The Data Science Process, Rediscovered
The Data Science Process is a relatively new framework for doing data science. It is compared to previous similar frameworks, and a discussion on process innovation versus repetition is then undertaken.
Last week, KDnuggets top tweet was a Quora answer to What is the work flow or process of a data scientist?. This answer, written by Ryan Fox Squire, a self-described "Neuroscientist Turned Data Scientist," employed The Data Science Process as it described such a workflow.
The Data Science Process
The Data Science Process is a framework for approaching data science tasks, and is crafted by Joe Blitzstein and Hanspeter Pfister of Harvard's CS 109. The goal of CS 109, as per Blitzstein himself, is to introduce students to the overall process of data science investigation, a goal which should provide some insight into the framework itself.
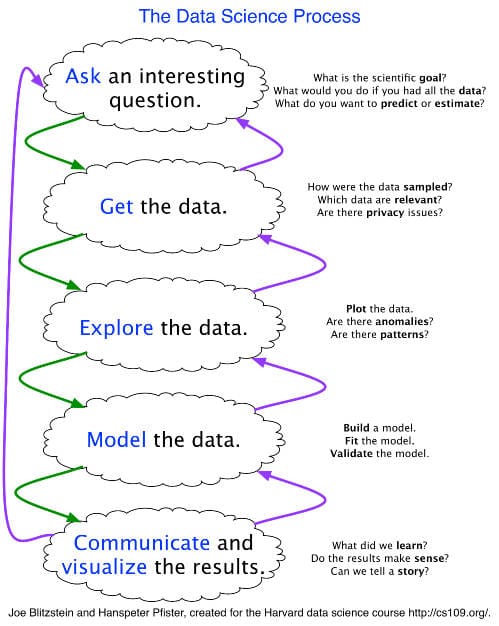
The following is a sample application of Blitzstein & Pfister's framework, regarding skills and tools at each stage, as given by Ryan Fox Squire in his answer:
Stage 1: Ask A Question
- Skills: science, domain expertise, curiosity
- Tools: your brain, talking to experts, experience
Stage 2: Get the Data
- Skills: web scraping, data cleaning, querying databases, CS stuff
- Tools: python, pandas
Stage 3: Explore the Data
- Skills: Get to know data, develop hypotheses, patterns? anomalies?
- Tools: matplotlib, numpy, scipy, pandas, mrjob
Stage 4: Model the Data
- Skills: regression, machine learning, validation, big data
- Tools: scikits learn, pandas, mrjob, mapreduce
Stage 5: Communicate the Data
- Skills: presentation, speaking, visuals, writing
- Tools: matplotlib, adobe illustrator, powerpoint/keynote
Squire then (rightfully) concludes that the data science work flow is a non-linear, iterative process, and that there are many skills and tools required to cover the full data science process. Squire also professes that he is fond of the Data Science Process as it stresses both the importance of asking questions to guide your workflow, and the importance of iterating on your questions and research, as one gains familiarity with one's data.
The Data Science Framework is an innovative framework for approaching data science problems. Isn't it?
Next, we look at CRISP-DM.
CRISP-DM
As a comparison to the Data Science Process put forth by Blitzstein & Pfister, and elaborated upon by Squire, we take a quick look at the de facto official (yet unquestionably falling out of fashion) data mining framework (which has been extended to data science problems), the Cross Industry Standard Process for Data Mining (CRISP-DM). Though the standard is no longer actively maintained, it remains a popular framework for navigating data science projects.
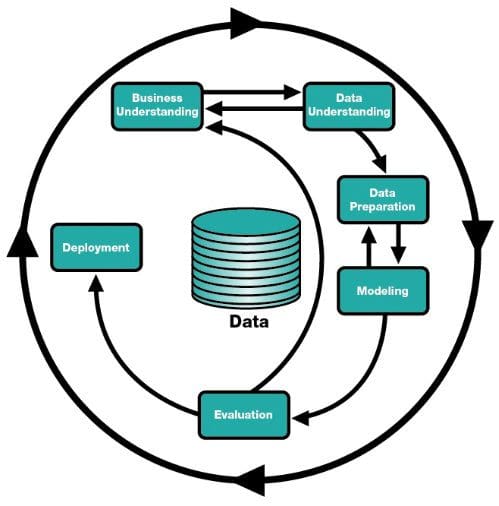
CRISP-DM is made up of the following steps:
- Business Understanding
- Data Understanding
- Data Preparation
- Modeling
- Evaluation
- Deployment
You can see similarities in these models: we start by asking a question or looking for insight into some particular phenomenon, we need some data to examine, the data must be inspected or prepared in some manner, the data is used to create some appropriate model, and something is done with the resulting model, be it "deployed" or "communicated." Though not quite to the extent of Blitzstein & Pfister's Data Science Process, CRISP-DM's workflow allows for iterative problem solving, and is clearly nonlinear.
Just as the standard itself is no longer maintained, neither is its website. You can, however, access further information about CRISP-DM on its Wikipedia page. For those unfamiliar with CRISP-DM, this visual guide is a good place to begin.
So CRISP-DM is clearly the base framework for investigating data science problems. Right?
The KDD Process
Around the same time that CRISP-DM was emerging, the KDD Process had finished developing. The KDD (Knowledge Discovery in Databases) Process, by Fayyad, Piatetsky-Shapiro, and Smyth, is a framework which has, at its core, "the application of specific data-mining methods for pattern discovery and extraction." The framework consists of the following steps:
- Selection
- Preprocessing
- Transformation
- Data Mining
- Interpretation
If you consider the term "data mining" analogous to the term "modeling" in the previous frameworks, the KDD Process lines up similarly. Note the iterative nature of this model as well.

Discussion
It is important to note that these are not the only frameworks in this space; SEMMA (for Sample, Explore, Modify, Model and Assess), from SAS, and the agile-oriented Guerilla Analytics both come to mind. There are also numerous in-house processes that various data science teams and individuals no doubt employ across any number of companies and industries in which data scientists work.
So, is the Data Science Process a new take on CRISP-DM, which is just a reworking of KDD, or is it a new, independent framework in its own right? Well, yes. And no.
Just as data science can be viewed as a contemporary take on data mining, the Data Science Process and CRISP-DM may be viewed as updates to the KDD process. To be clear, however, even if this is the case, is does not render them unnecessary; the updates to their process presentations may be of benefit to newer generations approaching these processes from both the point of view of refreshed and up-to-date language, as well as the presentation of a framework which can be viewed as "new" and, thus, worthy of attention.
Is every JavaScript library warranted? I'm no expert in the space, but I would say probably not. Sure, it's not a perfect analogy, but the underlying point is that in technology, there are often overlaps in tools being employed. People are attracted to shiny new things, and to different things, and as such, newly packaged terminology can serve both a psychological and practical purpose, even if it happened to be exactly, or relatively, the same as one which came before it.
The Data Science Process and its predecessor CRISP-DM are basically re-workings of the KDD Process. And this is not meant with malice or dark undertone; it has not been typed in the accusatory or with wagging finger. This is simply a statement of a simple fact: that which comes before influences that which comes after. In the end, any framework or process or series of steps which we take to do data science, as long as it works for us and provides accurate results, is worthy of being used. Even if this happens to be the Data Science Process, or CRISP-DM, or the KDD Process, or whatever steps you take when you enter a Kaggle competition, or your boss asks you to cluster some data on widgets, or you try your hand at the latest deep learning research paper.
Matthew Mayo (@mattmayo13) is a Data Scientist and the Editor-in-Chief of KDnuggets, the seminal online Data Science and Machine Learning resource. His interests lie in natural language processing, algorithm design and optimization, unsupervised learning, neural networks, and automated approaches to machine learning. Matthew holds a Master's degree in computer science and a graduate diploma in data mining. He can be reached at editor1 at kdnuggets[dot]com.