 Web Scraping Tutorial with Python: Tips and Tricks
Web Scraping Tutorial with Python: Tips and Tricks
 Web Scraping Tutorial with Python: Tips and Tricks
Web Scraping Tutorial with Python: Tips and TricksThis post is intended for people who are interested to know about the common design patterns, pitfalls and rules related to the web scraping.
I was searching for flight tickets and noticed that ticket prices fluctuate during the day. I tried to find out when the best time to buy tickets is, but there was nothing on the Web that helped. I built a small program to automatically collect the data from the web — a so-called scraper. It extracted information for my specific flight destination on predetermined dates and notified me when the price got lower.
Web scraping is a technique used to extract data from websites through an automated process.
I learned a lot from this experience with Web scraping, and I want to share it.
This post is intended for people who are interested to know about the common design patterns, pitfalls and rules related to the web scraping. The article presents several use cases and a collection of typical problems, such as how not to be detected, dos and don’ts, and how to speed up (parallelization) your scraper.
Everything will be accompanied by python snippets, so that you can start straight away. This document will also go through several useful python packages.
Use Cases
There are many reasons and use cases why you would want to scrape data. Let me list some of them:
- scrape pages of a e-retailer to spot if some of the clothes you want to buy got discounted
- compare prices of several clothes brands by scraping their pages
- price of the flight tickets can vary during the day. One could crawl the travel website and get alarmed once the price was lowered
- analyze the action websites to answer the question if starting bid should be low or high to attract more bidders or if the longer auction correlates with a higher end bid
Tutorial
Structure of the tutorial:
- Available packages
- Basic code
- Pitfalls
- Dos and dont’s
- Speed up — parallelization
Before we start: Be NICE to the servers; you DON’T want to crash a website.
1. Available packages and tools
There is no universal solution for web scraping because the way data is stored on each website is usually specific to that site. In fact, if you want to scrape the data, you need to understand the website’s structure and either build your own solution or use a highly customizable one.
However, you don’t need to reinvent the wheel: there are many packages that do the most work for you. Depending on your programming skills and your intended use case, you might find different packages more or less useful.
1.1 Inspect option
Most of the time you will finding yourself inspecting the HTML the website. You can easily do it with an “inspect” option of your browser.
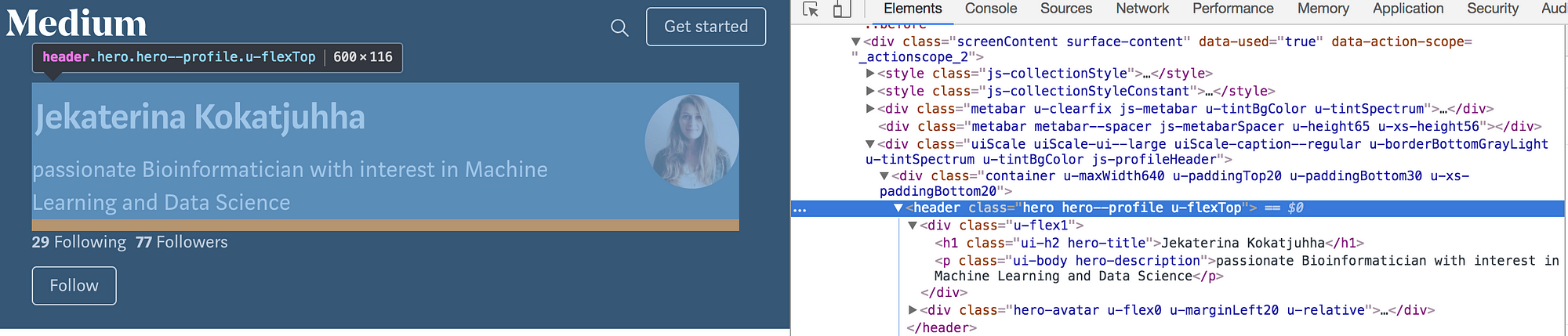
The section of the website that holds my name, my avatar and my description is called hero hero--profile u-flexTOP (how interesting that Medium calls its writers ‘heroes’ :)). The <h1> class that holds my name is calledui-h2 hero-title and the description is contained within the <p> class ui-body hero-description.
You can read more about HTML tags, and differences between classes and ids here.
1.2 Scrapy
There is a stand-alone ready-to-use data extracting framework called Scrapy. Apart from extracting HTML the package offers lots of functionalities like exporting data in formats, logging etc. It is also highly customisable: run different spiders on different processes, disable cookies1 and set download delays2. It can also be used to extract data using API. However, the learning curve is not smooth for the new programmers: you need to read tutorials and examples to get started.
1 Some sites use cookies to identify bots.
2 The website can get overloaded due to a huge amount of crawling requests.
For my use case it was too much ‘out of the box’: I just wanted to extract the links from all pages, access each link and extract information out of it.
1.3 BeautifulSoup with Requests
BeautifulSoup is a library that allows you to parse the HTML source code in a beautiful way. Along with it you need a Request library that will fetch the content of the URL. However, you should take care of everything else like error handling, how to export data, how to parallelize the web scraper, etc.
I chose BeautifulSoup as it would force me to figure out a lot of stuff that Scrapy handles on its own, and hopefully help me learn faster from my mistakes.
2. Basic code
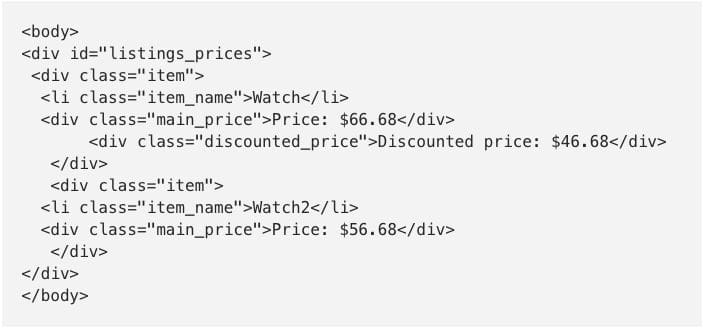
It’s very straightforward to start scraping a website. Most of the time you will find yourself inspecting HTML of the website to access the classes and IDs you need. Lets say we have a following html structure and we want to extract the main_price elements. Note: discounted_price element is optional.
The basic code would be to import the libraries, do the request, parse the html and then to find the class main_price.
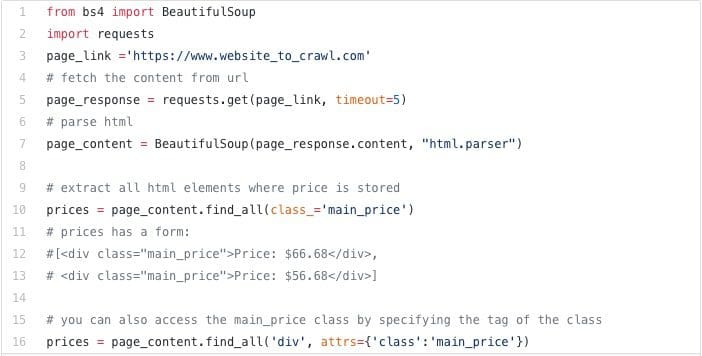
It can happen that the class main_price is present in another section of the website. To avoid extracting unnecessary class main_price from any other part of the webpage we could have first addressed the id listings_pricesand only then find all elements with class main_price.
3. Pitfalls
3.1 Check robots.txt
The scraping rules of the websites can be found in the robots.txt file. You can find it by writing robots.txt after the main domain, e.g www.website_to_scrape.com/robots.txt. These rules identify which parts of the websites are not allowed to be automatically extracted or how frequently a bot is allowed to request a page. Most people don’t care about it, but try to be respectful and at least look at the rules even if you don’t plan to follow them.
3.2 HTML can be evil
HTML tags can contain id, class or both. HTML id specifies a unique id and HTML class is non-unique. Changes in the class name or element could either break your code or deliver wrong results.
There are two ways to avoid it or at least to be alerted about it:
- Use specific
idrather thanclasssince it is less likely to be changed - Check if the element returns
None
price = page_content.find(id='listings_prices')
# check if the element with such id exists or not
if price is None:
# NOTIFY! LOG IT, COUNT IT
else:
# do something
However, because some fields can be optional (like discounted_price in our HTML example), corresponding elements would not appear on each listing. In this case you can count the percentage of how many times this specific element returned None to the number of listings. If it is 100%, you might want to check if the element name was changed.
3.3 User agent spoofing
Every time you visit a website, it gets your browser information via user agent. Some websites won’t show you any content unless you provide a user agent. Also, some sites offer different content to different browsers. Websites do not want to block genuine users but you would look suspicious if you send 200 requests/second with the same user agent. A way out might be either to generate (almost) random user agent or to set one yourself.
# library to generate user agent
from user_agent import generate_user_agent
# generate a user agent
headers = {'User-Agent': generate_user_agent(device_type="desktop", os=('mac', 'linux'))}
#headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux i686 on x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.63 Safari/537.36'}
page_response = requests.get(page_link, timeout=5, headers=headers)
3.4 Timeout request
By default, Request will keep waiting for a response indefinitely. Therefore, it is advised to set the timeout parameter.
# timeout is set to 5 seconds page_response = requests.get(page_link, timeout=5, headers=headers)
3.5 Did I get blocked?
Frequent appearance of the status codes like 404 (Not Found), 403 (Forbidden), 408 (Request Timeout) might indicate that you got blocked. You may want to check for those error codes and proceed accordingly. Also, be ready to handle exceptions from the request.
try:
page_response = requests.get(page_link, timeout=5)
if page_response.status_code == 200:
# extract
else:
print(page_response.status_code)
# notify, try again
except requests.Timeout as e:
print("It is time to timeout")
print(str(e))
except # other exception
3.6 IP Rotation
Even if you randomize your user agent, all your requests will be from the same IP address. That doesn’t sound abnormal because libraries, universities, and also companies have only a few IP addresses. However, if there are uncommonly many requests coming from a single IP address, a server can detect it.
Using shared proxies, VPNs or TOR can help you become a ghost ;).
proxies = {'http' : 'http://10.10.0.0:0000',
'https': 'http://120.10.0.0:0000'}
page_response = requests.get(page_link, proxies=proxies, timeout=5)
By using a shared proxy, the website will see the IP address of the proxy server and not yours. A VPN connects you to another network and the IP address of the VPN provider will be sent to the website.
3.7 Honeypots
Honeypots are means to detect crawlers or scrapers.
These can be ‘hidden’ links that are not visible to the users but can be extracted by scrapers/spiders. Such links will have a CSS style set to display:none, they can be blended by having the color of the background, or even be moved off of the visible area of the page. Once your crawler visits such a link, your IP address can be flagged for further investigation, or even be instantly blocked.
Another way to spot crawlers is to add links with infinitely deep directory trees. Then one would need to limit the number of retrieved pages or limit the traversal depth.
4. Dos and Don'ts
- Before scraping, check if there is a public API available. Public APIs provide easier and faster (and legal) data retrieval than web scraping. Check out Twitter API that provides APIs for different purposes.
- In case you scrape lots of data, you might want to consider using a database to be able to analyze or retrieve it fast. Follow this tutorial on how to create a local database with python.
- Be polite. As this answer suggests, it is recommended to let people know that you are scraping their website so they can better respond to the problems your bot might cause.
Again, do not overload the website by sending hundreds of requests per second.
5. Speed up — parallelization
If you decide to parallelize your program, be careful with your implementation so you don’t slam the server. And be sure you read the Dos and Don’ts section. Check out the the definitions of parallelization vs concurrency, processors and threads here and here.
If you extract a huge amount of information from the page and do some preprocessing of the data while scraping, the number of requests per second you send to the page can be relatively low.
For my other project where I scraped apartment rental prices, I did heavy preprocessing of the data while scraping, which resulted in 1 request/second. In order to scrape 4K ads, my program would run for about one hour.
In order to send requests in parallel you might want to use a multiprocessing package.
Let’s say we have 100 pages and we want to assign every processor equal amount of pages to work with. If n is the number of CPUs, you can evenly chunk all pages into the n bins and assign each bin to a processor. Each process will have its own name, target function and the arguments to work with. The name of the process can be used afterwards to enable writing data to a specific file.
I assigned 1K pages to each of my 4 CPUs which yielded 4 requests/second and reduced the scraping time to around 17 mins.
import numpy as np
import multiprocessing as multi
def chunks(n, page_list):
"""Splits the list into n chunks"""
return np.array_split(page_list,n)
cpus = multi.cpu_count()
workers = []
page_list = ['www.website.com/page1.html', 'www.website.com/page2.html'
'www.website.com/page3.html', 'www.website.com/page4.html']
page_bins = chunks(cpus, page_list)
for cpu in range(cpus):
sys.stdout.write("CPU " + str(cpu) + "\n")
# Process that will send corresponding list of pages
# to the function perform_extraction
worker = multi.Process(name=str(cpu),
target=perform_extraction,
args=(page_bins[cpu],))
worker.start()
workers.append(worker)
for worker in workers:
worker.join()
def perform_extraction(page_ranges):
"""Extracts data, does preprocessing, writes the data"""
# do requests and BeautifulSoup
# preprocess the data
file_name = multi.current_process().name+'.txt'
# write into current process file
Happy scraping!
Bio: Jekaterina Kokatjuhha is a passionate Bioinformatician with interest in Machine Learning and Data Science.
Original. Reposted with permission.
Related
- Using AutoML to Generate Machine Learning Pipelines with TPOT
- A Primer on Web Scraping in R
- Web Scraping for Data Science with Python