Apache Arrow and Apache Parquet: Why We Needed Different Projects for Columnar Data, On Disk and In-Memory
Apache Parquet and Apache Arrow both focus on improving performance and efficiency of data analytics. These two projects optimize performance for on disk and in-memory processing
By Julien LeDem, architect, Dremio.
Columnar data structures provide a number of performance advantages over traditional row-oriented data structures for analytics. These include benefits for data on disk – fewer disk seeks, more effective compression, faster scan rates – as well as more efficient use of CPU for data in memory. Today columnar data is very common and is implemented by most analytical databases, including Teradata, Vertica, Oracle, and others.
In 2012 and 2013 several of us at Twitter and Cloudera created Apache Parquet (originally called Red Elm, an anagram for Google’s Dremel) to bring these ideas to the Hadoop ecosystem. Four years later, Parquet is the standard for columnar data on disk, and a new project called Apache Arrow has emerged to become the standard way of representing columnar data in memory. In this article we’ll take a closer look at why we need two projects, one for storing data on disk and one for processing data in memory, and how they work together.
What’s wrong with rows, and what’s right with columns?
Back in 2007 Vertica, one of the early commercial columnar databases, had a clever marketing slogan “The Tables Have Turned.” This isn’t a bad way of visualizing how columnar databases work – turn a table 90 degrees and now what used to be reading a row is reading a single column. This approach has a lot of advantages when it comes to analytical workloads.

Most systems are engineered to minimize the number of disk seeks and the amount of data scanned, as these operations can add tremendous latency. In transactional workloads, as data is written to a table in a row-oriented database, the columns for a given row are written out to disk contiguously, which is very efficient for writes. Analytical workloads differ in that most queries read a small subset of the columns for large numbers of rows at a time. In a traditional row-oriented database, the system might perform a seek for each row, and most of the columns would be read from disk into memory unnecessarily.
A columnar database organizes the values for a given column contiguously on disk. This has the advantage of significantly reducing the number of seeks for multi-row reads. Furthermore, compression algorithms tend to be much more effective on a single data type rather than the mix of types present in a typical row. The tradeoff is that writes are slower, but this is a good optimization for analytics where reads typically far outnumber writes.
Columnar, meet Hadoop
At Twitter we were big users of Hadoop, which is very scalable, good at storing a wide range of data, and good at parallelizing workloads across hundreds or thousands of servers. In general Hadoop is fairly high latency, and so we were also big users of Vertica, which gave us great performance but for only a small subset of our data.
We felt that by doing a better job of organizing the data in a columnar model in HDFS we could significantly improve the performance of Hadoop for analytical jobs, primarily for Hive queries, but for other projects as well. At the time we had around 400M users and were generating over 100TB of compressed data per day, so there was a lot of interest in this project.
We saw a lot of benefits in our early tests: we reduced storage overhead by 28%, and we saw a 90% reduction in time to read a single column. We kept at it, adding column-specific compression options, dictionary compression, bit packing and run length encoding, ultimately reducing storage another 52% and read times another 48%.

Parquet was also designed to handle richly structured data like JSON. It was very beneficial to us at Twitter and many other early adopters, and today most Hadoop users store their data in Parquet. There is pervasive support for Parquet across the Hadoop ecosystem, including Spark, Presto, Hive, Impala, Drill, Kite, and others. Even outside of Hadoop it has been adopted in some scientific communities, such as CERN’s ROOT project.
Building on the ideas of Parquet for in-memory processing
Hardware has changed a lot in the 15 years since original Google papers that inspired Hadoop. The most important change is the dramatic decline in RAM prices.
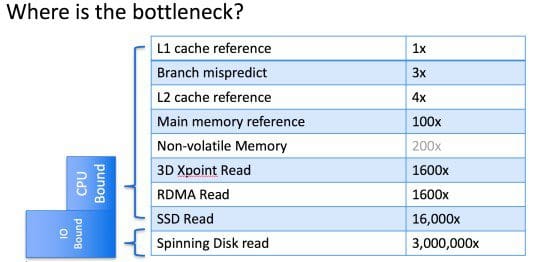
Servers today have a lot more RAM than they did when I was at Twitter, and because reading data from memory is thousands of times faster than reading data from disk, there is enormous interest in the data world in how to make optimal use of RAM for analytics.
The trade-offs being for columnar data are different for in-memory. For data on disk, usually IO dominates latency, which can be addressed with aggressive compression, at the cost of CPU. In memory, access is much faster and we want to optimize for CPU throughput by paying attention to cache locality, pipelining, and SIMD instructions.
Streamlining the interface between systems
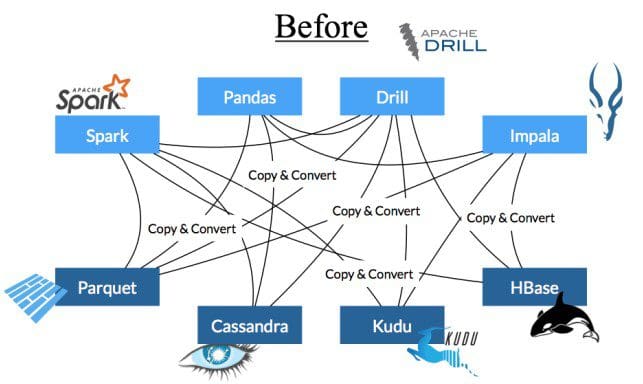
One of the funny things about computer science is that while there is a common set of resources – RAM, CPU, storage, network – each language has an entirely different way of interacting with those resources. When different programs need to interact – within and across languages – there are inefficiencies in the handoffs that can dominate the overall cost. This is a little bit like traveling in Europe before the Euro where you needed a different currency for each country, and by the end of the trip you could be sure you had lost a lot of money with all the exchanges!
![]()
We viewed these handoffs as the next obvious bottleneck for in-memory processing, and set out to work across a wide range of projects to develop a common set of interfaces that would remove unnecessary serialization and deserialization when marshalling data. Apache Arrow standardizes an efficient in-memory columnar representation that is the same as the wire representation. Today it includes first class bindings in over 13 projects, including Spark, Hadoop, R, Python/Pandas, and my company, Dremio.
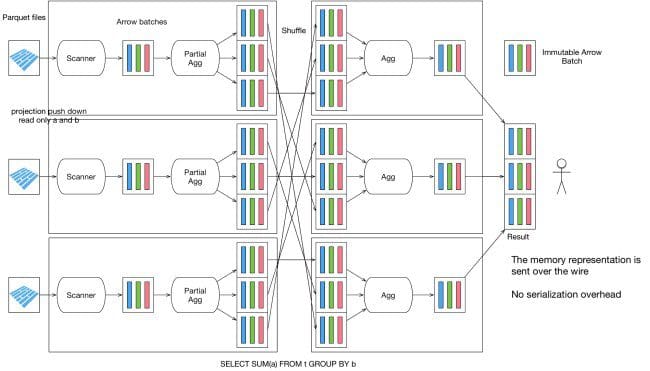
Python in particular has very strong support in the Pandas library, and supports working directly with Arrow record batches and persisting them to Parquet.
These are still early days for Apache Arrow, but the results are very promising. It is not uncommon for users to see 10x-100x improvements in performance across a range of workloads.
Parquet and Arrow, working together
Interoperability between Parquet and Arrow has been a goal since day 1. While each project can be used independently, both provide APIs to read and write between the formats. 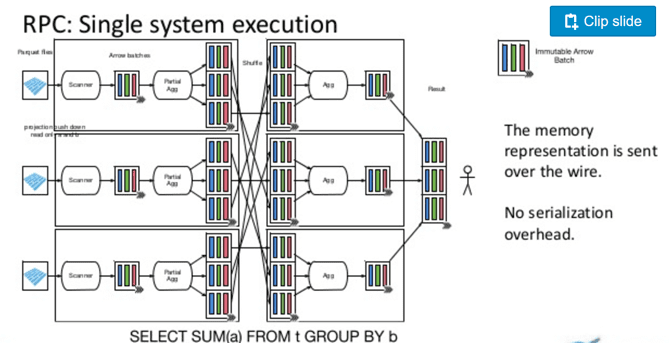
Since both are columnar we can implement efficient vectorized converters from one to the other and read from Parquet to Arrow much faster than in a row-oriented representation. We are still working on ways to make this integration even more seamless, including a vectorized Java reader, and full type equivalence.
Pandas is a good example of using both projects. Users can save a Pandas data frame to Parquet and read a Parquet file to in-memory Arrow. Pandas can directly work on top of Arrow columns, paving the way for a faster Spark integration.
At my current company, Dremio, we are hard at work on a new project that makes extensive use of Apache Arrow and Apache Parquet. You can learn more at www.dremio.com.
Bio: Julien LeDem, architect, Dremio is the co-author of Apache Parquet and the PMC Chair of the project. He is also a committer and PMC Member on Apache Pig. Julien is an architect at Dremio, and was previously the Tech Lead for Twitter’s Data Processing tools, where he also obtained a two-character Twitter handle (@J_). Prior to Twitter, Julien was a Principal engineer and tech lead working on Content Platforms at Yahoo! where he received his Hadoop initiation.
Related: