The Core of Data Science
This post provides a simplifying framework, an ontology for Machine Learning and some important developments in dynamical machine learning. From first hand Data Science product experience, the author suggests how best to execute Data Science projects.
By PG Madhavan, Ph.D., Algorist - Data Science for Business.
Reading some recent blogs, I sense a level of angst among Data Science practitioners about the nature of their field. What exactly IS Data Science - a question that seems to lurk just below the surface...
As a young field of study and work, it will naturally take time for a definition of Data Science to crystallize. In the meantime, see if this works for you...
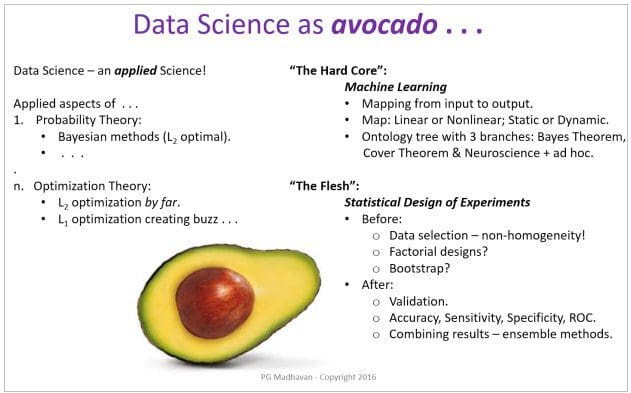
Data Science is the applied aspect of many theories. My orientation is Bayesian; so I have Probability theory at the top. Many other sciences also play a part – Physics & Statistical Mechanics for one play a significant role. We have been comfortable with L2 optimization (Euclidian distance metric) for a long time but there is a ground-swell of activity in L1 optimization (taxi-cab distance metric). L1 optimization pushes us out of our comfort zone of mean-squared error optimality and associated 2nd-order thinking!
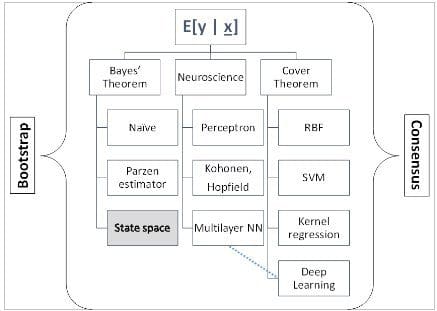
No doubt that the HARD CORE of Data Science is Machine Learning (ML) – and the topic is “hard-core”! ML is fundamentally concerned with finding the all-important “mapping” between input and output vector spaces (for a complete development of this topic, see “SYSTEMS Analytics: Adaptive Machine Learning workbook”). These are so many tools and tricks that developing a comprehensive understanding of ML can be frustrating; so I have put together an ontology below that organizes all we know about ML. The highlight is the collection of the vast material under 3 topics: Bayes Theorem, Cover Theorem and Neuroscience & ad hoc methods. In ML practice, these ML methods are “wrapped” around by “bootstrap” and “consensus” methods.
The “hard core of the avocado” is within the large brackets.
- Cover Theorem states (from Haykin, 2006): “A complex pattern classification problem, cast in a high-dimensional space nonlinearly, is more likely to be linearly separable than in a low-dimensional space, provided that the space is not densely populated”.
- Estimating the Conditional Expectation, E[ y | x], where ‘y’ is the output and ‘x’ is the input, from the conditional probability density function of the output is the stuff of hard core probabilistic approach. My own personal favorite is the use of State Space data models and Kalman Filter is estimate the parameters.
- The middle branch is a “catch all” dominated by Neuroscience starting with Perceptrons. Deep Learning is the newest incarnation of this approach (combined with high-dimensionality) in this ontology.
Statistical Design of Experiments provides the surrounding “meat”!
Input side: Bootstrap methods
The objective is to maximize Training Set information use.
- There are many approaches:
- Bootstrap training set; sample Training Set with replacement.
- Monte Carlo methods; for probability density estimation.
- Feature subspace.
- Design of Experiments principles from Statistics; “blocking”, factorial design, etc.
- And many more.
Output side: Consensus methods
Solve the problem using independent ML methods and combine the results.
- Combine “weak learners”.
- Random Forest.
- AdaBoost.
- And many more.
Majority of Machine Learning work tends to rely on learning a Static mapping between inputs and outputs and then moving this into “production” under the implicit assumption that the relationship will remain unchanged! I challenge this assumption and provide ways to optimally address the real-life dynamical, time-varying situations in this blog: “Need for DYNAMICAL Machine Learning: Bayesian exact recursive estimation”.
Practical usage of ML maps requires a rigorous framework of Design of Experiments (Box, et al., an old classic). As we saw in the Ontology tree above, when you surround solid ML maps with strong statistical experimentation discipline, we get robust, repeatable and practically useful results out of Data Science!
As far as implementing Data Science solution is concerned, Data Science is a “Team Sport” and a “Contact Sport”.
There is no Data Science without constant contact with data. Data informs algorithms, code, business application and daily use.
Data Science solution development requires (1) an algorist with deep and wide Math skills, (2) a coder with database and cloud OS skills and (3) a business major with a quantitative leaning. I am yet to meet a single individual who embodies all three skills to the depth required! Equally important, the personal temperaments for each are starkly different. So, a real or virtual three-person team is needed for rapid Data Science solution development. Data Science solution deployment and operation can often be accomplished by a qualified STEM graduate who has an applied statistician’s mind (who appreciates the statistical experimental aspect of day-to-day business applications).
The best days of Data Science are yet to come! There are other Sciences to be tapped for new techniques, more computing power means more can be accomplished and soon, robust “Intelligence Augmentation” provided by Data Science will change the nature of business, work and play for the better – the next “industrial” revolution!
 Bio: PG Madhavan, Ph.D. is a Data Science Player + Coach with a deep & balanced track record in Machine Learning algorithms, products & business.
Bio: PG Madhavan, Ph.D. is a Data Science Player + Coach with a deep & balanced track record in Machine Learning algorithms, products & business.
Related:
- Theoretical Data Discovery: Using Physics to Understand Data Science
- Building a Data Science Portfolio: Machine Learning Project Part 1
- How Do You Identify the Right Data Scientist for Your Team?