Data Cleaning in SQL: How To Prepare Messy Data for Analysis
Want to clean your messy data so you can start analyzing it with SQL? Learn how to handle missing values, duplicate records, outliers, and much more.

Image generated with Segmind SSD-1B model
Excited to start analyzing data using SQL? Well, you may have to wait just a bit. But why?
Data in database tables can often be messy. Your data may contain missing values, duplicate records, outliers, inconsistent data entries, and more. So cleaning the data before you can analyze it using SQL is super important.
When you're learning SQL, you can spin up database tables, alter them, update and delete records as you like. But in practice, this is almost never the case. You may not have permission to alter tables, update and delete records. But you’ll have read access to the database and will be able to run a bunch of SELECT queries.
In this tutorial, we’ll spin up a database table, populate it with records, and see how we can clean the data with SQL. Let's start coding!
Creating a Database Table with Records
For this tutorial, let’s create an employees table like so:
-- Create the employees table
CREATE TABLE employees (
employee_id INT PRIMARY KEY,
employee_name VARCHAR(50),
salary DECIMAL(10, 2),
hire_date VARCHAR(20),
department VARCHAR(50)
);
Next, let’s insert some fictional sample records into the table:
-- Insert 20 sample records
INSERT INTO employees (employee_id, employee_name, salary, hire_date, department) VALUES
(1, 'Amy West', 60000.00, '2021-01-15', 'HR'),
(2, 'Ivy Lee', 75000.50, '2020-05-22', 'Sales'),
(3, 'joe smith', 80000.75, '2019-08-10', 'Marketing'),
(4, 'John White', 90000.00, '2020-11-05', 'Finance'),
(5, 'Jane Hill', 55000.25, '2022-02-28', 'IT'),
(6, 'Dave West', 72000.00, '2020-03-12', 'Marketing'),
(7, 'Fanny Lee', 85000.50, '2018-06-25', 'Sales'),
(8, 'Amy Smith', 95000.25, '2019-11-30', 'Finance'),
(9, 'Ivy Hill', 62000.75, '2021-07-18', 'IT'),
(10, 'Joe White', 78000.00, '2022-04-05', 'Marketing'),
(11, 'John Lee', 68000.50, '2018-12-10', 'HR'),
(12, 'Jane West', 89000.25, '2017-09-15', 'Sales'),
(13, 'Dave Smith', 60000.75, '2022-01-08', NULL),
(14, 'Fanny White', 72000.00, '2019-04-22', 'IT'),
(15, 'Amy Hill', 84000.50, '2020-08-17', 'Marketing'),
(16, 'Ivy West', 92000.25, '2021-02-03', 'Finance'),
(17, 'Joe Lee', 58000.75, '2018-05-28', 'IT'),
(18, 'John Smith', 77000.00, '2019-10-10', 'HR'),
(19, 'Jane Hill', 81000.50, '2022-03-15', 'Sales'),
(20, 'Dave White', 70000.25, '2017-12-20', 'Marketing');
If you can tell, I’ve used a small set of first and last names to sample from and construct the name field for the records. You can be more creative with the records, though.
Note: All the queries in this tutorial are for MySQL. But you’re free to use the RDBMS of your choice.
1. Missing Values
Missing values in data records are always a problem. So you have to handle them accordingly.
A naive approach is to drop all the records that contain missing values for one or more fields. However, you should not do this unless you’re sure there is no other better way of handling missing values.
In the employees table, we see that there is a NULL value in the ‘department’ column (see row of employee_id 13) indicating that the field is missing:
SELECT * FROM employees;
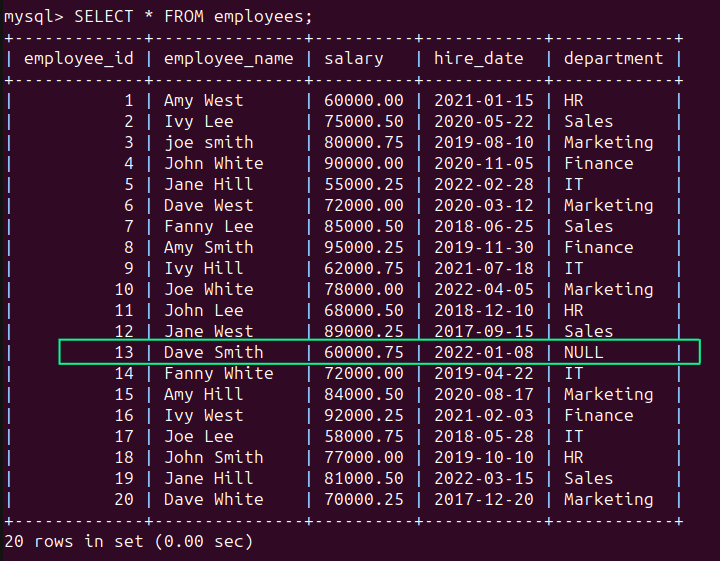
You can use the COALESCE() function to use the ‘Unknown’ string for the NULL value:
SELECT
employee_id,
employee_name,
salary,
hire_date,
COALESCE(department, 'Unknown') AS department
FROM employees;
Running the above query should give you the following result:
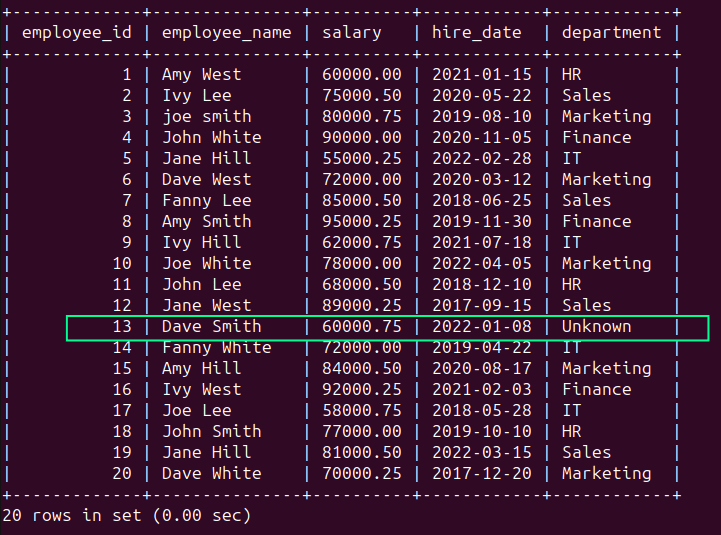
2. Duplicate Records
Duplicate records in a database table can distort the results of analysis. We’ve chosen the employee_id as the primary key in our database table. So we’ll not have any repeating employee records in the employee_data table.
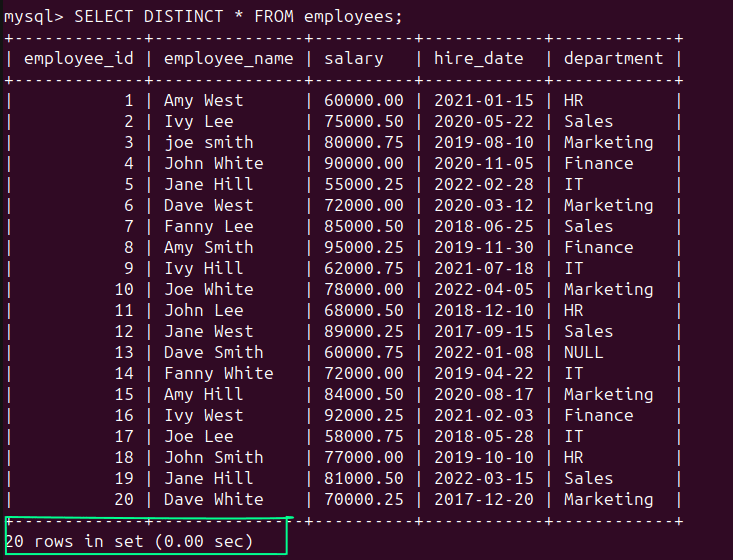
You can still the SELECT DISTINCT statement:
SELECT DISTINCT * FROM employees;
As expected, the result set contains all the 20 records:
3. Data Type Conversion
If you notice, the ‘hire_date’ column is currently VARCHAR and not a date type. To make it easier when working with dates, it’s helpful to use the STR_TO_DATE() function like so:
SELECT
employee_id,
employee_name,
salary,
STR_TO_DATE(hire_date, '%Y-%m-%d') AS hire_date,
department
FROM employees;
Here, we’ve only selected the ‘hire_date’ column amongst others and haven’t performed any operations on the date values. So the query output should be the same as that of the previous query.
But if you want to perform operations such as adding an offset date to the values, this function can be helpful.
4. Outliers
Outliers in one or more numeric fields can skew analysis. So we should check for and remove outliers so as to filter out the data that is not relevant.
But deciding which values constitute outliers requires domain knowledge and data using knowledge of both the domain and historical data.
In our example, let's say we know that the ‘salary’ column has an upper limit of 100000. So any entry in the ‘salary’ column can be at most 100000. And entries greater than this value are outliers.
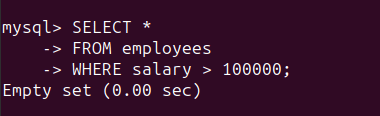
We can check for such records by running the following query:
SELECT *
FROM employees
WHERE salary > 100000;
As seen, all entries in the ‘salary’ column are valid. So the result set is empty:
5. Inconsistent Data Entry
Inconsistent data entries and formatting are quite common especially in date and string columns.
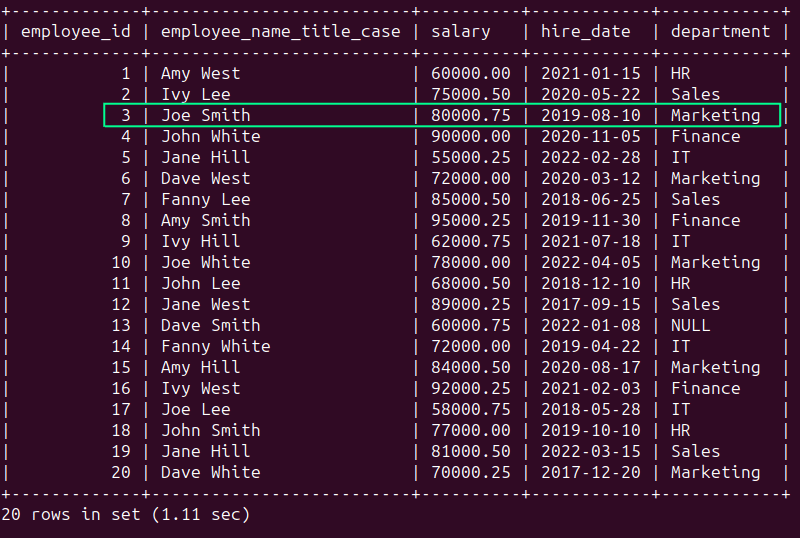
In the employees table, we see that the record corresponding to employee ‘joe smith’ is not in the title case.
But for consistency let's select all the names formatted in the title case. You have to use the CONCAT() function in conjunction with UPPER() and SUBSTRING() like so:
SELECT
employee_id,
CONCAT(
UPPER(SUBSTRING(employee_name, 1, 1)), -- Capitalize the first letter of the first name
LOWER(SUBSTRING(employee_name, 2, LOCATE(' ', employee_name) - 2)), -- Make the rest of the first name lowercase
' ',
UPPER(SUBSTRING(employee_name, LOCATE(' ', employee_name) + 1, 1)), -- Capitalize the first letter of the last name
LOWER(SUBSTRING(employee_name, LOCATE(' ', employee_name) + 2)) -- Make the rest of the last name lowercase
) AS employee_name_title_case,
salary,
hire_date,
department
FROM employees;
6. Validating Ranges
When talking about outliers, we mentioned how we’d like the upper limit on the ‘salary’ column to be 100000 and considered any salary entry above 100000 to be an outlier.
But it's also true that you don't want any negative values in the ‘salary’ column. So you can run the following query to validate that all employee records contain values between 0 and 100000:
SELECT
employee_id,
employee_name,
salary,
hire_date,
department
FROM employees
WHERE salary < 0 OR salary > 100000;
As seen, the result set is empty:
7. Deriving New Columns
Deriving new columns is not essentially a data cleaning step. However, in practice, you may need to use existing columns to derive new columns that are more helpful in analysis.
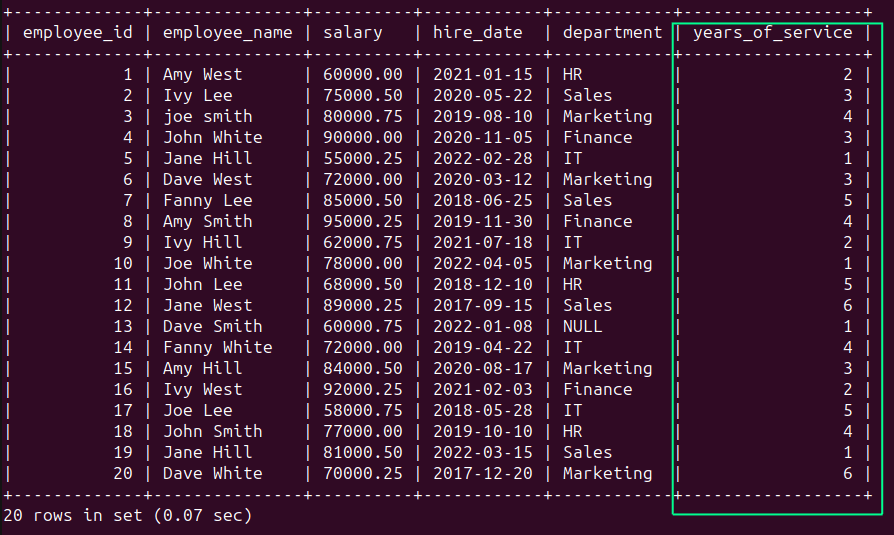
For example, the employees table contains a ‘hire_date’ column. A more helpful field is, perhaps, a ‘years_of_service’ column that indicates how long an employee has been with the company.
The following query finds the difference between the current year and the year value in ‘hire_date’ to compute the ‘years_of_service’:
SELECT
employee_id,
employee_name,
salary,
hire_date,
department,
YEAR(CURDATE()) - YEAR(hire_date) AS years_of_service
FROM employees;
You should see the following output:
As with other queries we’ve run, this does not modify the original table. To add new columns to the original table, you need to have permissions to ALTER the database table.
Wrapping Up
I hope you understand how relevant data cleaning tasks can improve data quality and facilitate more relevant analysis. You’ve learned how to check for missing values, duplicate records, inconsistent formatting, outliers, and more.
Try spinning up your own relational database table and run some queries to perform common data cleaning tasks. Next, learn about SQL for data visualization.
Bala Priya C is a developer and technical writer from India. She likes working at the intersection of math, programming, data science, and content creation. Her areas of interest and expertise include DevOps, data science, and natural language processing. She enjoys reading, writing, coding, and coffee! Currently, she's working on learning and sharing her knowledge with the developer community by authoring tutorials, how-to guides, opinion pieces, and more. Bala also creates engaging resource overviews and coding tutorials.