 The 42 V’s of Big Data and Data Science
The 42 V’s of Big Data and Data Science
 The 42 V’s of Big Data and Data Science
The 42 V’s of Big Data and Data ScienceIt's 2017 now, and we now operate in an ever more sophisticated world of analytics. To keep up with the times, we present our updated 2017 list: The 42 V's of Big Data and Data Science.
By Tom Shafer, Elder Research, Inc.

Understanding and effectively communicating a concept often requires first building a simple mental model. Consider, for example, how we teach the physical laws to students: it helps to walk with algebra before you can run with calculus. This kind of model trades correctness (shaving off "unnecessary" detail) for an increased ability to grasp the larger picture.
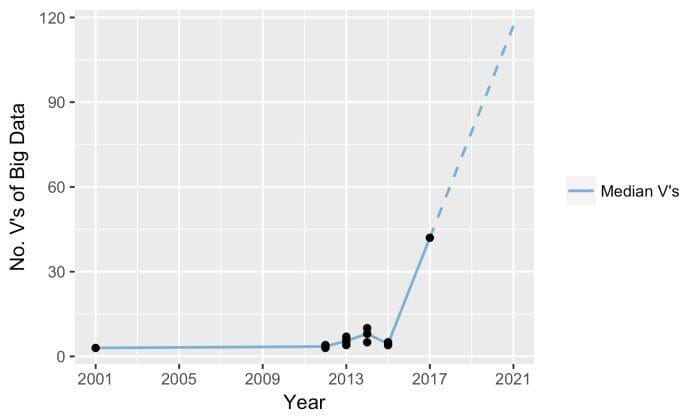
In 2001, Gartner (perhaps) accidentally abetted an avalanche of aliteration with an article that forecast trends in the industry, gathering them under the headings Data Volume, Data Velocity, and Data Variety. Of course inflation continues its inexorable march, and about a decade later we had the 4 V's of Big Data, then 7 V's, and then 10 V's.
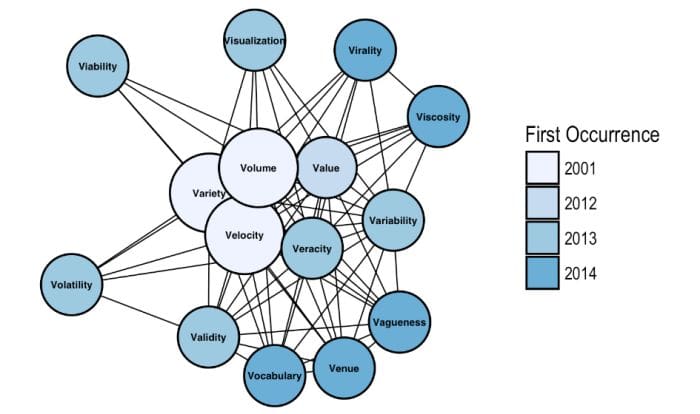
But it's 2017 now, and we now operate in an ever more sophisticated world of analytics. To keep up with the times, we present our updated 2017 list: The 42 V's of Big Data and Data Science.
- Vagueness: The meaning of found data is often very unclear, regardless of how much data is available.
- Validity: Rigor in analysis (e.g., Target Shuffling) is essential for valid predictions.
- Valor: In the face of big data, we must gamely tackle the big problems.
- Value: Data science continues to provide ever-increasing value for users as more data becomes available and new techniques are developed.
- Vane: Data science can point in the direction of correct decision making.
- Vanilla: Even the simplest models, constructed with rigor, can provide value.
- Vantage: Big data allows us a privileged view of complex systems.
- Variability: Data science often models variable data sources. Models deployed into production can encounter especially wild data.
- Variety: In data science, we work with many data formats (flat files, relational databases, graph networks) and varying levels of data completeness.
- Varifocal: Big data and data science together allow us to see both the forest and the trees.
- Varmint: As big data gets bigger, so can software bugs!
- Varnish: How end-users interact with our work matters, and polish counts.
- Vastness: With the advent of the internet of things, the "bigness" of big data is accelerating.
- Vaticination: Predictive analytics provides the ability to forecast. (Of course, these forecasts can be more or less accurate depending on rigor and the complexity of the problem. The future is pesky and never conforms to our March Madness brackets.)
- Vault: With many data science applications based on large and often sensitive data sets, data security is increasingly important.
- Veer: With the rise of agile data science, we should be able to navigate the customer's needs and change directions quickly when called upon.
- Veil: Data science provides the capability to peer behind the curtain and examine the effects of latent variables in the data.
- Velocity: Not only is the volume of data ever increasing, but the rate of data generation (from the internet of things, social media, etc.) is increasing as well.
- Venue: Data science work takes place in different locations and under different arrangements: Locally, on customer workstations, and in the cloud.
- Veracity: Reproducibility is essential for accurate analysis.
- Verdict: As an increasing number of people are affected by models' decisions, Veracity and Validity become ever more important.
- Versed: Data scientists often need to know a little about a great many things: mathematics, statistics, programming, databases, etc.
- Version Control: You're using it, right?
- Vet: Data science allows us to vet our assumptions, augmenting intuition with evidence.
- Vexed: Some of the excitement around data science is based on its potential to shed light on large, complicated problems.
- Viability: It is difficult to build robust models, and it's harder still to build systems that will be viable in production.
- Vibrant: A thriving data science community is vital, and it provides insights, ideas, and support in all of our endeavors.
- Victual: Big data — the food that fuels data science.
- Viral: How does data spread among other users and applications?
- Virtuosity: If data scientists need to know a little about many things, we should also grow to know a lot about one thing.
- Viscosity: Related to Velocity; how difficult is the data to work with?
- Visibility: Data science provides visibility into complex big data problems.
- Visualization: Often the only way customers interact with models.
- Vivify: Data science has the potential to animate all manner of decision making and business processes, from advertising to fraud detection.
- Vocabulary: Data science provides a vocabulary for addressing a variety of problems. Different modeling approaches tackle different problem domains, and different validation techniques harden these approaches in different applications.
- Vogue: "Machine Learning" which becomes "Artificial Intelligence", which becomes...?
- Voice: Data science provides the ability to speak with knowledge (though not all knowledge, of course) on a diverse range of topics.
- Volatility: Especially in production systems, one has to prepare for data volatility. Data that should "never" be missing suddenly disappears, numbers suddenly contain characters!
- Volume: More people use data-collecting devices as more devices become internet-enabled. The volume of data is increasing at a staggering rate.
- Voodoo: Data science and big data aren't voodoo, but how can we convince potential customers of data science's value to deliver results with real-world impact?
- Voyage: May we always keep learning as we tackle the problems that data science provides.
- Vulpine: Nate Silver would like you to be a fox, please.
Besides our own additions, this list of V's incorporates the lists of several articles written over the last few years:
- 3 V's, 2001 (and again)
- 4 V's, 2012 (and again)
- 4 V's, 2013
- 7 V's, 2013
- 6 V's, 2013
- 5 V's, 2013
- 10 V's, 2014
- 8 V's, 2014
- 5 V's, 2014 (and again)
These nine distinct sets encompass fifteen different "V's," orbiting the original three. We can safely say we are now well on the way to 100 V's of Big Data and Data Science!
 Bio: Tom Shafer joined Elder Research after completing a Ph.D. in Physics at the University of North Carolina. In his research, Dr. Shafer computed the decay properties of heavy atomic nuclei to study an astrophysical process that formed the heaviest elements. Those computations were made possible by collaboratively developing a new parallel computing algorithm to calculate nuclear properties. Tom also earned degrees in Physics and Mathematics from the University of North Carolina at Wilmington.
Bio: Tom Shafer joined Elder Research after completing a Ph.D. in Physics at the University of North Carolina. In his research, Dr. Shafer computed the decay properties of heavy atomic nuclei to study an astrophysical process that formed the heaviest elements. Those computations were made possible by collaboratively developing a new parallel computing algorithm to calculate nuclear properties. Tom also earned degrees in Physics and Mathematics from the University of North Carolina at Wilmington.
Related: