How A Data Scientist Can Improve Productivity
Data Science projects involve iterative processes and may need changes in data at every iteration. But Data versioning, data pipelines and data workflows make Data Scientist’s life easy, let’s see how.
By Dmitry Petrov, @FullStackML.
Data science and machine learning are iterative processes. It is never possible to successfully complete a data science project in a single pass. A data scientist constantly tries new ideas and changes steps of his pipeline:
- extract new features and accidentally find noise in the data
- clean up the noise, find one more promising feature
- extract the new feature
- rebuild and validate the model, realize that the learning algorithm parameters are not perfect for the new feature set
- change machine learning algorithm parameters and retrain the model
- find the ineffective feature subset and remove it from the feature set
- try a few more new features
- try another ML algorithm. And then a data format change is required.
 This is only a small episode in a data scientist’s daily life and it is what makes our job different from a regular engineering job.
This is only a small episode in a data scientist’s daily life and it is what makes our job different from a regular engineering job.
Business context, ML algorithm knowledge and intuition all help you to find a good model faster. But you never know for sure what ideas will bring you the best value.
This is why the iteration time is a critical parameter in data science process. The quicker you iterate, the more you can check ideas and build a better model.
“A well-engineered pipeline gets data scientists iterating much faster, which can be a big competitive edge” From Engineering Practices in Data Science By Chris Clark.
A data science iteration tool
To speed up the iterations in data science projects we have created an open source tool data version control or DVC.
DVC takes care of dependencies between commands that you run, generated data files, and code files and allows you to easily reproduce any steps of your research with regards to files changes.
You can think about DVC as a Makefile for a data science project even though you do not create a file explicitly. DVC tracks dependencies in your data science projects when you run data processing or modeling code through a special command:
$ dvc run python code/xml_to_tsv.py data/Posts.xml data/Posts.tsv python
dvc run works as a proxy for your commands. This allows DVC to track input and output files, construct the dependency graph (DAG), and store the command and parameters for a future command reproduction.
The previous command will be automatically piped with the next command because of the file data/Posts.tsv is an output for the previous command and the input for the next one:
# Split training and testing dataset. Two output files. # 0.33 is the test dataset splitting ratio. 20170426 is a seed for randomization. $ dvc run python code/split_train_test.py data/Posts.tsv 0.33 20170426 data/ Posts-train.tsv data/Posts-test.tsv
DVC derives the dependencies automatically by looking to the list of the parameters (even if your code ignores the parameters) and noting the file changes before and after running the command.
If you change one of your dependencies (data or code) then all the affected steps of the pipeline will be reproduced:
# Change the data preparation code. $ vi code/xml_to_tsv.py
# Reproduce. $ dvc repro data/Posts-train.tsv Reproducing run command for data item data/Posts.tsv. Args: python code/xml_to_tsv.py data/Posts.xml data/Posts.tsv python Reproducing run command for data item data/Posts-train.tsv. Args: python code/split_train_test.py data/Posts.tsv 0.33 20170426 data/Posts -train.tsv data/Posts-test.tsv
This is a powerful way of quickly iterating through your pipeline.
The pipeline might have a lot of steps and forms of acyclic dependencies between the steps. Below is an example of a canonical machine learning pipeline (more details in the DVC tutorial):
| # Install DVC
$ pip install dvc |
|
| # Initialize DVC repository | |
| $ dvc init | |
| # Download a file and put to data/ directory. | |
| $ dvc import https://s3-us-west-2.amazonaws.com/dvc-share/so/25K/Posts.xml.tgz data/ | |
| # Extract XML from the archive. | |
| $ dvc run tar zxf data/Posts.xml.tgz -C data/ | |
| # Prepare data. | |
| $ dvc run python code/xml_to_tsv.py data/Posts.xml data/Posts.tsv python | |
| # Split training and testing dataset. Two output files. | |
| # 0.33 is the test dataset splitting ratio. 20170426 is a seed for randomization. | |
| $ dvc run python code/split_train_test.py data/Posts.tsv 0.33 20170426 data/Posts-train.tsv data/Posts-test.tsv | |
| # Extract features from text data. Two TSV inputs and two pickle matrixes outputs. | |
| $ dvc run python code/featurization.py data/Posts-train.tsv data/Posts-test.tsv data/matrix-train.p data/matrix-test.p | |
| # Train ML model out of the training dataset. 20170426 is another seed value. | |
| $ dvc run python code/train_model.py data/matrix-train.p 20170426 data/model.p | |
| # Evaluate the model by the testing dataset. | |
| $ dvc run python code/evaluate.py data/model.p data/matrix-test.p data/evaluation.txt | |
| # The result. | |
| $ cat data/evaluation.txt | |
| AUC: 0.596182 |
Why are regular pipeline tools not enough?
“Workflows are expected to be mostly static or slowly changing.” (See https://airflow.incubator.apache.org/).
Regular pipeline tools like Airflow and Luigi are good for representing static and fault tolerant workflows. A huge portion of their functionality is created for monitoring, optimization and fault tolerance. These are very important and business critical problems. However, these problems are irrelevant to data scientists’ daily lives.
Data scientists need a lightweight, dynamic workflow management system. In contrast to the traditional airflow-like system, DVC reflects the process of researching and looking for a great model (and pipeline), not optimizing and monitoring an existing one. This is why DVC is a good fit for iterative machine learning processes. When a good model was discovered with DVC, the result could be incorporated into a data engineering pipeline (Luigi or Airflow).
Pipelines and data sharing
In addition to pipeline description, data reproduction and dynamic nature, DVC has one more important feature. It was designed in accordance with the best software engineering practices. DVC is based on Git. It keeps code, and stores DAG in the Git repository which allows you to share your research results. But it moves the actual file content outside the Git repository (in .cache directory which DVC includes in .gitignore) since Git is not designed to accommodate large data files.
The data files can be shared between data scientists through cloud storages using a simple command:
# Data scientists 1 syncs data to the cloud. $ dvc sync data/
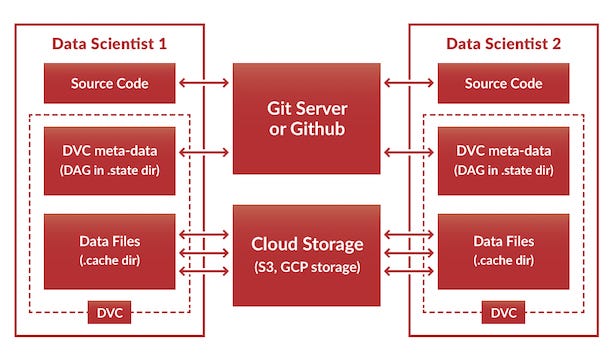
Currently, AWS S3 and GCP storage are supported by DVC.
Conclusion
The productivity of data scientists can be improved by speeding up iteration processes and the DVC tool takes care of this.
We are very interested in your opinion and feedback. Please post your comments here or contact us on Twitter — FullStackML.
If you found this tool useful, please “star” the DVC Github repository.
Original. Reposted with permission.
Bio: Dmitry Petrov is building the future of data science tooling DataVersionControl. Ex-Data Scientist at Microsoft. Ex-Researcher. PhD in CS.
Related: