 Deep Learning – Past, Present, and Future
Deep Learning – Past, Present, and Future
 Deep Learning – Past, Present, and Future
Deep Learning – Past, Present, and FutureThere is a lot of buzz around deep learning technology. First developed in the 1940s, deep learning was meant to simulate neural networks found in brains, but in the last decade 3 key developments have unleashed its potential.
By Henry H. Eckerson, Eckerson Group.
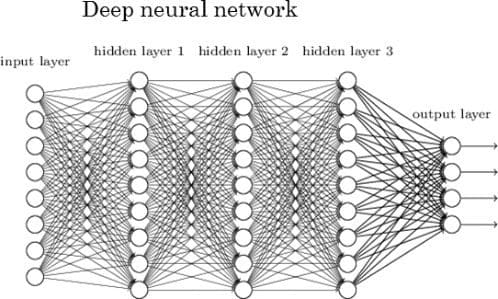
From Neural Networks and Deep Learning, by Michael Nielsen.
Deep learning is exploding. According to Gartner, the number of open positions for deep learning experts grew from almost zero in 2014 to 41,000 today. Much of this growth is being driven by high tech giants, such as Facebook, Apple, Netflix, Microsoft, Google, and Baidu.
These big players and others have invested heavily in deep learning projects. Besides hiring experts, they have funded deep learning projects and experiments and acquired deep learning related companies. And these investments are only the beginning. Gartner predicts that 80% of data scientists will be using deep learning tools by 2018.
Deep learning technology, which is meant to simulate biological neural networks in brains, arose in the 1950s, along with the first computers. So, if computers and deep learning began development together, why is deep learning only now reaching a mainstream computing audience?
The increased processing power afforded by graphical processing units (GPUs), the enormous amount of available data, and the development of more advanced algorithms has led to the rise of deep learning.
The Current State Of Deep Learning
Deep learning is all around us. It’s used to determine which online ads to display in real time, identify and tags friends in photos, translate your voice to text, translate text into different languages on a Web page, and drive autonomous vehicles.
Deep learning is also found in less visible places. Credit card companies use deep learning for fraud detection; businesses use it to predict whether you will cancel a subscription and provide personalized customer recommendations; banks use it to predict bankruptcy and loan risk; hospitals use it for detection, diagnosis, and treatment of diseases.
The range of applications is almost limitless. Other options include text analysis, image captioning, image colorization, x-ray analysis, weather forecasts, finance predictions, and more.
Deep learning is already being widely used to automate processes, improve performance, detect patterns, and solve problems.
What Is Deep Learning?
Deep learning falls under the umbrella of machine learning which is a subset of artificial intelligence (AI). Loosely defined, artificial intelligence encompasses technology that simulates human capabilities while machine learning algorithms learn and adapt to new events.
Deep learning is a term for technologies that use artificial neural network (ANNs) algorithms. Experts consider deep learning and ANNs to be the same thing and use the terms interchangeably. Just like neural networks in brains, ANNs have neurons (nodes) interconnected by synapses (links). Each node receives data, performs an operation, and passes the new data to another node via a link. The links contain weights or biases that influence the next node’s operation.
To illustrate the roles of nodes and links, imagine a company that wants to predict whether a customer will renew a subscription based on two predictors, gender and age. The company’s neural network has two input nodes–one for each predictor–connected via separate links to one output node. Gender and age values are fed into the input nodes. Those values are multiplied by preset weights in the links. If age happens to be a better predictor than gender, then the link that sends age data will have a higher weight.
The output node adds the weighted data from the input nodes and produces a value, which equates to a prediction. In this simplified example, the value could be between 0 and 1. The closer the value is to 1, the more likely the customer is to renew the subscription.
In a real project, ANNs may contain thousands of nodes and billions of links. Each node belongs to a layer, which is a group of nodes. There are input layers, output layers, and layers in between the two, which are known as hidden layers. Adding nodes, links, and layers increases the accuracy of the ANN.
Role of Training. Once built, ANNs require a lot of ‘training’ to work well. An untrained ANN will always fail. This is where the ‘learning’ in deep learning comes into play.
Data scientists can use supervised or unsupervised training. Under supervised training, ANNs process input values from test data and produce output values (predictions), which are compared to the real output values from the test data. Then, a training algorithm, specifically designed to train ANNs, is applied. A few types of training algorithms exist, but the most widely used type is called backpropagation. The backpropagation algorithm identifies the parts of the ANN responsible for an inaccurate prediction by following the error in the output nodes back through the ANN to the hidden and input layers and changes the weights accordingly. This process is repeated over and over until the ANN produces consistent, accurate predictions with the test data. Then, the ANN is ready to process new input values and predict unknown output values.
The purpose of unsupervised training is to model the structure or distribution of data, not to produce a predictor. So with unsupervised training, once an ANN processes input data, the weights do not need to be changed because there is no corresponding output data to compare the ANN’s prediction to.
Deep Learning Is Old Technology
The best place to start the AI and deep learning story is with William McCulloch and Walter Pitts. In 1943, they published A Logical Calculus of the Ideas Immanent in Nervous Activity in which they outlined the first computational model of a neural network. This paper served as the blueprint for the first ANNs.
Six years later, Donald Hebb published The Organization of Behavior, which argued that the connections between neurons strengthened with use. This concept proved fundamental to understanding human learning and how to train ANNs.
In 1954, Belmont Farley and Wesley Clark, using the research done by McCulloch and Pitts, ran the first computer simulations of an artificial neural network. These networks of up to 128 neurons were trained to recognize simple patterns.
In the summer of 1956, computer scientists met “to act on the conjecture that every aspect of learning or any other feature of intelligence can in principle be so precisely described that a machine can be made to simulate it.” This event, known as the Dartmouth Conference, is considered the birthplace of AI.
Following the Dartmouth Conference, the field of artificial intelligence took off. In 1957, Frank Rosenblatt began to study a type of neural network he called the perceptron and was able to apply the training method Farley and Clark used on their two-layer networks to multi-layer ones.
In 1959, Bernard Widrow and Marcian Hoff developed a single layer neural network they called ADALINE short for Adaptive Linear Elements, which could predict the next bit of information on an incoming phone call based on the prior bits. Their next development, a multilayer neural network called MADALINE, eliminated echoes on phone calls and is said to be the first practical application of an ANN.
Innovations continued through the ‘60s, but funding, research, and advances slowed in the ‘70s. AI scientists’ accomplishments failed to live up to media hype and government expectations. The so-called ‘AI winter’ ensued during which there was little funding and minimal research done on the topic.
Starting in 1986, research resurged for a few years after Geoff Hinton published Learning Representations by Back-propagating Errors, which describes the backpropagation learning procedure. However, true resurgence did not occur until the mid 2000s. Today, deep learning and AI are in deep bloom, and some would say overhyped.
So, Why Are ANNs Becoming Useful Now?
Three factors have unleashed the potential of deep learning:
1. The Exponential Explosion of Available Data
According to Cisco, the global Internet traffic in 1992 was 100 GB per day. In 2015, that number was 17.5 million times greater at 20,235 GB per second. Now, 90% of the world’s data has been created in the last two years.
Without this data, training ANNs containing millions of connections and thousands of nodes could not happen. For an ANN to recognize a face, detect credit fraud, or translate a voice to text in a noisy room it takes more than just a few bits of test data for consistent, accurate predictions. This is why ANNs flourish in the age of big data.
The best and most visible example of data enabling an ANN is a project led by Google X, a somewhat secretive research and development team. Led by Andrew Ng, until recently the chief scientist at Baidu Research, and Jeff Dean, a Google Senior Fellow, the team assembled a 16,000 central processing units (CPUs) to power a ANN with over a billion connections.
The ANN then underwent training, processing 10 million images from randomly selected YouTube videos. According to many sources, the ANN trained itself to recognize cats. In reality, only one node in the ANN was responsible for recognizing cat images. Other nodes could identify human bodies and faces. Two decades ago, it would have been impossible to collect 10 million images to train the ANN.
Next, we look at the rise of the GPU.