10 Agentic AI Concepts Explained in Under 10 Minutes
An AI agent combines a large language model for reasoning, access to tools or APIs for action, memory to retain context and a control loop to decide what happens next.

Image by Author
Introduction
Agentic AI refers to AI systems that can make decisions, take actions, use tools, and iterate toward a goal with limited human intervention. Instead of answering a single prompt and stopping, an agent evaluates the situation, chooses what to do next, executes actions, and continues until the objective is achieved.
An AI agent combines a large language model for reasoning, access to tools or APIs for action, memory to retain context, and a control loop to decide what happens next. If you remove the loop and the tools, you no longer have an agent. You have a chatbot.
You must be wondering, what’s the difference from traditional LLM interaction? It is simple: traditional LLM interaction is request and response. You ask a question. The model generates text. The process ends.
Agentic systems behave differently:
| Standard LLM Prompting | Agentic AI |
|---|---|
| Single input → single output | Goal → reasoning → action → observation → iteration |
| No persistent state | Memory across steps |
| No external action | API calls, database queries, code execution |
| User drives every step | System decides intermediate steps |
# Understanding Why Agentic Systems Are Growing Fast
There are so many reasons why agentic systems are growing so fast, but there are three important forces driving adoption: LLM capability growth, explosive enterprise adoption, and open-source agent frameworks.
// 1. Growing LLM Capabilities
Transformer-based models, introduced in the paper Attention Is All You Need by researchers at Google Brain, made large-scale language reasoning practical. Since then, models like OpenAI’s GPT series have added structured tool calling and longer context windows, enabling reliable decision loops.
// 2. Experiencing Explosive Enterprise Adoption
According to McKinsey & Company’s 2023 report on generative AI, roughly one-third of organizations were already using generative AI regularly in at least one business function. Adoption creates pressure to move beyond chat interfaces into automation.
// 3. Leveraging Open-source Agent Frameworks
Public repositories such as LangChain, AutoGPT, CrewAI, and Microsoft AutoGen have lowered the barrier to building agents. Developers can now compose reasoning, memory, and tool orchestration without building everything from scratch.
In the next 10 minutes, we will quickly touch base with 10 practical concepts that power modern agentic systems, such as LLMs as reasoning engines, tools and function calling, memory systems, planning and task decomposition, execution loops, multi-agent collaboration, guardrails and safety, evaluation and observability, deployment architecture, and production readiness patterns.
Before building agents, you need to understand the architectural building blocks that make them work. Let’s start with the reasoning layer that drives everything.
# 1. LLMs As Reasoning Engines, Not Just Chatbots
If you strip an agent down to its core, the large language model is the cognitive layer. Everything else—tools, memory, orchestration—wraps around it.
The breakthrough that made this possible was the Transformer architecture introduced in the paper Attention Is All You Need by researchers at Google Brain. The paper showed that attention mechanisms could model long-range dependencies more effectively than recurrent networks.
That architecture is what powers modern models that can reason across steps, synthesise information, and decide what to do next.
Early LLM usage looked like this:

A major shift happened when OpenAI introduced structured function calling in GPT-4 models. Instead of guessing how to call APIs, the model can now emit structured JSON that matches a predefined schema.
This change is subtle but important. It turns free-form text generation into structured decision output. That is the difference between a suggestion and an executable instruction.
// Applying Chain-of-thought Reasoning
Another key development is chain-of-thought prompting, introduced in research by Google Research. The paper demonstrated that explicitly prompting models to reason step by step improves performance on complex reasoning tasks.
In agentic systems, reasoning depth matters because:
- Multi-step goals require intermediate decisions
- Tool selection depends on interpretation
- Errors compound across steps
If the reasoning layer is shallow, the agent becomes unreliable. Consider a goal: “Analyze competitors and draft a positioning strategy.”
A shallow system might produce generic advice. But a reasoning-driven agent might:
- Search for competitor data
- Extract structured attributes
- Compare pricing models
- Identify gaps
- Draft tailored positioning
That requires planning, evaluation, and iterative refinement.
Now that we understand the cognitive layer, we need to look at how agents actually interact with the outside world.
# 2. Utilizing Tools And Function Calling
Reasoning alone does nothing unless it can produce action. Agents act through tools. A tool can be a REST API, a database query, a code execution environment, a search engine, or a file system operation.
Function calling allows you to define a tool with:
- A name
- A description
- A JSON schema specifying inputs
The model decides when to call the function and generates structured arguments that match the schema. This eliminates guesswork. Instead of parsing messy text output, your system receives validated JSON.
// Validating JSON Schemas
The schema enforces:
- Required parameters
- Data types
- Constraints
For example:
{
"name": "get_weather",
"description": "Retrieve current weather for a city",
"parameters": {
"type": "object",
"properties": {
"city": { "type": "string" },
"unit": { "type": "string", "enum": ["celsius", "fahrenheit"] }
},
"required": ["city"]
}
}
The model cannot invent extra fields if strict validation is applied and this helps to reduce runtime failures.
// Invoking External APIs
When the model emits:
{
"name": "get_weather",
"arguments": {
"city": "London",
"unit": "celsius"
}
}
Your application:
- Parses the JSON
- Calls a weather API such as OpenWeatherMap
- Returns the result to the model
- The model incorporates the data into its final answer
This structured loop dramatically improves reliability compared to free-text API calls. For working implementations of tool and agent frameworks, see OpenAI function calling examples, LangChain tool integrations, and the Microsoft multi-agent framework.
We have now covered the reasoning engine and the action layer. Next, we will examine memory, which allows agents to persist knowledge across steps and sessions.
# 3. Implementing Memory Systems
An agent that cannot remember is forced to guess. Memory is what allows an agent to stay coherent across multiple steps, recover from partial failures, and personalize responses over time. Without memory, every decision is stateless and brittle.
Not all memory is the same. Different layers serve different roles.
| Memory Type | Description | Typical Lifetime | Use Case |
|---|---|---|---|
| In-context | Prompt history inside the LLM window | Single session | Short conversations |
| Episodic | Structured session logs or summaries | Hours to days | Multi-step workflows |
| Vector-based | Semantic embeddings in a vector store | Persistent | Knowledge retrieval |
| External database | Traditional SQL or NoSQL storage | Persistent | Structured data like users, orders |
// Understanding Context Window Limitations
Large language models operate within a fixed context window. Even with modern long context models, the window is finite and expensive. Once you exceed it, earlier information gets truncated or ignored.
This means:
- Long conversations degrade over time
- Large documents cannot be processed in full
- Multi-step workflows lose earlier reasoning
Agents solve this by separating memory into structured layers rather than relying entirely on prompt history.
// Building Long-term Memory with Embeddings
Long-term memory in agent systems is usually powered by embeddings. An embedding converts text into a high-dimensional numerical vector that captures semantic meaning.
When two pieces of text are semantically similar, their vectors are close in vector space. That makes similarity search possible.
Instead of asking the model to remember everything, you:
- Convert text into embeddings
- Store vectors in a database
- Retrieve the most relevant chunks when needed
- Inject only relevant context into the prompt
This pattern is called Retrieval-Augmented Generation, introduced in research by Facebook AI, now part of Meta AI. RAG reduces hallucinations because the model is grounded in retrieved documents rather than relying purely on parametric memory.
// Using Vector Databases
A vector database is optimized for similarity search across embeddings. Instead of querying by exact match, you query by semantic closeness. Popular open-source vector databases include Chroma, Weaviate, and Milvus.
# 4. Planning And Decomposing Tasks
A single prompt can handle simple tasks. Complex goals require decomposition. For example, if you tell an agent:
Research three competitors, compare pricing, and recommend a positioning strategy
That is not one action. It is a chain of dependent subtasks. Planning is how agents break large objectives into manageable steps.
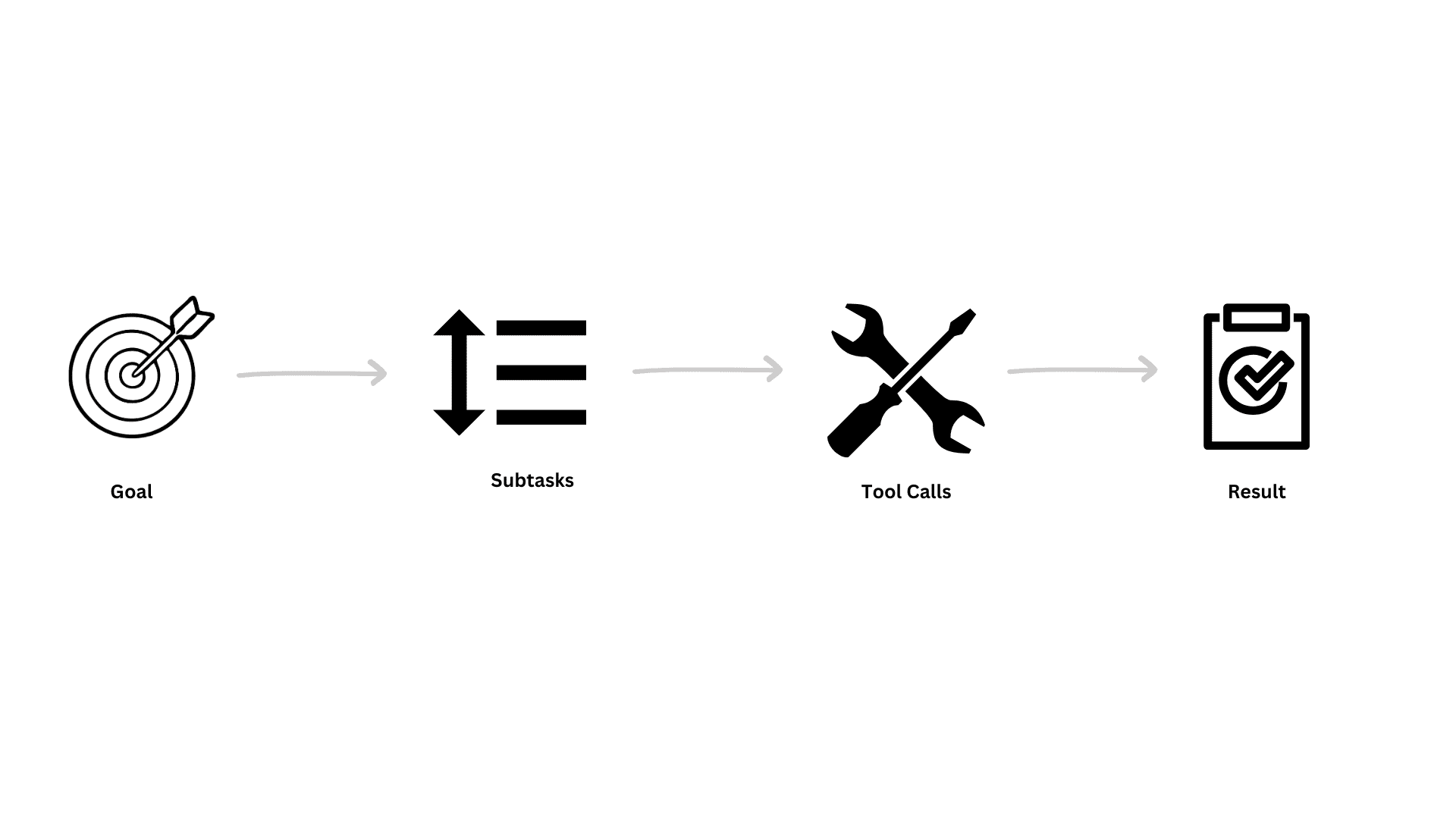
This flow turns abstract objectives into executable sequences. Hallucinations often happen when the model tries to generate an answer without grounding or intermediate verification.
Planning reduces this risk because:
- Subtasks are validated step by step
- Tool outputs provide grounding
- Errors are caught earlier
- The system can backtrack
// Reasoning And Acting with ReAct
One influential approach is ReAct, introduced in research by Princeton University and Google Research.
ReAct mixes reasoning and acting: Think, Act, Observe, Think again. This tight loop allows agents to refine decisions based on tool outputs. Instead of generating a long plan upfront, the system reasons incrementally.
// Implementing Tree Of Thoughts
Another approach is Tree of Thoughts, introduced by researchers at Princeton University. Rather than committing to a single reasoning path, the model explores multiple branches, evaluates them, and selects the most promising one.
This approach improves performance on tasks that require search or strategic planning.
We now have reasoning, action, memory, and planning. Next, we will examine execution loops and how agents autonomously iterate until a goal is achieved.
# 5. Running Autonomous Execution Loops
An agent is not defined by intelligence alone. It is defined by persistence. Autonomous execution loops allow an agent to continue working toward a goal without waiting for human prompts at every step. This is where systems move from assisted generation to semi-autonomous operation.
The core loop:
- Observe: Gather input from the user, tools, or memory
- Think: Use the LLM to reason about the next best action
- Act: Call a tool, update memory, or return a result
- Repeat: Continue until a termination condition is met
This pattern appears in ReAct style systems and in practical open-source agents like AutoGPT and BabyAGI.
// Defining Stop Conditions
An autonomous loop must have explicit termination rules. Some of the common stop conditions include:
- Goal achieved
- Maximum iteration count reached
- Cost threshold exceeded
- Tool failure threshold reached
- Human approval required
Without stop conditions, agents can enter runaway loops. Early versions of AutoGPT showed how quickly costs could escalate without strict boundaries.
// Integrating Feedback Cycles
Iteration alone is not enough. The system must evaluate outcomes. For example:
- If a search query returns no results, reformulate it
- If an API call fails, retry with adjusted parameters
- If a generated plan is incomplete, expand the missing steps
Feedback introduces adaptability. Without it, loops become infinite repetition. Production systems often implement:
- Confidence scoring
- Result validation
- Error classification
- Retry limits
This prevents the agent from blindly continuing.
# 6. Designing Multi-agent Systems
Multi-agent systems distribute responsibility across specialized agents instead of forcing one model to handle everything. One agent can reason. Multiple agents can collaborate.
// Specializing Roles
Instead of a single generalist agent, you can define roles such as Researcher, Planner, Critic, Executor, Reviewer, etc. Each agent has:
- A distinct system prompt
- Specific tool access
- Clear responsibilities
// Coordinating Agents
In structured multi-agent setups, a coordinator agent manages workflows such as assigning tasks, aggregating results, resolving conflicts, and determining completion.
Microsoft's AutoGen framework demonstrates this orchestration approach.
// Implementing Debate Frameworks
Some systems use debate-style collaboration. This is where two agents generate competing solutions, then a third agent evaluates them, and finally, the best answer is selected or refined. This technique reduces hallucination and improves reasoning depth by forcing justification and critique.
// Understanding CrewAI Architecture
CrewAI is a popular framework for role-based multi-agent workflows. It structures agents into “crews” where:
- Each agent has a defined goal
- Tasks are sequenced
- Outputs are passed between agents
// Comparing Single Agent Vs Multi-agent Architecture
| Single Agent System | Multi-Agent System |
|---|---|
| One reasoning loop | Multiple coordinated loops |
| Centralized decision making | Distributed decision making |
| Simpler architecture | More complex architecture |
| Easier debugging | Harder observability |
| Limited specialization | Clear role separation |
# 7. Implementing Guardrails And Safety
Autonomy is powerful, but without constraints, it can be dangerous. Agents operate with broad capabilities: calling APIs, modifying databases, and executing code. Guardrails are essential to prevent misuse, errors, and unsafe behavior.
// Mitigating Prompt Injection Risks
Prompt injection occurs when an agent is tricked into executing malicious or unintended commands. For example, an attacker might craft a prompt that tells the agent to reveal secrets or call unauthorised APIs.
Here are some preventive measures:
- Sanitize input before passing it to the LLM
- Use strict function calling schemas
- Limit tool access to trusted operations
// Preventing Tool Misuse
Agents can mistakenly use tools incorrectly, such as:
- Passing invalid parameters
- Triggering destructive actions
- Performing unauthorized queries
Structured function calling and validation schemas reduce these risks.
// Implementing Sandboxing
Execution sandboxing isolates the agent from sensitive systems. Sandboxes help to:
- Limit file system access
- Restrict network calls
- Enforce CPU/memory quotas
Even if an agent behaves unexpectedly, sandboxing prevents catastrophic outcomes.
// Validating Outputs
Every agent action should be validated before committing results. Common checks include:
- Confirm API responses match expected schema
- Verify calculations or summaries are consistent
- Flag or reject unexpected outputs
# 8. Evaluating And Observing Systems
It is said that if you cannot measure it, you cannot trust it. Observability is the backbone of safe, reliable agentic systems.
// Measuring Agent Performance Metrics
Agents introduce operational complexity. Useful metrics include:
- Latency: How long each reasoning or tool call takes
- Tool success rate: How often tool calls produce valid results
- Cost: API or compute usage
- Task completion rate: Percentage of goals fully achieved
// Using Tracing Frameworks
Observability frameworks capture detailed agent activity:
- Logs: Track decisions, tool calls, outputs
- Traces: Sequence of actions leading to a final result
- Metrics dashboards: Monitor success rates, latency, and failures
Public repositories include LangSmith and OpenTelemetry. With proper tracing, you can audit agent decisions, reproduce issues, and refine workflows.
// Benchmarking LLM Evaluation
Benchmarks allow you to track reasoning and output quality:
- MMLU: Multi-task language understanding
- GSM8K: Mathematical reasoning
- HumanEval: Code generation
# 9. Deploying Agents
Building a prototype is one thing. Running an agent reliably in production requires careful deployment planning. Deployment ensures agents can operate at scale, handle failures, and control costs.
// Building the Orchestration Layer
The orchestration layer coordinates reasoning, memory, and tools. It receives user requests, delegates subtasks to agents, and aggregates results. Popular frameworks like LangChain, AutoGPT, and AutoGen provide built-in orchestrators.
Key responsibilities:
- Task scheduling
- Role assignment for multi-agent systems
- Monitoring ongoing loops
- Handling retries and errors
// Managing Asynchronous Task Queues
Agents often need to wait for tool outputs or long-running tasks. Async queues such as Celery or RabbitMQ allow agents to continue processing without blocking.
// Implementing Caching
Repeated queries or frequent memory lookups benefit from caching. Caching reduces latency and API costs.
// Monitoring Costs
Autonomous agents can quickly rack up expenses due to multiple LLM calls per task, frequent tool execution and long-running loops. Integrating cost monitoring alerts you when thresholds are exceeded. Some systems even adjust behavior dynamically based on budget limits.
// Recovering from Failures
Robust agents must anticipate failures such as network outages, tool errors, and model timeouts. To tackle this, here are some common strategies:
- Retry policies
- Circuit breakers for failing services
- Fallback agents for critical tasks
# 10. Architecting Real-world Systems
Real-world deployment is more than just running code. It’s about designing a resilient, observable, and scalable system that integrates all the agentic AI building blocks.
A typical production architecture includes:
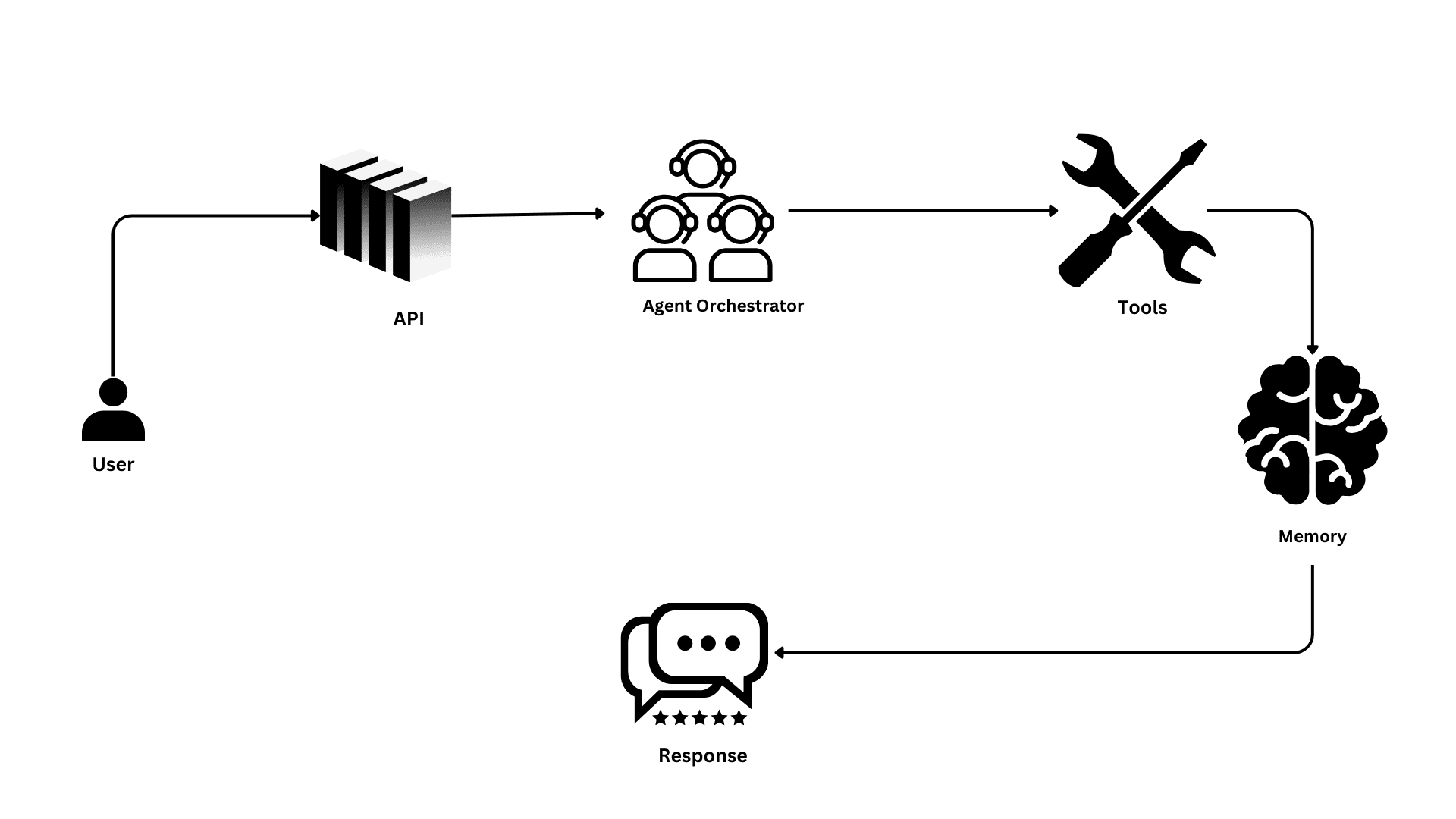
The orchestrator sits at the center, coordinating:
- Agent loops
- Memory access
- Tool invocation
- Result aggregation
This flow ensures agents can operate reliably under variable load and complex workflows.
# Concluding Remarks
Building an agentic system is achievable if you follow a stepwise approach. You can:
- Start with single-tool agents: Begin by implementing an agent that calls a single API or tool. This allows you to validate reasoning and execution loops without complexity
- Add memory: Integrate in-context, episodic, or vector-based memory. Retrieval-Augmented Generation improves grounding and reduces hallucinations
- Add planning: Introduce hierarchical or stepwise task decomposition. Planning enables multi-step workflows and improves output reliability
- Add observability: Implement logging, tracing, and performance metrics. Guardrails and monitoring make your agents safe and trustworthy
Agentic AI is becoming practical now, thanks to LLM reasoning, structured tool use, memory architectures, and multi-agent frameworks. By combining these building blocks with careful design and observability, you can create autonomous systems that act, reason, and collaborate reliably in real-world scenarios.
Shittu Olumide is a software engineer and technical writer passionate about leveraging cutting-edge technologies to craft compelling narratives, with a keen eye for detail and a knack for simplifying complex concepts. You can also find Shittu on Twitter.