7 Steps to Mastering Machine Learning With Python
There are many Python machine learning resources freely available online. Where to begin? How to proceed? Go from zero to Python machine learning hero in 7 steps!
Step 4: Getting Started with Machine Learning in Python
- Python. Check.
- Machine learning fundamentals. Check.
- Numpy. Check.
- Pandas. Check.
- Matplotlib. Check.
The time has come. Let's start implementing machine learning algorithms with Python's de facto standard machine learning library, scikit-learn.
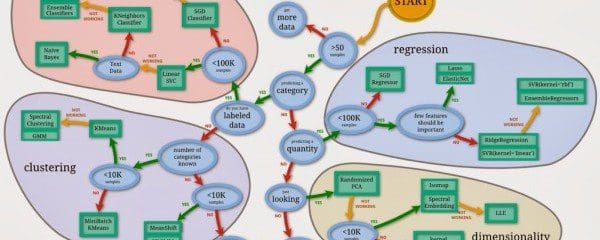
The scikit-learn flow chart.
Many of the following tutorials and exercises will be driven by the iPython (Jupyter) Notebook, which is an interactive environment for executing Python. These iPython notebooks can optionally be viewed online or downloaded and interacted with locally on your own computer.
- iPython Notebook Overview from Stanford
Also note that the tutorials below are from a number of online sources. All Notebooks have been attributed to the authors; if, for some reason, you find that someone has not been properly credited for their work, please let me know and the situation will be rectified ASAP. In particular, I would like to tip my hat to Jake VanderPlas, Randal Olson, Donne Martin, Kevin Markham, and Colin Raffel for their fantastic freely-available resources.
Our first tutorials for getting our feet wet with scikit-learn follow. I suggest doing all of these in order before moving to the following steps.
A general introduction to scikit-learn, Python's most-used general purpose machine learning library, covering the k-nearest neighbors algorithm:
- An Introduction to scikit-learn, by Jake VanderPlas
A more in-depth and expanded introduction, including a starter project with a well-known dataset from start to finish:
- Example Machine Learning Notebook, by Randal Olson
A focus on strategies for evaluating different models in scikit-learn, covering train/test dataset splits:
- Model Evaluation, by Kevin Markham
Step 5: Machine Learning Topics with Python
With a foundation having been laid in scikit-learn, we can move on to some more in-depth explorations of the various common, and useful, algorithms. We start with k-means clustering, one of the most well-known machine learning algorithms. It is a simple and often effective method for solving unsupervised learning problems:
- k-means Clustering, by Jake VanderPlas
Next, we move back toward classification, and take a look at one of the most historically popular classification methods:
From classification, we look at continuous numeric prediction:
- Linear Regression, by Jake VanderPlas
We can then leverage regression for classification problems, via logistic regression:
- Logistic Regression, by Kevin Markham
Step 6: Advanced Machine Learning Topics with Python
We've gotten our feet wet with scikit-learn, and now we turn our attention to some more advanced topics. First up are support vector machines, a not-necessarily-linear classifier relying on complex transformations of data into higher dimensional space.
- Support Vector Machines, by Jake VanderPlas
Next, random forests, an ensemble classifier, are examined via a Kaggle Titanic Competition walk-through:
- Kaggle Titanic Competition (with Random Forests), by Donne Martin
Dimensionality reduction is a method for reducing the number of variables being considered in a problem. Principal Component Analysis is a particular form of unsupervised dimensionality reduction:
- Dimensionality Reduction, by Jake VanderPlas
Before moving on to the final step, we can take a moment to consider that we have come a long way in a relatively short period of time.
Using Python and its machine learning libraries, we have covered some of the most common and well-known machine learning algorithms (k-nearest neighbors, k-means clustering, support vector machines), investigated a powerful ensemble technique (random forests), and examined some additional machine learning support tasks (dimensionality reduction, model validation techniques). Along with some foundational machine learning skills, we have started filling a useful toolkit for ourselves.
We will add one more in-demand tool to that kit before wrapping up.
Step 7: Deep Learning in Python
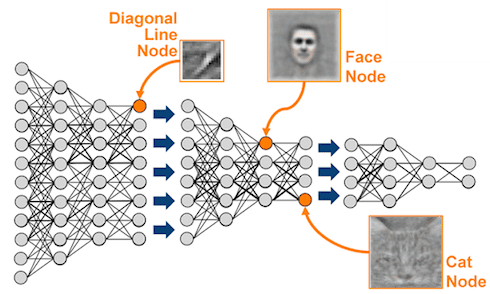
The learning is deep.
Deep learning is everywhere! Deep learning builds on neural network research going back several decades, but recent advances dating to the past several years have dramatically increased the perceived power of, and general interest in, deep neural networks. If you are unfamiliar with deep learning, KDnuggets has many articles detailing the numerous recent innovations, accomplishments, and accolades of the technology.
This final step does not purport to be a deep learning clinic of any sort; we will take a look at a few simple network implementations in 2 of the leading contemporary Python deep learning libraries. For those interested in digging deeper into deep learning, I recommend starting with the following free online book:
Theano is the first Python deep learning library we will look at. From the authors:
Theano is a Python library that allows you to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently.
The following introductory tutorial on deep learning in Theano is lengthy, but it is quite good, very descriptive, and heavily-commented:
The other library we will test drive is Caffe. Again, from the authors:
Caffe is a deep learning framework made with expression, speed, and modularity in mind. It is developed by the Berkeley Vision and Learning Center (BVLC) and by community contributors.
This tutorial is the cherry on the top of this article. While we have undertaken a few interesting examples above, none likely compete with the following, which is implementing Google's #DeepDream using Caffe. Enjoy this one! After understanding the tutorial, play around with it to get your processors dreaming on their own.
I didn't promise it would be quick or easy, but if you put the time in and follow the above 7 steps, there is no reason that you won't be able to claim reasonable proficiency and understanding in a number of machine learning algorithms and their implementation in Python using its popular libraries, including some of those on the cutting edge of current deep learning research.
Bio: Matthew Mayo is a computer science graduate student currently working on his thesis parallelizing machine learning algorithms. He is also a student of data mining, a data enthusiast, and an aspiring machine learning scientist.
Related: