Top 20 Python Machine Learning Open Source Projects
We examine top Python Machine learning open source projects on Github, both in terms of contributors and commits, and identify most popular and most active ones.
We analyze Top 20 Python Machine learning projects on GitHub and find that scikit-Learn, PyLearn2 and NuPic are the most actively contributed projects. Explore these popular projects on Github!
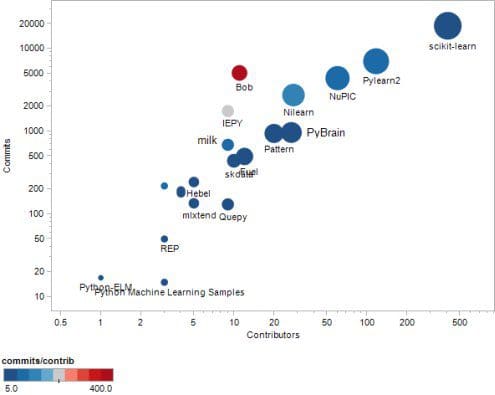 Fig. 1: Python Machine learning projects on GitHub, with color corresponding to commits/contributors. Bob, Iepy, Nilearn, and NuPIC have the highest such value.
Fig. 1: Python Machine learning projects on GitHub, with color corresponding to commits/contributors. Bob, Iepy, Nilearn, and NuPIC have the highest such value.
Fig. 1: Python Machine learning projects on GitHub, with color corresponding to commits/contributors. Bob, Iepy, Nilearn, and NuPIC have the highest such value.
- scikit-learn, 18845 commits, 404 contributors, www.github.com/scikit-learn/scikit-learn scikit-learn is a Python module for machine learning built on top of SciPy.It features various classification, regression and clustering algorithms including support vector machines, logistic regression, naive Bayes, random forests, gradient boosting, k-means and DBSCAN, and is designed to interoperate with the Python numerical and scientific libraries NumPy and SciPy.
- Pylearn2, 7027 commits, 117 contributors, www.github.com/lisa-lab/pylearn2 Pylearn2 is a library designed to make machine learning research easy. Its a library based on Theano
- NuPIC, 4392 commits, 60 contributors, www.github.com/numenta/nupic The Numenta Platform for Intelligent Computing (NuPIC) is a machine intelligence platform that implements the HTM learning algorithms. HTM is a detailed computational theory of the neocortex. At the core of HTM are time-based continuous learning algorithms that store and recall spatial and temporal patterns. NuPIC is suited to a variety of problems, particularly anomaly detection and prediction of streaming data sources.
- Nilearn, 2742 commits, 28 contributors, www.github.com/nilearn/nilearn Nilearn is a Python module for fast and easy statistical learning on NeuroImaging data. It leverages the scikit-learn Python toolbox for multivariate statistics with applications such as predictive modeling, classification, decoding, or connectivity analysis.
- PyBrain, 969 commits, 27 contributors, www.github.com/pybrain/pybrain PyBrain is short for Python-Based Reinforcement Learning, Artificial Intelligence and Neural Network Library. Its goal is to offer flexible, easy-to-use yet still powerful algorithms for Machine Learning Tasks and a variety of predefined environments to test and compare your algorithms.
- Pattern, 943 commits, 20 contributors, www.github.com/clips/pattern Pattern is a web mining module for Python. It has tools for Data Mining, Natural Language Processing, Network Analysis and Machine Learning. It supports vector space model, clustering, classification using KNN, SVM, Perceptron
- Fuel, 497 commits, 12 contributors, www.github.com/mila-udem/fuel Fuel provides your machine learning models with the data they need to learn. it has interfaces to common datasets such as MNIST, CIFAR-10 (image datasets), Google's One Billion Words (text). It gives you the ability to iterate over your data in a variety of ways, such as in minibatches with shuffled/sequential examples
- Bob, 5080 commits, 11 contributors, www.github.com/idiap/bob Bob is a free signal-processing and machine learning toolbox The toolbox is written in a mix of Python and C++ and is designed to be both efficient and reduce development time. It is composed of a reasonably large number of packages that implement tools for image, audio & video processing, machine learning and pattern recognition
- skdata, 441 commits, 10 contributors, www.github.com/jaberg/skdata Skdata is a library of data sets for machine learning and statistics. This module provides standardized Python access to toy problems as well as popular computer vision and natural language processing data sets.
- MILK, 687 commits, 9 contributors,
www.github.com/luispedro/milk
Milk is a machine learning toolkit in Python. Its focus is on supervised classification with several classifiers available: SVMs, k-NN, random forests, decision trees. It also performs feature selection. These classifiers can be combined in many ways to form different classification systems.For unsupervised learning,
milksupports k-means clustering and affinity propagation. - IEPY, 1758 commits, 9 contributors, www.github.com/machinalis/iepy IEPY is an open source tool for Information Extraction focused on Relation Extraction It's aimed at users needing to perform Information Extraction on a large dataset. scientists wanting to experiment with new IE algorithms.
- Quepy, 131 commits, 9 contributors, www.github.com/machinalis/quepy Quepy is a python framework to transform natural language questions to queries in a database query language. It can be easily customized to different kinds of questions in natural language and database queries. So, with little coding you can build your own system for natural language access to your database. Currently Quepy provides support for Sparql and MQL query languages, with plans to extended it to other database query languages.
- Hebel, 244 commits, 5 contributors, www.github.com/hannes-brt/hebel Hebel is a library for deep learning with neural networks in Python using GPU acceleration with CUDA through PyCUDA. It implements the most important types of neural network models and offers a variety of different activation functions and training methods such as momentum, Nesterov momentum, dropout, and early stopping.
- mlxtend, 135 commits, 5 contributors, www.github.com/rasbt/mlxtend Its a library consisting of useful tools and extensions for the day-to-day data science tasks.
- nolearn, 192 commits, 4 contributors, www.github.com/dnouri/nolearn This package contains a number of utility modules that are helpful with machine learning tasks. Most of the modules work together with scikit-learn, others are more generally useful.
- Ramp, 179 commits, 4 contributors, www.github.com/kvh/ramp Ramp is a python library for rapid prototyping of machine learning solutions. It's a light-weight pandas-based machine learning framework pluggable with existing python machine learning and statistics tools (scikit-learn, rpy2, etc.). Ramp provides a simple, declarative syntax for exploring features, algorithms and transformations quickly and efficiently.
- Feature Forge, 219 commits, 3 contributors, www.github.com/machinalis/featureforge A set of tools for creating and testing machine learning features, with a scikit-learn compatible API. This library provides a set of tools that can be useful in many machine learning applications (classification, clustering, regression, etc.), and particularly helpful if you use scikit-learn (although this can work if you have a different algorithm).
- REP, 50 commits, 3 contributors, www.github.com/yandex/rep REP is environment for conducting data-driven research in a consistent and reproducible way. It has a unified classifiers wrapper for variety of implementations like TMVA, Sklearn, XGBoost, uBoost. It can train classifiers in parallel on a cluster. It supports interactive plots
- Python Machine Learning Samples, 15 commits, 3 contributors, www.github.com/awslabs/machine-learning-samples A collection of sample applications built using Amazon Machine Learning.
- Python-ELM, 17 commits, 1 contributor, www.github.com/dclambert/Python-ELM This is an implementation of the Extreme Learning Machine in Python, based on scikit-learn.
- Interesting Open-Source Projects in Machine Learning, Data Mining, Data Science
- Open Source Tools for Machine Learning
- Will the Real Data Scientists Please Stand Up?