Operational Machine Learning: Seven Considerations for Successful MLOps
In this article, we describe seven key areas to take into account for successful operationalization and lifecycle management (MLOps) of your ML initiatives
By Nisha Talagala, ParallelM.
Machine learning is everywhere. From advertising to IoT to healthcare, and beyond, virtually all industries are adopting or investigating machine learning (ML) to benefit their business. However, to generate a positive return on investment (ROI) using ML, it needs to be operationalized or put into production.
Bringing machine learning into production incurs a unique set of challenges.
The first step in operationalization is knowing what your ML application looks like, what its moving parts are and how they need to work together.
1: Knowing your ML Application
In most cases, ML is used to optimize (i.e. add insights to) a business application. While this sounds simple, an ML operation frequently requires multiple complementary but independent ML programs (training, inference, etc.) to run in cooperation. What is an ML application? An ML application is the collection of programs and dependencies that together deliver the ML functionality to your business application.
Figure 1(a) shows the most basic way that ML can be added to a business application. The business application makes requests for predictions, which can be served by an ML inference program (micro-services approaches are popular here). The ML inference program uses a model that was trained offline, likely by a data scientist. While this flow is simple, it is frequently not sufficient. Industries where data changes frequently (such as Adtech) require models to be frequently retrained to keep up with changing circumstances. A re-training pipeline then needs to be added to feed the inference, resulting in the pattern in Figure 1(b).
Retraining brings many models into the mix, and human intervention may be required to decide which ones to deploy to production (this is particularly important in situations where fiscal, health or other outcomes are tied to ML predictions). Adding human approvals results in Figure 1(c). If advanced algorithms (like ensemble models) are used to improve accuracy, the pattern becomes that of Figure 1(d).
Finally, many production deployments use multiple prediction pipelines in parallel (Champion/Challenger, Canary etc.) to monitor prediction patterns, and detect unexpected shifts or anomalies. Adding such test infrastructure generates a pattern similar to Figure 1(e).
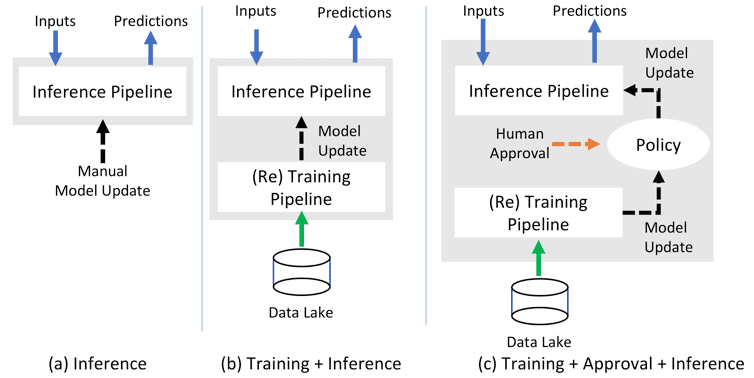
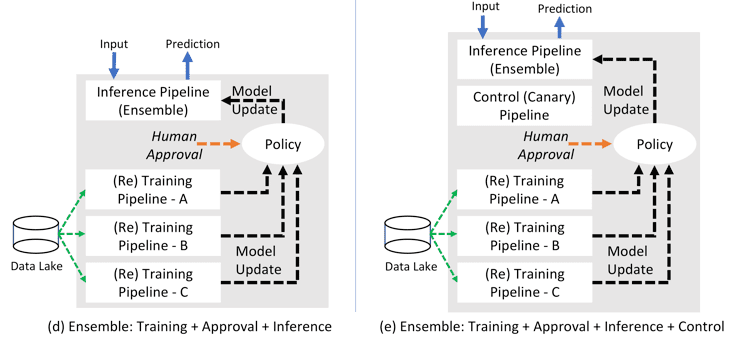
Figure 1: ML Applications
Once your ML application is defined, the next step is to ensure that it can be safely and successfully put into production.
Return on Investment: The ML application should improve its companion business application, while staying within the requirements of your industry and organization.
2: Measuring Success
ML applications exist to serve a business need. Success metrics or key performance indicators (KPIs) for the business application should be tracked and correlated with the introduction of, and subsequent optimizations to, the ML application. Such correlation provides visibility for all stakeholders, ensures that ML investments are generating adequate returns and helps everyone from data scientists, to operations personnel measure and justify new operational investments.
3: Manage Production ML Risk
Risk management does not end at model development. Once operational, models need to be monitored and constantly evaluated to ensure that they are operating within expected bounds. Production ML health is complicated by the fact that live data does not have labels (and as such common metrics such as Accuracy, Precision, Recall etc. cannot be used). Alternative methods (such as Data Deviation Detection, Drift Detection, Canary Pipelines, Production A/B tests) should be part of the ML application.
4: Ensure Governance and Compliance
Some industries, such as financial services, have had ML compliance requirements for many years. Other industries and geographies are beginning to introduce guidelines, such as GDPR in the EU or the New York City Algorithmic Accountability Bill. A comprehensive production governance mechanism is critical to ensure that ML applications (and all of their consequent models, pipelines, code, executions, etc.) are tracked for reproducibility, auditability and to assist explainability.
Harmony with DevOps: MLOps should integrate with existing DevOps while also delivering the additional unique capabilities required to manage ML.
5: Automation
Machine learning pipelines are code, and classic DevOps toolchain components (source code repositories such as Git, automation facilities such as Jenkins, orchestrators such as AirFlow, etc.) play an important role in MLOps. However, in addition to the business focus, risk reduction and compliance needs, production ML also presents additional CI/CD and orchestration challenges that are not addressed by common DevOps toolchains. For example, ML applications like Figure 1(e) can have multiple pipelines executing in parallel, with ML-specific interdependencies (such as Model Approval/Propagation or Drift Detection) that also need to be managed. This ML CI/CD and ML orchestration needs to integrate seamlessly with the DevOps practices already in place in the organization.
6: Scale
ML applications can require hardware configurations and scalability points that are different from the business applications that they serve. For example, training neural network models can require powerful GPUs and training regular ML models can require clusters of CPUs. Depending on the inference implementation, clusters of stream processors, REST endpoints or batch inference operations may be required. Many powerful, production-grade analytic engines (such as Spark, Flink, PyTorch, scikit-learn, etc.) exist to execute ML pipelines. The ML application needs to be sized and mapped to one or more of these engines as necessary for the pipelines within.
Harmony with Organization: MLOps should enable all your organizational functions to work together to make ML work for your business application.
7: People
Production ML requires multiple competencies within an organization (data scientists, data engineers, business analysts and operations) to collaborate. Each needs to see different aspects of the ML application. Data scientists may be preoccupied with metrics of training accuracy, production A/B test confidence or data deviation detection while operations may want to see uptime and resource utilization, and business analysts may want to see improvement of KPIs. The MLOps toolchain needs to provide visibility, managed access control, and collaboration for all such parties.
Summary: Combining it All
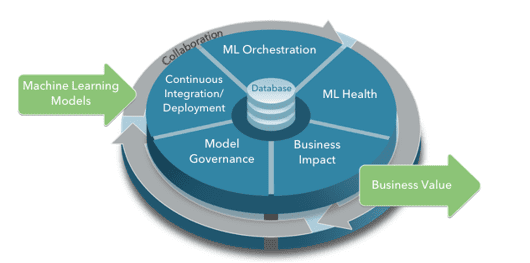
Put together, your MLOps should have all the elements in Figure 2 above, with all elements working together to form a cohesive whole for a successful ML operation.
Bio: Nisha Talagala is CTO/VP Engineering at ParallelM. Her background is in software development for distributed systems, focusing on storage, I/O, file systems, persistent memory and flash non-volatile memory. Prior to PM, She was Lead Architect/Fellow at Fusion-io (acquired by SanDisk), developing new technologies and software stacks for persistent memory, Non-Volatile Memory File System (NVMFS) and application acceleration. She has Ph.D. from UC Berkeley and holds 56 patents.
Related:
- Applying Machine Learning to DevOps
- Data Version Control in Analytics DevOps Paradigm
- What should be focus areas for Machine Learning / AI in 2018?