Dataiku Data Science Studio – intuitive solution for data professionals
Data Science Studio (DSS) from Dataiku is an intuitive software solution that let data professionals harness the power of big data. The latest version DSS 2.0 brings predictive analytics to a whole new level in terms of collaboration and usability.
We’ve made a number of exciting changes to DSS that are designed to improve usability, expand machine learning & data preparation capabilities, and provide easy access to data manipulation functionality using recipes. These changes and new features reflect a different approach to managing big data: making predictive analytics software accessible to a wide variety of data professionals, but without compromising the integrity of core functionality. In fact, our challenge was to expand & improve both functionality and usability -- we hope that DSS 2.0 provides all of this and more.
Redesigned user interface
Here at Dataiku we approached DSS 2.0 with the desire to make the solution easier to use and more accessible. This effort started with a redesign of the interface -- the key interface changes found in DSS 2.0 include:
Navigation Bar for Easy Access to DSS Sections and Functionalities: Easy icon-based access to functionality enables you to manage all aspects of your projects (comment management, ongoing tasks, interface configuration, etc.).
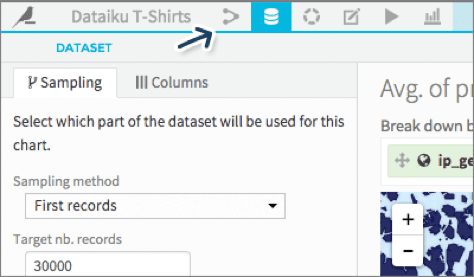
 Data Presentation & Management: Organization is key when it comes to managing complex data. DSS 2.0 features a streamlined flow that enables you to visually keep track of datasets and recipes without the clutter. In addition, project management has now been made easier via checklists for collaborative work.
Data Presentation & Management: Organization is key when it comes to managing complex data. DSS 2.0 features a streamlined flow that enables you to visually keep track of datasets and recipes without the clutter. In addition, project management has now been made easier via checklists for collaborative work.
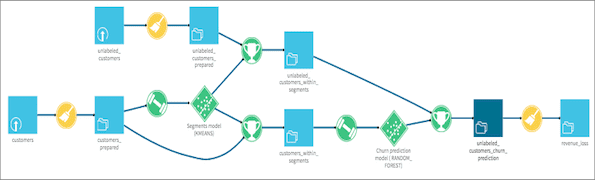
- Column-oriented view that supports the implementation of bulk actions to datasets, such as delete, change type, and multiple transformations;
- Highly-specific statistics can be viewed for specific columns, such as standard deviation, empty cells, mean, median, and so on;
- Comprehensive column sorting & filtering;
- New currency conversion processor with support for 40 currencies with historical data.
 Machine learning revisited
DSS 2.0 has taken a whole new approach to machine learning via a complete redesign coupled with significant functional enhancements. The new machine learning interface empowers you to create both supervised and unsupervised models with ease. Features include:
Machine learning revisited
DSS 2.0 has taken a whole new approach to machine learning via a complete redesign coupled with significant functional enhancements. The new machine learning interface empowers you to create both supervised and unsupervised models with ease. Features include:
- Data Preparation Integration: The new machine learning interface is now tightly integrated with DSS’ data preparation module, enabling you to automatically include new preparation script variables in your models;
- Additional Algorithms: Decision Trees and Gradient Boosted Trees are now available for classification purposes. You can also continue to use your own custom models as long as they have a scikit-learn compatible API;
- Advanced Model Training & Deployment: Models can now be trained on one dataset and tested on a different one for cross-validation purposes ━ better yet, they can be re-trained on-the-fly as your datasets are evolving. A history of trained models can be viewed and a version selected for use in your workflows (e.g., when scoring new records);
- Features Pre-processing Capabilities: DSS 2.0 now supports feature hashing for high cardinality categorical features, binarization & quantile-cut for numerical features, and hashing / vectorization / TF/ IDF for text features;
- Results Screens Enhancement: Interpretation of models has now been significantly enhanced with the introduction of additional helpers, including coefficients of linear models. New model views have also been implemented: the Decision Chart view (an expanded view of the confusion matrix for different probability cut-offs) and the Density Chart view (designed to explore the probability distribution of your model).
 Density Chart
Density Chart
 New visual recipes
Facilitate fast data preparation without the need to write SQL code. Our five new visual recipes provide an easy way to initiate data manipulations, such as cleansing and aggregation. DSS 2.0 now features:
New visual recipes
Facilitate fast data preparation without the need to write SQL code. Our five new visual recipes provide an easy way to initiate data manipulations, such as cleansing and aggregation. DSS 2.0 now features:

- The Split recipe: For the creation of multiple datasets from a singular dataset;
- The Stack recipe: For the vertical stacking of datasets;
- The Sample/Filter recipe: For the selection and sampling of records from datasets;
- The Group recipe: For the generation of summarized statistics from dataset columns;
- The Join recipe: For the merging of two or more datasets.