Explainable Artificial Intelligence
We outline the necessity of explainable AI, discuss some of the methods in academia, take a look at explainability vs accuracy, investigate use cases, and more.
By Preet Gandhi, NYU
Introduction
In the era of data science, artificial intelligence is making impossible feats possible. Driverless cars, IBM Watson’s question-answering system, cancer detection, electronic trading, etc. are all made possible through the advanced decision making ability of artificial intelligence. The deep layers of neural networks have a magical ability to recreate the human mind and its functionalities. When humans make decisions, they have the ability to explain their thought process behind it. They can explain the rationale; whether its driven by observation, intuition, experience or logical thinking ability. Basic ML algorithms like decision trees can be explained by following the tree path which led to the decision. But when it comes to complex AI algorithms, the deep layers are often incomprehensible by human intuition and are quite opaque. Data scientists may have trouble explaining why their algorithm gave a decision and the laymen end-user may not simply trust the machine’s predictions without contextual proof and reasoning.

Explainability is a multifaceted topic. It encompasses both individual models and the larger systems that incorporate them. It refers not only to whether the decisions a model outputs are interpretable, but also whether or not the whole process and intention surrounding the model can be properly accounted for. They try have an efficient trade-off between accuracy and explainability along with a great human-computer interface which can help translate the model to understandable representation for the end users.
There need to be three steps which should be fulfilled by the system :
1) Explained the intent behind how the system affects the concerned parties
2) Explain the data sources you use and how you audit outcomes
3) Explain how inputs in a model lead to outputs.
The necessity
Explainability is motivated due to lacking transparency of the black-box approaches, which do not foster trust and acceptance of AI generally and ML specifically. Rising legal and privacy aspects, e.g. with the new European General Data Protection Regulations will make black-box approaches difficult to use in Business, because they often are not able to explain why a machine decision has been made.
IBM Watson shook the world when it won jeopardy beating the best human players. But when it was marketed to hospitals to help the oncology department detect cancer, it failed miserably. Cancer detection is a very difficult and serious topic. The doctors as well as the patients were unable to trust the machine at each stage of consulting and treatment as Watson wouldn’t provide the reasons for its results. Moreover when its results agreed with the doctor’s, it couldn't provide a diagnosis.
Using AI for military practices is a hotly debated topic. Proponents claim that lethal autonomous weapon systems (LAWS) might cause less collateral damage but despite there being large training data to distinguish between combatants and civilians or targets and non-targets, it is very risky to leave the final decision making power to machines. CIA has 137 AI projects, one of which is the automated AI-enabled drones where the lack of explainability of the AI software’s selection of the targets is controversial. The extent of an explanation currently may be, “There is a 95 percent chance this is what you should do,” but that’s it. When the algorithm can't describe it’s features that contributed towards identifying a legitimate target, it leaves room open for debate on racism and stereotype issues which bias the model. Moreover in case of a false target, explanations would help diagnose the cause of failure and help improve the model.
New methods in academia
There are two main set of techniques used to develop explainable systems; post-hoc and ante-hoc. Ante-hoc techniques entail baking explainability into a model from the beginning. Post-hoc techniques allow models to be trained normally, with explainability only being incorporated at testing time.
Ante-Hoc Methods:
- Reversed Time Attention Model (RETAIN): Researchers at Georgia-Tech developed the RETAIN model to help doctors understand the AI software’s predictions. The patients hospital visits data were sent to two RNN’s both of which had attention mechanism. The attention mechanism helped explain which part the neural network was focusing on and which features helped influence its choice.

- Bayesian deep learning (BDL): BDL enables one to gauge how uncertain a neural network is about its predictions. These deep architectures can model complex tasks by leveraging the hierarchical representation power of deep learning, while also being able to infer complex multi-modal posterior distributions. Bayesian deep learning models typically form uncertainty estimates by either placing distributions over model weights, or by learning a direct mapping to probabilistic outputs. By knowing the weight distributions of various predictions and classes, we can tell a lot about what feature led to what decisions and the relative important of it.

Post-Hoc Methods:
- Local Interpretable Model-Agnostic Explanations (LIME): This isn’t a purely transparent model as it provides the explanation after a decision has been made. Hence it can have wide range of applications as it isn’t customized to one domain unlike RETAIN. For example for an image classification problem using a CNN, we get the probability distribution over classes. Then we make small changes to input to see how it affects the distribution and collect the results. Then using a linear interpretable model, on the collected perturbation set, we can explain changed in the key features extracted with their weights telling us how prominent they are. It blacks out different parts of the original image and feeds the resulting “perturbed” images back through the model, checking to see which perturbations throw the algorithm off the furthest to derive reasoning behind the algorithms decisions. For example, for an image of a tree frog, LIME found that erasing parts of the frog’s face made it much harder for the model to identify the image, showing that much of the original classification decision was based on the frog’s face. LIME is generally applicable to image classifications tasks.
In 2015, a black software developer reported that Google Photos labeled images of him and his black friend as “gorillas.” It’s not hard to see how explanation techniques like LIME could mitigate this kind of bias by having a human operator override the decisions upon evaluating the reasons given by the algorithm.
- Layer-wise Relevance Propagation (LRP): This approach is based on the principles of redistribution and conservation. Here when we have an image and probability distribution of classes, we redistribute these to the input pixels, layer by layer. We can decide the relevance of inputs and features by going backwards using Deep CNN to extract relevant features before identifying similarity between the images in feature space. We try to infer pixel-level details of the images that may have significantly informed the model’s choice.
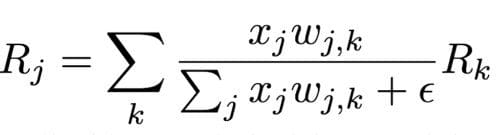
x_j — the activation value for neuron j in layer l
w_j,k — the weighing of the connection between neuron j in layer l and neuron k in layer l + 1
R_j — Relevance scores for each neuron in layer l
R_k — Relevance scores for each neuron in layer l+1
- BETA : BETA is closely connected to Interpretable Decision Sets. BETA learns a compact two-level decision set in which each rule explains part of the model behavior unambiguously. It uses a objective function so that the learning process is optimized for high fidelity (high agreement between explanation and the model), low unambiguity (little overlaps between decision rules in the explanation), and high interpretability (the explanation decision set is lightweight and small). These aspects are combined into one objection function to optimize for.
Explainability vs Accuracy
Will we need to ‘dumb down’ AI algorithms to make them explainable? Explainable models are easily understandable but don’t work very well as they are simple. Accurate models work well but aren’t explainable as they are complicated. The main issue with explainable AI is whether it can accurately fulfill the task it was designed for. The tradeoff decision to be made should depend on the application field of the algorithm and the end-user to whom its accountable.
When dealing with technical users who are acquainted with the field and have high trust level, especially tech companies or researchers, having highly accurate models would be preferred over high explainability as performance is very important. But dealing with laymen users is a different scenario. It would be difficult to garner their trust. The machine learning approach is very different specially in banks, insurance companies, healthcare providers and other regulated industries. The reason is mainly that they are prone to legal or even ethical requirements which tend to limit more and more the use of black box models. Such institutions are answerable for their decisions and process and in this case a simple explainable albeit less efficient algorithm would do.
Hence the tradeoff should be decided according to the application domain and the users concerned. If you want your system to be explainable, you’re going to have to make do with a simpler system that isn’t as powerful or accurate. Simple systems can give a prediction to the user but the ultimate action should be taken by the user. When performance matters most, even with a complicated model, opt for the trust that comes from making sure that you’re able to verify that your system does, in fact, work.

Use Case : DARPA XAI
The Department of Defense (DoD) is increasingly investing in AI research in collaboration with technological giants like Google to have artificial intelligence programs for military activities. Due to ethical reasons, many government departments agree to have a “man in the loop” to control any lethal system of these “killer robots”. Due to the increasing debates and strikes by the AI community to not contribute towards military AI, the DARPA division is pushing towards their $2 Billion Explainable Artificial Intelligence ( XAI ) program. XAI is their hope to usher in the third-wave AI systems which can understand the context in which they function and can characterize the real world phenomena. Its main aim is to:
- Explain the decisions and it’s process
- Understand it’s strength and weakness
- Convey how the system may behave in the future

- Offer insight on how to correct the mistakes
The final goal of XAI is to have a toolkit library of ML and HCI modules for more understandable AI implementations. The Phase 1 of the project was completed in May 2018 and further advancements are expected in the coming years. In case of a gray area in decision output, XAI aims to give the analyst reasons for red flags upon which the analyst can act to make a decision using human input.
Conclusion
The success of AI models is due to the machines’ own internal representations which are even more complicated then manually generated features leading to its inexplicable nature. There are a lot of on-going research on the ante-hoc and post-hoc methods to make the AI more answerable and awareness to inculcate these methods in existing programs. Good initiatives by leading institutions like DARPA, Google, DeepMind, etc. are leading the necessary change. Despite this, there will always be a tradeoff between explainability and accuracy whose balance depends on various factors like end-user, legal liability, technicality of the concerned parties and the field of application. Artificial intelligence should not become a powerful deity which we follow blindly without understanding its reasoning but we shouldn’t forget about its beneficial insight it can have. Ideally, we should build flexible and interpretable models that can work in collaboration with experts and their domain knowledge.
References
- LRP - https://arxiv.org/pdf/1807.06160.pdf
- DARPA XAI - https://www.darpa.mil/attachments/XAIProgramUpdate.pdf
- XAI methods - https://medium.freecodecamp.org/an-introduction-to-explainable-ai-and-why-we-need-it-a326417dd000
Bio: Preet Gandhi is a student at NYU and was a Data Science Intern at Apple Inc.
Resources:
- On-line and web-based: Analytics, Data Mining, Data Science, Machine Learning education
- Software for Analytics, Data Science, Data Mining, and Machine Learning
Related: