Presto for Data Scientists – SQL on anything
Presto enables data scientists to run interactive SQL across multiple data sources. This open source engine supports querying anything, anywhere, and at large scale.
By Kamil Bajda-Pawlikowski, CTO of Starburst Data.
Initially developed by Facebook, Presto is an open source, distributed ANSI SQL query engine that delivers fast analytic queries against various data sources ranging in size from gigabytes to petabytes. For data scientists, this is ideal for returning Big Data query results in seconds, accelerating the iterative nature of data science discoveries by powering dashboards, reporting and ad-hoc analysis.
Presto was designed and built from scratch to be a fast SQL query engine. It follows the classic MPP SQL engine design in which query processing is parallelized over a cluster of machines. As a result, highly concurrent queries execute at interactive speeds. However, there is one notable departure from the textbook recipe for a parallel DBMS -- the separation of compute and storage. The architecture of Presto fully abstracts the data sources it can connect to. The Connector API allows building plugins for file systems and object stores, NoSQL stores, relational database systems as well as custom services. As long as data scientists can map their data into relational concepts such as tables, columns, and rows, it is possible to create a Presto connector.
In fact, Presto is available with a large number of existing connectors including HDFS, S3, Cassandra, Accumulo, MongoDB, MySQL, PostgreSQL and other data stores. What’s more, inside a single installation of Presto users can register multiple catalogs and run queries that access data from multiple connectors at once. Additionally, whereas many data science projects and production applications require performing ETL, with Presto you can simply query data where it lives.
For example, imagine correlating customer data from RDBMS with recent events in Kafka and going back to Hadoop or S3 to see how they relate to past trends. This is indeed “SQL-on-Anything.”
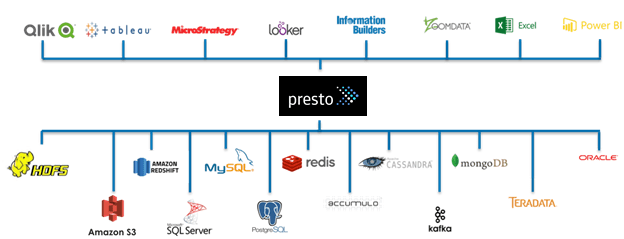
Presto connects many of the most popular Big Data sources with a variety of analytics, BI, dashboard and visualization applications.
Unlike the plethora of SQL-on-Hadoop engines, Hadoop is not required by Presto for Big Data queries and analytics. It can be deployed virtually anywhere, whether on a public cloud, a set of virtual machines or a dedicated cluster on premises. If Hadoop is in the mix, data scientists can rest assured. Presto simply connects to a Hive Metastore allowing users to share the same data with Hive, Spark, and other Hadoop ecosystem tools.An additional benefit of not being dependent on Hadoop is a vendor-neutral approach, and native support for common file formats including Avro, ORC, Parquet, RCFile, Text, etc.
During the last few years, Presto has experienced unprecedented growth in popularity and user adoption at enterprises of all shapes and sizes, from fast-growing Internet companies to the Fortune 500. Beside Facebook, early adopters include Airbnb, Dropbox, Groupon, and Netflix, among others. The acceleration of the Presto roadmap and successful proof-of-concepts has also led to production deployments at Bloomberg, Comcast, FINRA, LinkedIn, and Lyft, as well as Slack, Twitter, Uber and Yahoo! Japan.
Indeed, last month’s Strata Data Conference in San Jose featured talks from several leading Presto adopters discussing their deployments and showcasing interactive speeds, excellent query concurrency and exceptional scalability.
Beyond fast ANSI SQL and access to a variety of data sources, what else does Presto offer to data scientists? Consider ease of use, simple deployment and access via Superset, Redash,Jupyter and numerous JDBC- and ODBC-enabled analyst tools. Presto also integrates well with the data science ecosystem given its bindings for popular programming languages including C, Go, Java, Python, R and Ruby on Rails.
Moreover, Presto features a large number of built-in analytical functions including lambda expressions and functions, window functions, regular expressions, and even geospatial functions -- heavily leveraged publicly by Uber. In addition to standard SQL data types, data scientists are also able to work with complex types such as maps, arrays, structs and JSON.
If this has piqued your interest, I encourage you to download the free, open source Presto and share your story. For many data scientists, this can quickly become a game changer for fast queries of Big Data and interactive analytics.
Related:
- 5 Things You Need to Know about Big Data
- Benchmarking Big Data SQL Platforms in the Cloud
- Want a Job in Data? Learn This