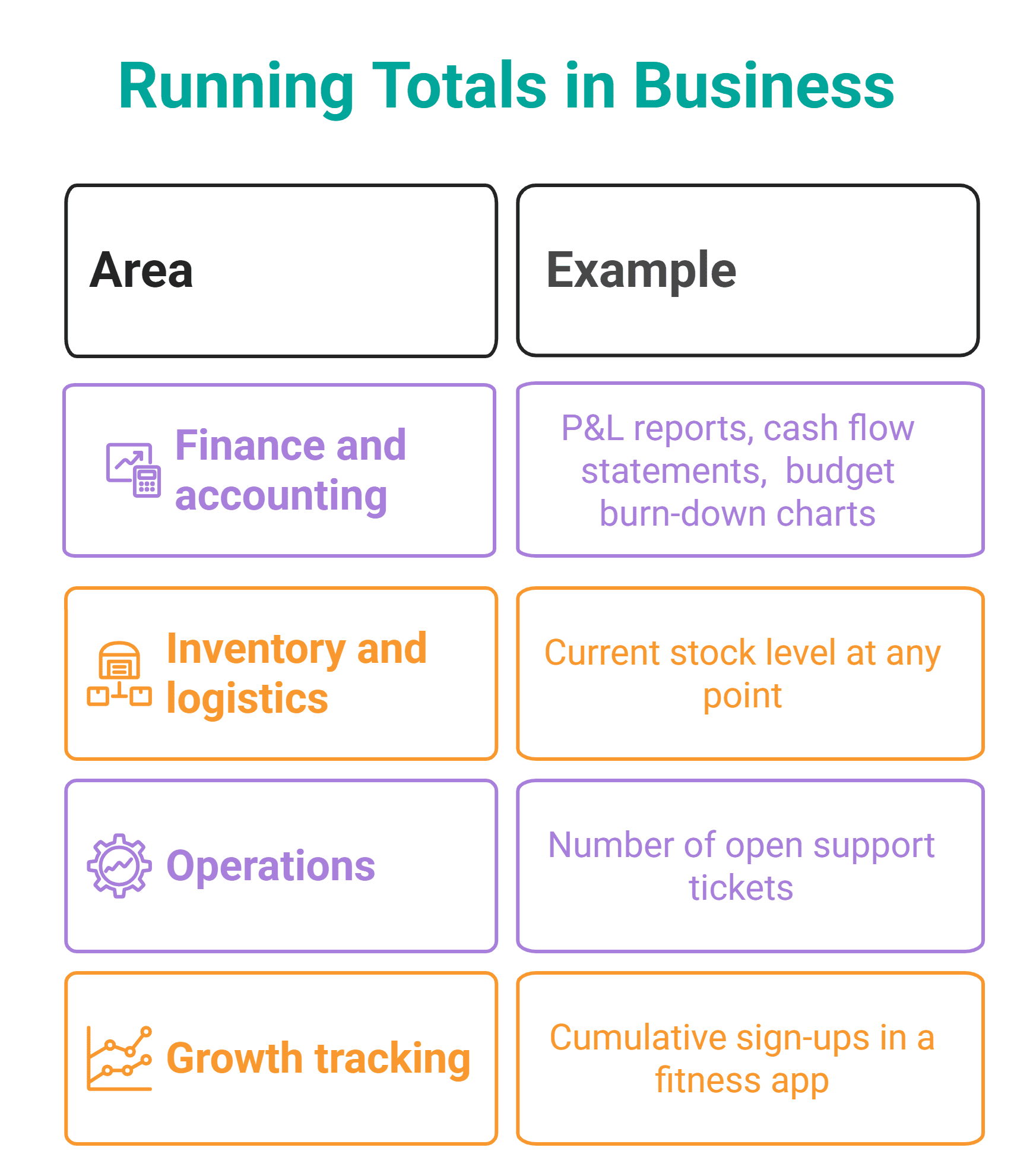
What makes this a window function problem is that, typically, you should include both the per-period value and the accumulating total in the same output. You can't use GROUP BY with SUM(), because that collapses individual rows. So, the obvious solution is using a window function, i.e., SUM() OVER().
// Example: Calculating Revenue Over Time
This Amazon question originally asks you to calculate the 3-month rolling average. However, we'll disregard that and calculate the cumulative revenue for each month.
Data: Here's the amazon_purchases table preview.
| user_id | created_at | purchase_amt |
|---|---|---|
| 10 | 2020-01-01 | 3742 |
| 11 | 2020-01-04 | 1290 |
| 12 | 2020-01-07 | 4249 |
| ... | ... | ... |
| 109 | 2020-10-24 | 1749 |
Code: The inner query turns dates into YYYY-MM format using TO_CHAR() and aggregates monthly revenue, filtering out returns with WHERE purchase_amt > 0.
The outer query applies the window function over those monthly totals we calculated. I don't specify an explicit frame clause (intentionally) in OVER(), so the window function defaults to RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW. That means the window is all rows preceding the current row, i.e., the month. In other words, the cumulative sum is: all previous months + the current month. Not surprisingly, that is a textbook definition of a cumulative sum.
SELECT t.month,
t.monthly_revenue,
SUM(t.monthly_revenue) OVER(ORDER BY t.month) AS cumulative_revenue
FROM (
SELECT TO_CHAR(created_at::DATE, 'YYYY-MM') AS month,
SUM(purchase_amt) AS monthly_revenue
FROM amazon_purchases
WHERE purchase_amt > 0
GROUP BY TO_CHAR(created_at::date, 'YYYY-MM')
ORDER BY TO_CHAR(created_at::date, 'YYYY-MM')
) t
ORDER BY t.month ASC;
Output:
| month | monthly_revenue | cumulative_revenue |
|---|---|---|
| 2020-01 | 26292 | 26292 |
| 2020-02 | 20695 | 46987 |
| 2020-03 | 29620 | 76607 |
| ... | ... | ... |
| 2020-10 | 15310 | 239869 |
# Gaps and Islands (Sessionization)
This pattern, too, involves sequential data, just like running totals, but it employs different window functions.
An island is a run of rows with the same condition, e.g., consecutive daily logins. A gap is the space between islands.
One of the most common real-world applications of this pattern is sessionization — grouping a raw event stream into sessions. A session is typically defined as a sequence of events from the same user where no gap between consecutive events exceeds some timeout (30 minutes is the web analytics standard).
Sessionization is commonly applied in product and data engineering. It is used anywhere you need to group raw event streams into meaningful units of activity.
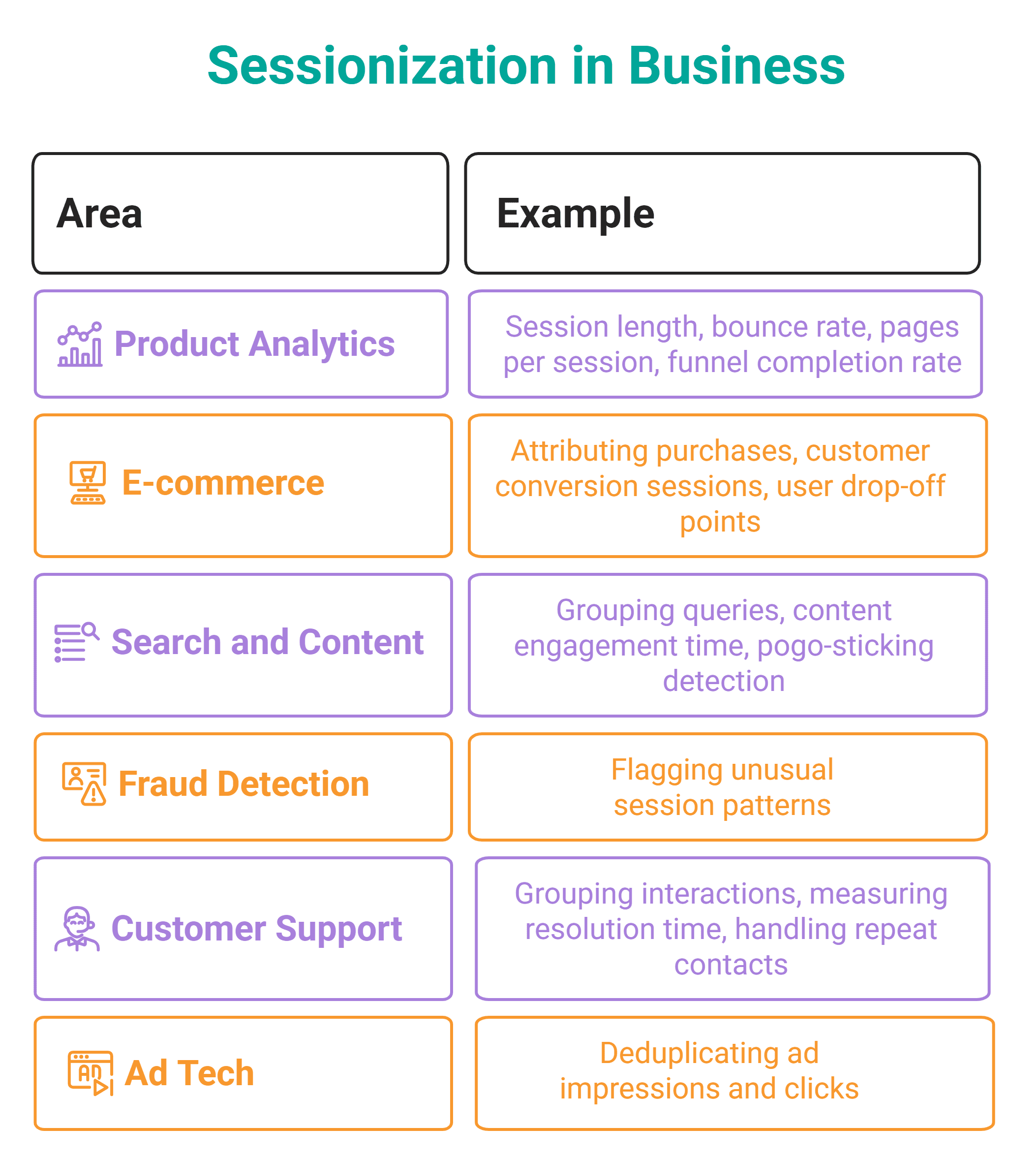
The classic detection in SQL consists of two steps:
LAG()orLEAD()— to compare each row to the one before or after it, and flag where a new streak starts.SUM(flag) OVER (PARTITION BY user ORDER BY date)— to accumulate flags into a streak ID, as it stays flat inside a streak and increments at every boundary.
// Example: Finding User Streaks
The question from LinkedIn and Meta interviews asks you to find the top three users with the longest platform visit streak until August 10, 2022. You should output all users with the top three longest streaks, if there is more than one user per streak length.
Data: The table is user_streaks.
| user_id | date_visited |
|---|---|
| u001 | 2022-08-01 |
| u001 | 2022-08-01 |
| u004 | 2022-08-01 |
| ... | ... |
| u005 | 2022-08-11 |
Code: The query is long, but it's neatly structured into CTEs, so it's easy to follow.
unique_visits: Removes duplicate visit records and caps the data at August 10, 2022.streak_flags: UsesLAG()to get the previous visit date per user and flags the row as0(a streak continuation if the gap is 1 day) or1(a new streak start for any other gap).streak_ids: Converts flags into streak group IDs using a cumulativeSUM().streak_lengths: Counts days per streak.longest_per_user: Keeps only each user's longest streak.ranked_lengths: Ranks distinct streak lengths.top_lengths: Finds the top 3 streak-length values.
The final SELECT ties everything together: it shows all users with the top three streaks and their respective streak lengths in days.
WITH unique_visits AS (
SELECT DISTINCT user_id, date_visited
FROM user_streaks
WHERE date_visited <= DATE '2022-08-10'),
streak_flags AS (
SELECT *,
CASE
WHEN date_visited
- LAG(date_visited) OVER (PARTITION BY user_id ORDER BY date_visited) = 1
THEN 0
ELSE 1
END AS new_streak
FROM unique_visits),
streak_ids AS (
SELECT *,
SUM(new_streak) OVER (PARTITION BY user_id ORDER BY date_visited) AS streak_id
FROM streak_flags),
streak_lengths AS (
SELECT user_id,
streak_id,
COUNT(*) AS streak_length
FROM streak_ids
GROUP BY user_id, streak_id),
longest_per_user AS (
SELECT user_id,
MAX(streak_length) AS streak_length
FROM streak_lengths
GROUP BY user_id),
ranked_lengths AS (
SELECT DISTINCT
streak_length,
DENSE_RANK() OVER (ORDER BY streak_length DESC) AS len_rank
FROM longest_per_user),
top_lengths AS (
SELECT streak_length
FROM ranked_lengths
WHERE len_rank <= 3)
SELECT u.user_id,
u.streak_length
FROM longest_per_user u
JOIN top_lengths t USING (streak_length)
ORDER BY u.streak_length DESC, u.user_id;
Output:
| user_id | streak_length |
|---|---|
| u004 | 10 |
| u005 | 10 |
| u003 | 5 |
| u001 | 4 |
| u006 | 4 |
# Cohort Analysis
A cohort is a group of users who share a starting event, for example, a first purchase, first login, or first subscription date. Analyzing cohorts is the foundation of retention reporting, as it answers the question of how many users came back after the starting event.
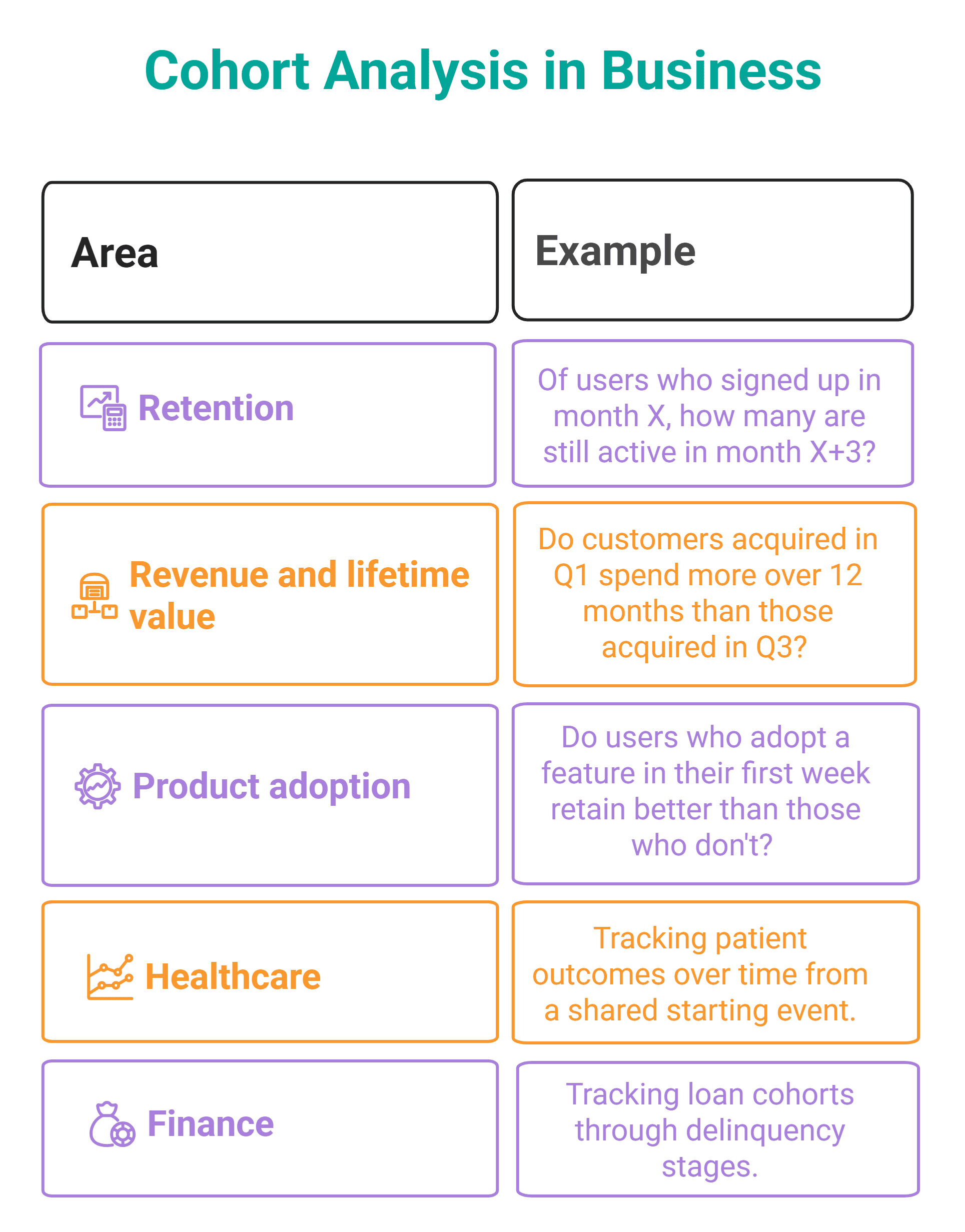
The key thing in cohort analysis is finding the cohort anchor in the user's activity history so that you can measure all subsequent activity against it.
Doing that in SQL boils down to three main window function approaches:
MIN(event_time) OVER (PARTITION BY user_id)— the most common pattern when the anchor is a date.FIRST_VALUE(attribute) OVER (PARTITION BY user_id ORDER BY event_time)— used when you need the anchor value itself, e.g., the first merchant or first product category.ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY event_time) = 1— used when you want to isolate the first event as a separate row and join it back to the full history rather than broadcasting it across all rows.
// Example: Counting First-Time Orders
Here's a DoorDash question. It requires you to calculate the number of orders and first-time orders (from a customer's perspective) each merchant has had. You should also exclude merchants that have not received any orders.
Data: The first table is named order_details.
| id | customer_id | merchant_id | order_timestamp | n_items | total_amount_earned |
|---|---|---|---|---|---|
| 8 | 1049 | 6 | 2022-01-14 01:00:28 | 5 | 16.3 |
| 7 | 1049 | 5 | 2022-01-14 11:50:29 | 4 | 2.16 |
| 22 | 1049 | 1 | 2022-01-14 22:46:54 | 8 | 2.63 |
| ... | ... | ... | ... | ... | ... |
| 39 | 1060 | 1 | 2022-01-16 22:27:30 | 11 | 15.41 |
The second table is merchant_details.
| id | name | category | zipcode |
|---|---|---|---|
| 1 | Treehouse Pizza | american | 92507 |
| 2 | Thai Lion | asian | 90017 |
| 3 | Meal Raven | fast food | 95204 |
| ... | ... | ... | ... |
| 7 | Taste Of Gyros | mediterranean | 94789 |
Code: The first CTE is where the cohort logic happens. I use the FIRST_VALUE() window function to attach the merchant from each customer's earliest order to every row in their order history. The result is a table where every order carries the label of which merchant that customer started with.
In the second CTE, I join the labels back to the full order history using a LEFT JOIN to ensure that merchants who received orders but were never anyone's first merchant still appear in the result. We use COUNT() and DISTINCT to count only the customers for whom that merchant was their first — that's your cohort size. With another COUNT(), you get the total number of orders. DISTINCT is required here, too, because the LEFT JOIN with first_order can produce duplicate order rows — since first_order retains one row per order (not per customer), a single order in order_details can match multiple rows in first_order for the same customer, inflating the count without it.
In the final SELECT, we join the number_of_customers CTE with merchant_details to bring in the merchant names.
WITH first_order AS (
SELECT customer_id,
FIRST_VALUE(merchant_id) OVER(PARTITION BY customer_id ORDER BY order_timestamp) AS first_merchant
FROM order_details),
number_of_customers AS (
SELECT merchant_id,
COUNT(DISTINCT f.customer_id) AS first_time_orders,
COUNT(DISTINCT id) AS total_number_of_orders
FROM order_details d
LEFT JOIN first_order f ON d.merchant_id = f.first_merchant
GROUP BY 1)
SELECT name,
total_number_of_orders,
first_time_orders
FROM number_of_customers
JOIN merchant_details ON number_of_customers.merchant_id = merchant_details.id;
Output:
| name | total_number_of_orders | first_time_orders |
|---|---|---|
| Treehouse Pizza | 8 | 1 |
| Thai Lion | 14 | 7 |
| Meal Raven | 12 | 0 |
| Burger A1 | 4 | 0 |
| Sushi Bay | 7 | 3 |
| Tacos You | 7 | 1 |
# Percentile and Ranking Analysis
Aggregate functions tell you the average. Window-based ranking functions tell you the distribution, and distributions are where the interesting business questions live. Is your 90th percentile order value unusually high, suggesting a few large buyers are skewing revenue? Are the bottom 25% of sales reps clustered close to the median or far below?
NTILE(n) divides rows into n roughly equal buckets. PERCENT_RANK() expresses each row's rank as a value between 0 and 1. CUME_DIST() tells you what fraction of rows have a value less than or equal to the current row. And PERCENTILE_CONT() computes the actual value at a given percentile threshold — useful when you want to filter based on a dynamic cutoff rather than rank within a result set.
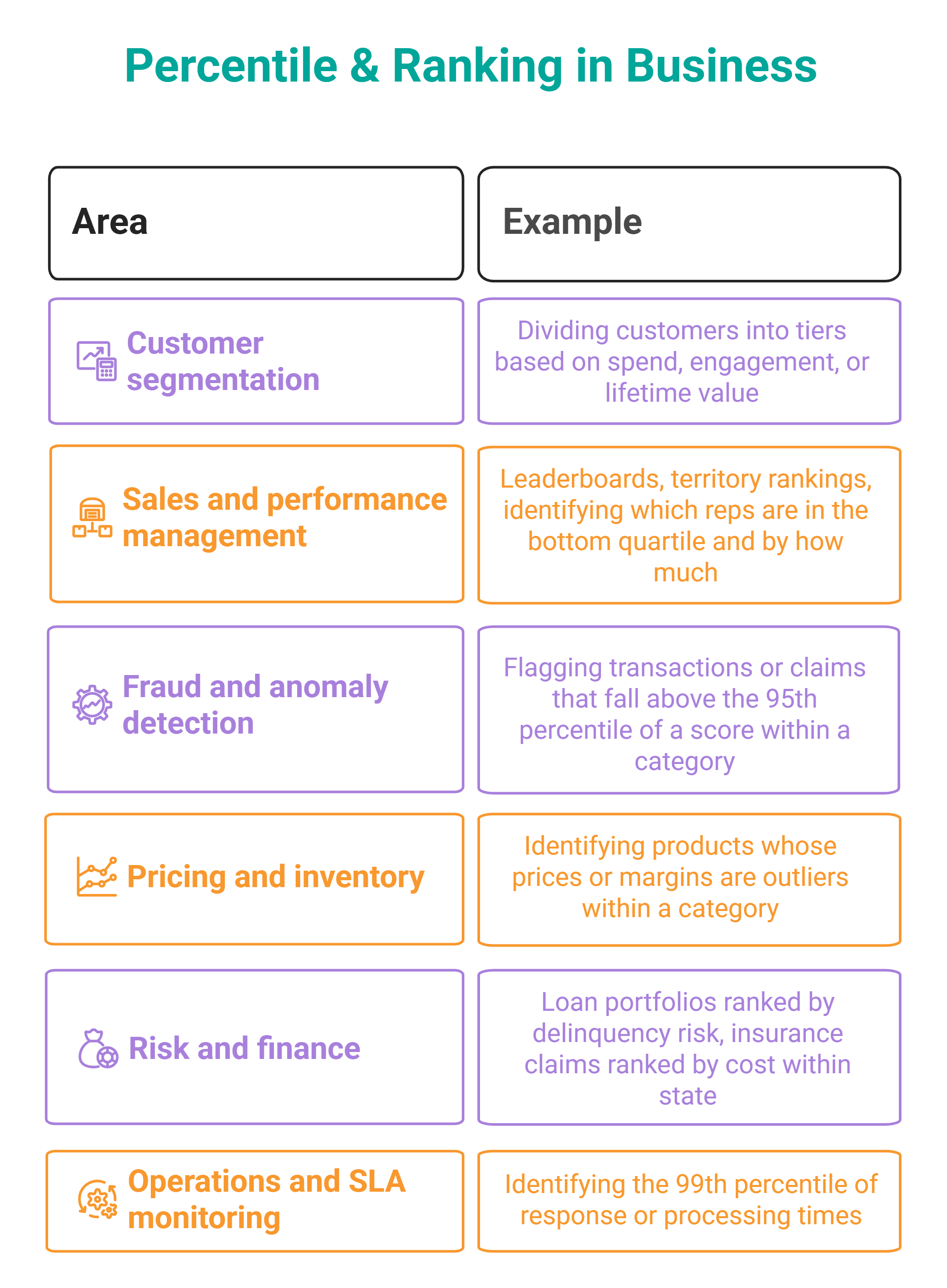
// Example: Identifying Top Percentile Fraud
Here's one by Google and Netflix. They want you to identify the most suspicious claims in each state. The assumption is that the top 5% of claims in each state are potentially fraudulent.
Data: The table is named fraud_score.
| policy_num | state | claim_cost | fraud_score |
|---|---|---|---|
| ABCD1001 | CA | 4113 | 0.61 |
| ABCD1002 | CA | 3946 | 0.16 |
| ABCD1003 | CA | 4335 | 0.01 |
| ... | ... | ... | ... |
| ABCD1400 | TX | 3922 | 0.59 |
Code: In the code, PERCENTILE_CONT(0.95) computes the interpolated value at the 95th percentile of fraud scores within each state.
In the following SELECT statement, the CTE is joined with the original table so every claim can be compared against the threshold for its own state. Claims at or above that value make the cut.
WITH state_percentiles AS (
SELECT state,
PERCENTILE_CONT(0.95) WITHIN GROUP (ORDER BY fraud_score) AS p95
FROM fraud_score
GROUP BY state)
SELECT f.policy_num,
f.state,
f.claim_cost,
f.fraud_score
FROM fraud_score f
JOIN state_percentiles sp
ON f.state = sp.state
WHERE f.fraud_score >= sp.p95;
Output:
| policy_num | state | claim_cost | fraud_score |
|---|---|---|---|
| ABCD1016 | CA | 1639 | 0.96 |
| ABCD1021 | CA | 4898 | 0.95 |
| ABCD1027 | CA | 2663 | 0.99 |
| ... | ... | ... | ... |
| ABCD1398 | TX | 3191 | 0.98 |
# Conclusion
These four patterns share a common philosophy: do the work in the database, in a single pass where possible, using the full expressive power of the SQL window specification.
What makes window functions genuinely powerful isn't any single function in isolation. It's the composability: you can chain CTEs, apply multiple window functions in the same SELECT, and build complex analytical logic that reads nearly like a description of the business problem itself.
Nate Rosidi is a data scientist and in product strategy. He's also an adjunct professor teaching analytics, and is the founder of StrataScratch, a platform helping data scientists prepare for their interviews with real interview questions from top companies. Nate writes on the latest trends in the career market, gives interview advice, shares data science projects, and covers everything SQL.