Latest Trends in Computer Vision Technology and Applications
We investigate the advancements in deep learning, the rise of edge computing, object recognition with point cloud, VR and AR enhanced merged reality, semantic instance segmentation and more.
By Valeryia Shchutskaya, InData Labs.
Computer vision software is changing industries and making the lives of consumers not only easier but also more interesting. As a field, computer vision has received a lot of publicity and a decent amount of investment. The North American market for computer vision software has had a total investment of $120 million USD, while the Chinese market surged to $3.9 billion USD. Let’s take a look at the most promising and more intriguing technologies that make computer vision software development market grow so fast.
Advances in deep learning
Deep learning gained its popularity due to its supremacy in delivering accurate results.
Traditional machine learning algorithms, as complex as they may be, are still very simple at their core. Their training requires a lot of domain expertise (which is expensive), human intervention when errors occur, and in the end, they are only good at the task they’ve been trained at.
Deep learning algorithms, on the other hand, learn about the task at hand through a network of neurons that map the task as a hierarchy of concepts. Each complex concept is defined by a series of simpler concepts. And all of this the algorithms can do by themselves. In the context of computer vision, this means identifying light and dark areas first, then categorizing lines, then shapes before moving towards a full picture recognition.
Deep learning algorithms also perform better when you give them more data, which is not typical of machine learning algorithms.
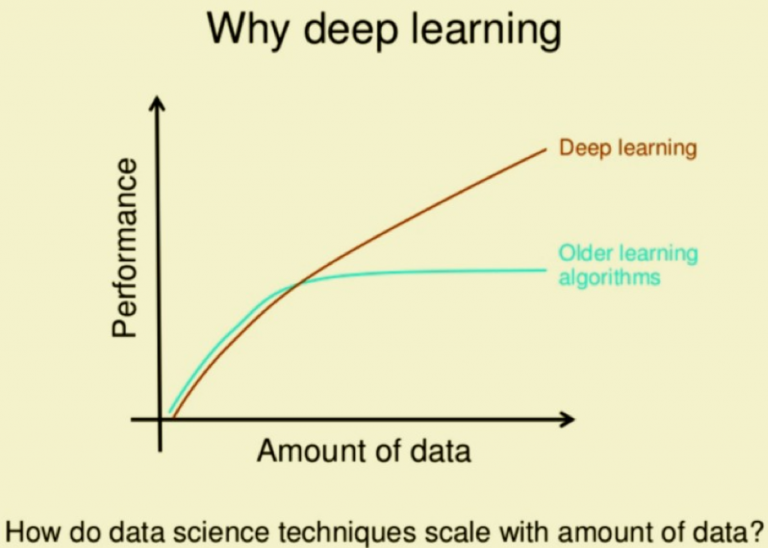
For computer vision, this has been fantastic news. Not only has it allowed for many more pictures and videos to be used in training of deep learning algorithms, but it has also relieved a lot of work connected to annotating and labeling the data.
The retail industry has been a pioneer in implementing computer vision software. ASOS added a search-by-photo option to their app in 2017, and many retailers followed after. Some have even taken it a step further and used computer vision software to bring the online and offline experience closer together.
A gourmet candy retailer called Lolli & Pops uses facial recognition to identify frequent shoppers as they walk into the store. The employees at the store are thus able to personalize the shopping experience by making personalized product recommendations and occasional loyalty discounts.
The special treatment instills brand loyalty and converts occasional shoppers into regular ones. Both of which are good for business.
The rise of edge computing
Machines that connect to the internet and the cloud are able to learn from the data gathered by the network as a whole and adjust accordingly, optimizing the system’s performance. However, connection to the internet and the cloud is not always a guarantee. That is where edge computing comes in.
Edge computing refers to technology attached to physical machines, such as a gas turbine, a jet engine, or an MRI scanner. It allows for the data to be processed and analyzed where it is collected, as opposed to it being done in the cloud or at a data center.
Edge computing doesn’t replace the cloud. It simply allows machines to act alone on new data insights when needed. In other words, machines on the edge can learn and adjust based on their own experience, independent of the larger network.
Edge computing solves the problem of network accessibility and latency. Now devices can be placed in areas where a network connection is bad or nonexistent without it reflecting on the results of the analysis. Furthermore, edge computing can offset some of the costs of usage and maintenance of cloud computing for data sharing.
For computer vision software, this means a possibility to respond even better in real time, and only move relevant insights to the cloud for further analysis. This feature is especially useful for autonomous cars.
In order to operate safely, the vehicles will need to gather and analyze vast amounts of data pertaining to their surroundings, directions, and weather conditions, not to mention communicating with other vehicles on the road, all without latency. Replying on a cloud solution to analyze the data can be dangerous as latency can lead to accidents.
Object recognition with point cloud
A technology that has been used more frequently lately in object recognition and object tracking is point cloud. Simply put, a point cloud is a collection of data points defined within a three-dimensional coordinate system.
This technology is typically used within a space (for example a room or a container) where the location and shape of each object are represented by a list of coordinates (X, Y, and Z). The list of coordinates is referred to as a “point cloud”.
This technology provides an accurate representation of where an object is in the space, and any movement can be accurately tracked.

Applications of the point cloud are endless. Here are just some examples of industries and the benefits they reap from this technology:
- Documentation: monitoring of assets, tracking construction sites, vandalism detection.
- Classification: urban planning, auditing tools for easier analysis, mapping of necessary utility work
- Change detection: asset management, tracking of goods, natural disaster management.
- Predictive maintenance: constant monitoring of assets and infrastructure to predict when repairs are needed.
Merged Reality: VR and AR enhanced
Today, any VR or AR system creates an immersive 3D environment, but it has little to do with the real one the user is located in. Most AR devices can perform simple scans of the environment (Google ARCore can, for example, detect flat surfaces and changes in light conditions), and VR systems can detect the movements of the user through head tracking, controllers, etc., but their abilities stop there.
Computer vision software is pushing VR and AR into the next stage of development that some call Merged Reality (MR).
With the help of external cameras and sensors that map the environment, as well as eye-tracking solutions and gyroscopes to position the user, the VR and AR systems are able to:
- Perceive the environment and guide the user away from obstacles such as walls, items or other users.
- Detect eye and body movement of the user and adopt the VR environment accordingly.
- Provide guidance and directions in indoor environments, public spaces, underground and more.
Hardware store Lowe’s is already using this in their store. Each shopper can borrow an AR device on which they can make their shopping list and get directions to each item in the store. The AR device uses floor plans, stock information and mapping of the environment in real-time to give accurate directions.
Sephora has updated their Virtual Artist app with a live 3D facial recognition that allows customers to see how different makeup products look on their faces and in different light conditions.
Semantic Instance segmentation
To understand what semantic instance segmentation is, let’s first break this concept into two parts: semantic segmentation and instance segmentation.
Instance segmentation identifies object outlines at the pixel level, while semantic segmentation simply groups pixels to a specific object group. Let’s use an image of balloons to illustrate the two techniques compared to other techniques.

- Classification: There is a balloon in this image.
- Semantic Segmentation: These are all the balloon pixels.
- Object Detection: There are 7 balloons in this image at these locations. We’re starting to account for objects that overlap.
- Instance Segmentation: There are 7 balloons at these locations, and these are the pixels that belong to each one.
If put together, semantic and instance segmentation methods become a powerful tool. Not only can this tool detect all pixels belonging to objects in the picture, but it can also determine what pixels belong to which object and where in the picture the objects are located.
Semantic instance segmentation is a useful tool for land cover classification, which has various applications. Land mapping via satellite imagery can be useful for governmental institutions to monitor deforestation (especially illegal), urbanization, traffic, and more.
Many architect firms are also using such data for city planning and building development. Some are even taking it a step further and combining it with AR equipment to get a sense of how their designs will look like in real life.
Bio: Valeryia Shchutskaya is the Marketing Manager at InData Labs - a professional services firm delivering AI-powered software and technical solutions to companies who want to leverage data and machine learning algorithms for business value.
Original. Reposted with permission.
Related:
- Building Surveillance System Using USB Camera and Wireless-Connected Raspberry Pi
- Basic Image Data Analysis Using Python – Part 4
- How to win Kaggle competition based on NLP task, if you are not an NLP expert