Getting started with Python and Apache Flink
Apache Flink built on top of the distributed streaming dataflow architecture, which helps to crunch massive velocity and volume data sets. With version 1.0 it provided python API, learn how to write a simple Flink application in python.
By Will McGinnis.
After my last post about the breadth of big-data / machine learning projects currently in Apache, I decided to experiment with some of the bigger ones. This post serves as a minimal guide to getting started using the brand-brand new python API into Apache Flink. Flink is a very similar project to Spark at the high level, but underneath it is a true streaming platform (as opposed to Spark’s small and fast batch approach to streaming). This gives rise to a number of interesting use cases where massive velocity and volume of data needs to be processed quickly and in complex ways.
The basic idea is a code streaming platform upon which sits two processing APIs and a collection of libraries.
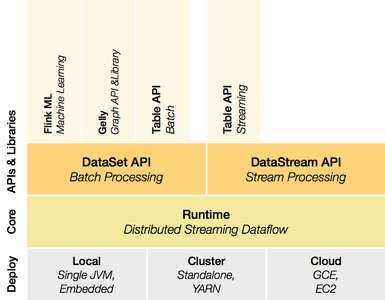
With version 1.0 of Flink, a python API will be available, again, similarly to Spark. While it is present in pre-1.0 releases, there are known bugs present that make its use difficult or impossible. So to start with, we need to build the master branch (unless you are reading this since the v1.0 release, if that’s the case just follow Flink’s instructions to build).
git clone https://github.com/apache/flink
cd flink
mvn clean install -DskipTests
At this point the bleeding edge Flink build will be symlinked at build-target in the flink directory. You can start up Flink with the commands.
./build-target/bin/start-cluster.sh
./build-target/bin/start-webclient.sh
Which will start a simple UI on localhost:8080, a job manager and a task manager. Now we can run a simple script, make a new directory for your project and a python file in it:
cd ..
mkdir flink-examples
cd flink-examples
touch wordcount.py
Then add a slightly modified version of the example from Flink’s documentation into wordcount.py:
from flink.plan.Environment import get_environment
from flink.plan.Constants import INT, STRING, WriteMode
from flink.functions.GroupReduceFunction \
import GroupReduceFunction
class Adder(GroupReduceFunction):
def reduce(self, iterator, collector):
count, word = iterator.next()
count += sum([x[0] for x in iterator])
collector.collect((count, word))
if __name__ == "__main__":
output_file = 'file:///.../flink-examples/out.txt'
print('logging results to: %s' % (output_file, ))
env = get_environment()
data = env.from_elements("Who's there? I think \
I hear them. Stand, ho! Who's there?")
data \
.flat_map(lambda x, c: [(1, word) for word in \
x.lower().split()], (INT, STRING)) \
.group_by(1) \
.reduce_group(Adder(), (INT, STRING), combinable=True) \
.map(lambda y: 'Count: %s Word: %s' % (y[0], y[1]), STRING) \
.write_text(output_file, write_mode=WriteMode.OVERWRITE)
env.execute(local=True)
And run it with:
cd ..
./flink/build-target/bin/pyflink3.sh ~./flink-examples/word_count.py
In out.txt you should now see:
Count: 1 Word: hear
Count: 1 Word: ho!
Count: 2 Word: i
Count: 1 Word: stand,
Count: 1 Word: them.
Count: 2 Word: there?
Count: 1 Word: think
Count: 2 Word: who's
And there you go, totally minimal example to get up and running with python in Apache Flink. The code is up here: https://github.com/wdm0006/flink-python-examples, and I will add in more advanced examples both in the repo and explained here as we move along.
Bio: Will McGinnis, @WillMcGinnis, has degrees in Mechanical Engineering from Auburn, but mostly writes software now. He was the first employee at Predikto, and currently helps build out the premiere platform for predictive maintenance in heavy industry there. When not working on that, he is generally working on something related to python, flask, scikit-learn or cycling.
Related