Exclusive: Interview with Chris Wiggins, NYTimes Chief Data Scientist
New York Times Chief Data Scientist Chris Wiggins on the transformation of digital journalism, key Data Science skills, favorite tools, why better wrong than nice, and how Thomas Jefferson is very relevant today.
By Gregory Piatetsky,
@kdnuggets.
Last Halloween, Chris Wiggins, the New York Times Chief Data Scientist, invited me to come to his talk at Harvard.
Unfortunately, I could not attend at the time, but I saw his excellent slides and video of the talk, and we started a conversation. As a regular reader of the NYTimes since my NYU grad school days, I loved the chance to learn more about the NYTimes digital journalism today, and the result is this interview.
New York Times (along with other publishers) is now going through a period of declining ad revenues but also a big, scary, and exciting transformation, and I hope that Data Science will help it to adapt and prosper in the new era.
 Christopher H. Wiggins,
@chrishwiggins, is an associate professor of applied mathematics at Columbia University,
the first Chief Data Scientist at The New York Times,
and co-founder and co-organizer of hackNY hackNY.org .
Christopher H. Wiggins,
@chrishwiggins, is an associate professor of applied mathematics at Columbia University,
the first Chief Data Scientist at The New York Times,
and co-founder and co-organizer of hackNY hackNY.org .
At Columbia he is faculty in the Department of Applied Physics and Applied Mathematics, a founding member of the Department of Systems Biology, a founding member of the Data Science Institute datascience.columbia.edu/ , affiliated faculty in the Department of Statistics, and an instructor in the School of Journalism. His research focuses on applications of machine learning to real-world data, particularly biology.
Prior to joining the faculty at Columbia he was a Courant Instructor at NYU and earned his PhD at Princeton University in theoretical physics. In 2014 he was elected Fellow of the American Physical Society and is a recipient of Columbia's Avanessians Diversity Award.
Gregory Piatetsky, Q1. A major part of your role is understanding NYT subscribers (including me) better. Can you give some examples of insights that helped increase revenue? Can Data Science come up with some major insights that transform NYT business?
 Christopher H. Wiggins:
Absolutely! I think of data science teams as performing
principally either Data Product or Data Impact functions.
We've done both, in that we're building a number of data products (so
far just for internal use at the NYT) as well as trying to
impact roadmaps of other groups. Impact comes from learning
models which are not only predictive but also interpretable.
Christopher H. Wiggins:
Absolutely! I think of data science teams as performing
principally either Data Product or Data Impact functions.
We've done both, in that we're building a number of data products (so
far just for internal use at the NYT) as well as trying to
impact roadmaps of other groups. Impact comes from learning
models which are not only predictive but also interpretable.
For example, if we build a model which predicts individual subscribers' likelihood of canceling, we're interested not only in the machine learning part (does the model predict accurately the at risk individuals), which is an engineering win, but also in the data science win of revealing risky behaviors.
Identifying these suggests changes to product or marketing, which then can be executed and tested.
To find out more about specific examples, I encourage you to click here: developers.nytimes.com/careers/
GP: Q2. What are the key skills on your Data Science team and what are their/your favorite tools and packages for data analysis and visualization?
CHW: Key skills are being good listeners, good communicators, sufficient creativity and familiarity with machine learning methods to know how to reframe domain questions as machine learning tasks, the kind of self-skepticism science demands, and the desire to serve as a culture broker between the data and the demands of our collaborators throughout the company.
Regarding tools: Everything we do is open source when it comes to the machine learning, principally Python, sometimes R. The data engineering uses a variety of tools depending on what data we're querying, but typically map reduce, elastic map-reduce, or SQL as needed.
GP: Q3. Are there interesting NYT APIs that are open to the public?
CHW: Absolutely! NYT has been building APIs since 2008, ancient history. See developer.nytimes.com/docs .
GP: these include
GP: Q4. Can you elaborate on your point better wrong than "nice" in your Harvard Halloween talk?
Sure. I often observe a "cluster first, ask questions later" approach when people face new data. This was particularly pervasive in computational biology in the early days of microarray data. With unsupervised learning it's often difficult to asses which of two clustering approaches is "better", meaning that I don't sleep well at night because I'm wondering if I could have clustered differently and found something else.
 Instead I prefer first to think through what I really want to
learn from the data, which usually means that there's some
particular covariate I want to predict from the others.
So I try to hunt for supervised learning tasks rather than unsupervised learning
tasks. In supervised learning or "predictive analytics" I can
assess more clearly whether my model makes accurate predictions
on held out data, which gives me a way of saying whether my
model is "wrong."
I also mean this as reference to the famous dismissal by Wolfgang Pauli:
(cf. en.wikipedia.org/wiki/Not_even_wrong )
Instead I prefer first to think through what I really want to
learn from the data, which usually means that there's some
particular covariate I want to predict from the others.
So I try to hunt for supervised learning tasks rather than unsupervised learning
tasks. In supervised learning or "predictive analytics" I can
assess more clearly whether my model makes accurate predictions
on held out data, which gives me a way of saying whether my
model is "wrong."
I also mean this as reference to the famous dismissal by Wolfgang Pauli:
(cf. en.wikipedia.org/wiki/Not_even_wrong )
GP: Q5. NYT is known for excellent data visualization. Is that part of your role, and if so, do you have any advice / guidelines / tools to help present data better?
CHW: Our group is on the engineering side rather than in the newsroom, separate from the (awesome) graphics group. Certainly we benefit from their expertise, especially since we use a lot of d3, which was developed by the NYT "digital superstar" (as the Innovation Report called him) Mike Bostock.
GP: Q6. NYT has a lot of information about subscribers, and can probably infer many things they did not volunteer - eg person political views or sexual orientation. How does NYT balance privacy issues (avoid creepiness) vs need for revenue (more targeted ads)
CHW: Uh, no, I don't think we could infer political views or sexual orientation. We have no training data on that! Moreover the creepiness of the data we have is nothing - really, nothing - compared to that of Facebook, Google, or myriad other tech companies that are far more integrated into your life.
The only data we have access to are clicks, as opposed to all the text you enter into most sites or apps or, for mobile apps, your location (and phone calls, and photos....)
We're not a mail or messaging app. I get creeped out just thinking about how much people share with those sites; when you think about how much data you give via your gmail and searches alone, we've got nothing creepy.
GP: Q7. Given the declining newspaper revenue (from your slide), what convinced you to become a Chief Data Scientist of New York Times? What do you hope to accomplish?
KDnuggets Tweet, Nov 20, 2014: Every publisher now a start-up, says NYT Top Data Scientist @chrishwiggins: Newspaper ad revenue drops dramatically

CHW: To clarify: the slide I pointed to was specifically to print advertising revenue, not overall revenue. NYT responded to this already by creating paid digital products (collectively called "The Paywall") which now accounts for a large fraction of total revenue.
As to why I'm here: the New York Times is going through a really exciting transition right now, where nearly every function of the company is being transformed by data. This change is not only reflective of a change in tool set (awesome hardware and software) but in mind set -- more and more people are wondering how data can help them make hard decisions and, most importantly, better understand our audience. We're trying to define how to give data a seat at the table in making hard decisions both on the business and newsroom side.
Also the mission is extremely important to me. I agree with Jefferson on the importance of defending a strong and free press for the functioning of democracy, and there's simply no better place for journalism in the country than the New York Times.
Everyone here is very forward looking about how technology is changing the way people demand and interact with quality journalism, including the role of data science smoothing and speeding the digital transition.
In short you're right that news as a business is being challenged, but the effect of that, along with the importance of the Times' mission, has been to draw in more and more super-talented and energetic people all the time, who want to work somewhere were they can make a huge difference not only on a company but on society.
GP: Thomas Jefferson said:
Q8. Any advice to aspiring young Data Scientists?
CHW: Lots! I'd encourage you to read Chapter 1 of "Data Scientists at Work". or watch my Halloween 2014 talk at Harvard for more.
The most important advice is to apply to come work with us!
Related:
Last Halloween, Chris Wiggins, the New York Times Chief Data Scientist, invited me to come to his talk at Harvard.
Unfortunately, I could not attend at the time, but I saw his excellent slides and video of the talk, and we started a conversation. As a regular reader of the NYTimes since my NYU grad school days, I loved the chance to learn more about the NYTimes digital journalism today, and the result is this interview.
New York Times (along with other publishers) is now going through a period of declining ad revenues but also a big, scary, and exciting transformation, and I hope that Data Science will help it to adapt and prosper in the new era.
 Christopher H. Wiggins,
@chrishwiggins, is an associate professor of applied mathematics at Columbia University,
the first Chief Data Scientist at The New York Times,
and co-founder and co-organizer of hackNY hackNY.org .
Christopher H. Wiggins,
@chrishwiggins, is an associate professor of applied mathematics at Columbia University,
the first Chief Data Scientist at The New York Times,
and co-founder and co-organizer of hackNY hackNY.org .
At Columbia he is faculty in the Department of Applied Physics and Applied Mathematics, a founding member of the Department of Systems Biology, a founding member of the Data Science Institute datascience.columbia.edu/ , affiliated faculty in the Department of Statistics, and an instructor in the School of Journalism. His research focuses on applications of machine learning to real-world data, particularly biology.
Prior to joining the faculty at Columbia he was a Courant Instructor at NYU and earned his PhD at Princeton University in theoretical physics. In 2014 he was elected Fellow of the American Physical Society and is a recipient of Columbia's Avanessians Diversity Award.
Gregory Piatetsky, Q1. A major part of your role is understanding NYT subscribers (including me) better. Can you give some examples of insights that helped increase revenue? Can Data Science come up with some major insights that transform NYT business?
 Christopher H. Wiggins:
Absolutely! I think of data science teams as performing
principally either Data Product or Data Impact functions.
We've done both, in that we're building a number of data products (so
far just for internal use at the NYT) as well as trying to
impact roadmaps of other groups. Impact comes from learning
models which are not only predictive but also interpretable.
Christopher H. Wiggins:
Absolutely! I think of data science teams as performing
principally either Data Product or Data Impact functions.
We've done both, in that we're building a number of data products (so
far just for internal use at the NYT) as well as trying to
impact roadmaps of other groups. Impact comes from learning
models which are not only predictive but also interpretable.
For example, if we build a model which predicts individual subscribers' likelihood of canceling, we're interested not only in the machine learning part (does the model predict accurately the at risk individuals), which is an engineering win, but also in the data science win of revealing risky behaviors.
Identifying these suggests changes to product or marketing, which then can be executed and tested.
To find out more about specific examples, I encourage you to click here: developers.nytimes.com/careers/
GP: Q2. What are the key skills on your Data Science team and what are their/your favorite tools and packages for data analysis and visualization?
CHW: Key skills are being good listeners, good communicators, sufficient creativity and familiarity with machine learning methods to know how to reframe domain questions as machine learning tasks, the kind of self-skepticism science demands, and the desire to serve as a culture broker between the data and the demands of our collaborators throughout the company.
Regarding tools: Everything we do is open source when it comes to the machine learning, principally Python, sometimes R. The data engineering uses a variety of tools depending on what data we're querying, but typically map reduce, elastic map-reduce, or SQL as needed.
GP: Q3. Are there interesting NYT APIs that are open to the public?
CHW: Absolutely! NYT has been building APIs since 2008, ancient history. See developer.nytimes.com/docs .
GP: these include
- The Article Search API: Search Times articles from 1851 to today, retrieving headlines, abstracts and links to associated multimedia.
- The Books API: Retrieve New York Times book reviews and get data from all best-seller lists.
- The Campaign Finance API: Get presidential campaign contribution and expenditure data based on United States Federal Election Commission filings.
- The Geographic API: Use linked data to enhance location concepts used in The New York Times' controlled vocabulary.
- The Most Popular API: Get links and metadata for the blog posts and articles that are most frequently e-mailed, shared and viewed by NYTimes.com readers.
- The Movie Reviews API: Get links to reviews and NYT Critics' Picks, and search movie reviews by keyword.
- The Semantic API: Get access to the people, places, organizations and descriptors that make up the controlled vocabulary used as metadata by The New York Times.
GP: Q4. Can you elaborate on your point better wrong than "nice" in your Harvard Halloween talk?
Sure. I often observe a "cluster first, ask questions later" approach when people face new data. This was particularly pervasive in computational biology in the early days of microarray data. With unsupervised learning it's often difficult to asses which of two clustering approaches is "better", meaning that I don't sleep well at night because I'm wondering if I could have clustered differently and found something else.
 Instead I prefer first to think through what I really want to
learn from the data, which usually means that there's some
particular covariate I want to predict from the others.
So I try to hunt for supervised learning tasks rather than unsupervised learning
tasks. In supervised learning or "predictive analytics" I can
assess more clearly whether my model makes accurate predictions
on held out data, which gives me a way of saying whether my
model is "wrong."
I also mean this as reference to the famous dismissal by Wolfgang Pauli:
(cf. en.wikipedia.org/wiki/Not_even_wrong )
Instead I prefer first to think through what I really want to
learn from the data, which usually means that there's some
particular covariate I want to predict from the others.
So I try to hunt for supervised learning tasks rather than unsupervised learning
tasks. In supervised learning or "predictive analytics" I can
assess more clearly whether my model makes accurate predictions
on held out data, which gives me a way of saying whether my
model is "wrong."
I also mean this as reference to the famous dismissal by Wolfgang Pauli:
(cf. en.wikipedia.org/wiki/Not_even_wrong )
GP: Q5. NYT is known for excellent data visualization. Is that part of your role, and if so, do you have any advice / guidelines / tools to help present data better?
CHW: Our group is on the engineering side rather than in the newsroom, separate from the (awesome) graphics group. Certainly we benefit from their expertise, especially since we use a lot of d3, which was developed by the NYT "digital superstar" (as the Innovation Report called him) Mike Bostock.
GP: Q6. NYT has a lot of information about subscribers, and can probably infer many things they did not volunteer - eg person political views or sexual orientation. How does NYT balance privacy issues (avoid creepiness) vs need for revenue (more targeted ads)
CHW: Uh, no, I don't think we could infer political views or sexual orientation. We have no training data on that! Moreover the creepiness of the data we have is nothing - really, nothing - compared to that of Facebook, Google, or myriad other tech companies that are far more integrated into your life.
The only data we have access to are clicks, as opposed to all the text you enter into most sites or apps or, for mobile apps, your location (and phone calls, and photos....)
We're not a mail or messaging app. I get creeped out just thinking about how much people share with those sites; when you think about how much data you give via your gmail and searches alone, we've got nothing creepy.
GP: Q7. Given the declining newspaper revenue (from your slide), what convinced you to become a Chief Data Scientist of New York Times? What do you hope to accomplish?
KDnuggets Tweet, Nov 20, 2014: Every publisher now a start-up, says NYT Top Data Scientist @chrishwiggins: Newspaper ad revenue drops dramatically
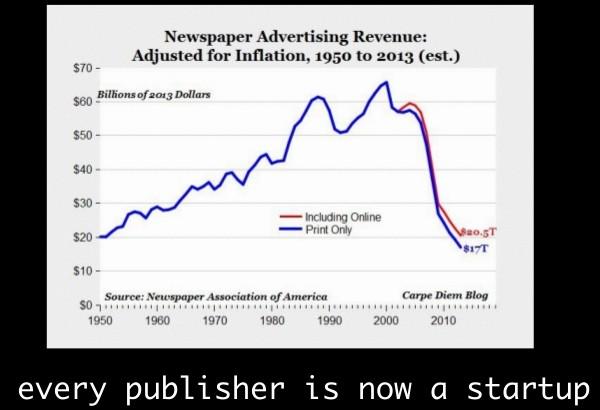
CHW: To clarify: the slide I pointed to was specifically to print advertising revenue, not overall revenue. NYT responded to this already by creating paid digital products (collectively called "The Paywall") which now accounts for a large fraction of total revenue.
As to why I'm here: the New York Times is going through a really exciting transition right now, where nearly every function of the company is being transformed by data. This change is not only reflective of a change in tool set (awesome hardware and software) but in mind set -- more and more people are wondering how data can help them make hard decisions and, most importantly, better understand our audience. We're trying to define how to give data a seat at the table in making hard decisions both on the business and newsroom side.
Also the mission is extremely important to me. I agree with Jefferson on the importance of defending a strong and free press for the functioning of democracy, and there's simply no better place for journalism in the country than the New York Times.
Everyone here is very forward looking about how technology is changing the way people demand and interact with quality journalism, including the role of data science smoothing and speeding the digital transition.
In short you're right that news as a business is being challenged, but the effect of that, along with the importance of the Times' mission, has been to draw in more and more super-talented and energetic people all the time, who want to work somewhere were they can make a huge difference not only on a company but on society.
GP: Thomas Jefferson said:
"If it were left to me to decide whether we should have a government without newspapers or newspapers without a government, I should not hesitate a moment to prefer the latter.
Q8. Any advice to aspiring young Data Scientists?
CHW: Lots! I'd encourage you to read Chapter 1 of "Data Scientists at Work". or watch my Halloween 2014 talk at Harvard for more.
The most important advice is to apply to come work with us!
Related:
- Top KDnuggets tweets, Nov 19-20, including
Every publisher now a start-up, says NYT Top Data Scientist @chrishwiggins: Newspaper ad revenue drops dramatically t.co/gx0xjlJXTw - Top KDnuggets tweets, Jul 25-27, including
NYTimes Chief Data Scientist Chris Wiggins on how we create and consume content now (& how to do it smarter) t.co/AfStHAnFej - Top KDnuggets tweets, Feb 3-4, including
NYTimes selects Columbia Prof. Chris Wiggins as its Chief Data Scientist, creates machine learning group buff.ly/1etlwVO