Data-science? Agile? Cycles? My method for managing data-science projects in the Hi-tech industry.
The following is a method I developed, which is based on my personal experience managing a data-science-research team and was tested with multiple projects. In the next sections, I’ll review the different types of research from a time point-of-view, compare development and research workflow approaches and finally suggest my work methodology.
By Ori Cohen, Data Science Lead at Zencity.io

The Austrian Alps
Agile software development has taken over the hi-tech industry. Whether implemented as Scrum, Kanban or Scrumban, these methods were created in order to be flexible and allow quick changes by working in short cycles. While these implementations are well suited for development, they collide in certain aspects with research, therefore in order to be agile in research, we need to adapt the core values of Agile and reconcile them with research methodologies, I.e., create a working implementation that uses Agile values and ideas but is oriented toward research. The following is a method I developed, which is based on my personal experience managing a data-science-research team and was tested with multiple projects. In the next sections, I’ll review the different types of research from a time point-of-view, compare development and research workflow approaches and finally suggest my work methodology.
Types of research
We usually encounter three types of research:
- Long-term, in academia and companies such as IBM or FACEBOOK, i.e., research that advances science or technology.
- Medium-term, i.e., strategic projects that will contribute to your company in the near future.
- Short-term projects, i.e., features for your company’s product, client-projects, internal projects such as reusable APIs or POCs.
Short or medium-term projects, in my opinion, apply to any project with some affinity to academia or a company-related project that aims to create a novel algorithm or implements a new feature but with industry constraints such as time, resources or money. In contrast, long-term research in the industry is usually the most feared by (although there are exceptions). For example, in many interviews, as a PhD graduate, I was asked if I could work in a fast-paced startup-mentality company and deliver results on a short-term basis.
Major differences between development and research
Let’s compare the development workflow for both fields.
Programming: In software development, you organize the code into functions, classes (i.e., object-oriented-programming), and may use design-patterns etc. You try to design a generic architecture that is clear, reusable and that can be easily maintained in the future. In research, the process can be compared to a prototyping stage where we need a lot of flexibility, this allows us to try many ideas as fast as possible. For me and others, this boils down to using “Notebooks” — an interactive python environment that allows you to prototype faster than traditional IDEs, by compartmentalizing certain code blocks and keeping persistent memory. We don’t have to reload huge variables or recalculate algorithms if there is no need, we can continue working from a previous stage. programming in notebooks can be compared to using a big ‘main’ divided into several cells, each cell acting as a function. Traditional programming IDEs are also incompatible with persistent memory, imagine trying to read a huge dataset while trying to debug a certain algorithm.
Debugging: The debugging process has well-established tools and you can easily step from line to line, in functions and classes. In traditional IDEs, you are forced to reload your dataset and waste valuable time as many times as you restart your debugging process, in notebooks the dataset is persistent and is kept in memory for the entire duration (as long as the kernel is not reset). In a notebook, the debug process consists of using print()’s, therefore, the debugging stage is really quite simplistic. Eventually, when the algorithm is finished, we restructure it using traditional software development tools such as PyCharm using OOP, Design-patterns and finally we write input-output tests.
Time and schedule management: In common implementations of Agile, each project is broken down into many small deliverable tasks that are given a short-time estimation. deliverables are grouped into cycles. These small tasks are pulled by team members until completion, trying to finish all tasks until the cycle ends. The cycle is reset every X weeks. In general, research tasks are longer and they don’t always correspond well with short cycle methodology. For example, when we kick-start a model, it may take a few weeks to get the coveted accuracy metric. However, this doesn’t mean that we don’t see measurable results during those weeks in other ways, i.e., a correlation between features to a target variable etc.
Now that we have talked about some of the major differences between software development and research, let’s talk about my agile research management method and see how I try to solve these issues.
My Research Management Methodology
In research, we look at the product demands, assign features, think of possible algorithmic solutions, define goals and KPIs. The truth is that we don’t have a crystal-clear path toward that goal, in other words, we don’t know what the exact road to completion in terms of tasks is. Algorithmic development is not merely production, it is much more about understanding the problem, assessing options, validation, etc. In practice, we test many different hypotheses and ideas, based on intuition and experience, some may help, others may not.
We first decide on a sensible deadline for a project, whether two-weeks, a month or more, basically as much time as you think it should take based on your experience or guesstimate. Deadlines between different projects are not aligned, therefore hard to place in rigid cycles. It’s important to keep in mind that these deadlines can change, projects may be extended or end earlier than we anticipated.
I break down every project into six basic stages (Figure 1.), which allows me to group sub-tasks based on context. The six basic stages, which are listed below can be seen in Figure 1 as a Jira board.

Figure 1: the six stages of an applied-research or data-science project
Project Stages:
1. Literature review
2. Data exploration
3. Algorithm development
4. Result analysis
5. Review
6. Deployment
Using the stages method, a project can go back and forth between stages until completion (blue and green arrows in Figure 2). For example, we finished writing our algorithm and in the ‘result-analysis’ stage we find out that we need to go back and change a core feature engineering idea, the project will move back to ‘data-exploration’ and undergo the algorithm and result-analysis stages once again.

Figure2: the six stages of an applied-research or data-science project overlaid on a Jira board. Showcasing the main idea that a project can move to a different stage, either forward or backwards.
In each stage, I create as many ideas, hypotheses or tasks, i.e. deliverables. For example, in the ‘literature review’ stage you could have several tasks such as looking for papers on Google Scholar, searching Github.com or trying to find related posts on Medium.com. In the ‘data exploration’ stage you could possibly explore feature engineering, selection or all the embedding methods available today, from word2vec, phrase2vec, sent2vec to Elmo, Bert, etc. In the ‘algorithm’ stage we can test several classic machine-learning algorithms, try some neural net ideas (CNN, LSTM, BI-GRU, multi-input networks), stacking algorithms, ensembles, etc. In the ‘result analysis’ stage, we can explore many metrics such as accuracy, F1, explore the correctness of the model by looking at the content, etc. In the ‘review’ stage, a team member reviews our algorithm. Finally in the ‘deployment stage’, we convert our notebooks into a clear class-based API, exposing init(), train(), predict(), upload_model() and download_model() to the DevOps team, create unit testsand finish with a Pip package (we are using circleCI and Gemfury).
I do not assign estimations on each deliverable as this adds planning overhead, installs a rigid work-plan that I want to avoid and disrupts creativity in the research process, i.e., we don’t want the work-plan to manage us, we want to manage the work-plan. I want my team to explore different solutions that appear and are thought of during the creative process and not stick a predetermined plan that is basically just a wish-list. In other words, data, results, and insights from the process yields many brilliant ideas that will allow my team to solve novel business problems.
Ultimately, we explore many ideas that may lead us to our goal, however, it is not mandatory to finish all tasks in each stage, in other words, if we are satisfied with our current stage, we can advance to the next stage without completing all other tasks. On the other hand, if you aren’t satisfied with the current plan, you can change it, skip ahead or go back.
As a small-team manager, I do not want the overhead that comes with sub-task management. To manage these subtasks I use the ‘smart-checklist’ pluginfor Jira, as seen in Figure 3. The list of tasks is contained within each project box, the appropriate task can be tagged for ‘completion’ or ‘in progress’ in the UI, obviously, you only work on the subtask list in the stage that the project box resides in. As your team grows, you may have a dedicated person whose job is to maintain every sub-task in extreme detail and you may feel the need to use Jira’s built-in sub-task management which adds some overhead to subtask management. I Personally feel that the majority of our sub-tasks do not need to be tracked in full and the board view should be as clean and grouped as possible.
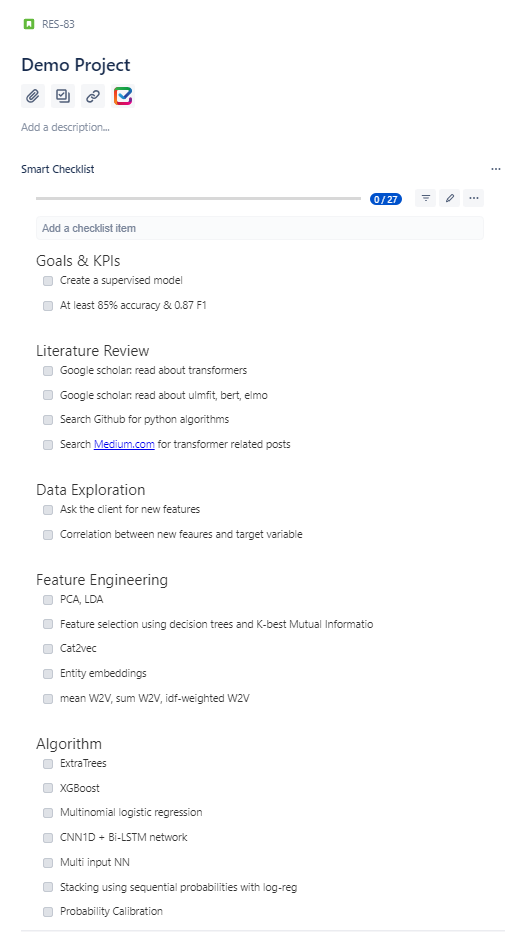
Figure 3: an example project with tasks in each one of the primary stages.
Research Daily
Project management doesn’t end with a management board, a daily meeting is also a very important aspect of project management. My team has a one-hour daily meeting, usually in the morning and similarly to development we try to brainstorm, synchronize, talk about what we did yesterday, discuss issues that we are stuck at and talk about the next steps. Due to the relatively longer nature of our talks, I found that a sit-down daily is more appropriate, in contrast to a stand-up daily, i.e., it’s much more beneficial to be comfortable on a couch and talk about fine algorithmic details. This allows us to share ideas, be creative and constantly improve without waiting for feedback at the end of a cycle.
Research Workflow:
The following represents an overview of my research workflow methodology
- Exchange cycle-methodology with sensible-per-project-deadlines that fit your project’s expectations, goals and KPIs.
- Acknowledge that a project exists in several stages throughout its lifespan.
- Acknowledge that a project can temporarily return to a previous stage in order to try additional ideas.
- Break down each project into stage-based deliverables.
- Assign a soft-deadline for each stage.
- Acknowledge that your list of deliverables does not need to be completed as a whole, deliverables can be added throughout the project, which influences deadlines.
- At each stage, choose the best deliverables to be completed first, when satisfied, move to the next stage in the research.
- Wash rinse repeat.
Version Development
Let’s have a brief discussion about algorithm development versions. I usually try to reach the project goals and KPIs, but a good-enough algorithm is always better than nothing. therefore, it is advisable to create a minimum-viable-product (MVP), finish the process, get it in production and then decide what are the future goals for the next version, these can come from your product-department, result-analysis stage or from your unfinished work plan, as seen in Figure 4.
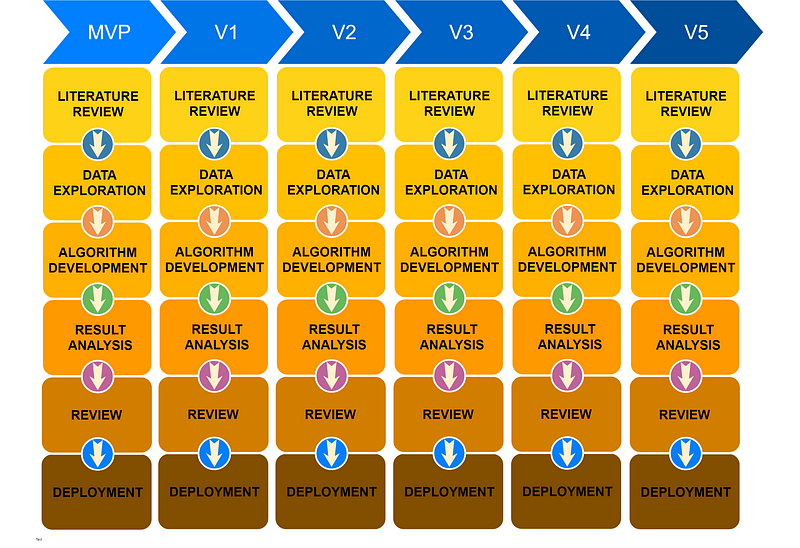
Figure 4: a flow-chart representing version development while utilizing the research-stage-methodology workflow.
Hopefully, You can adapt or use some of the ideas mentioned here for managing data-science-research projects. Keep in mind that for this methodology to work, your company must understand that research is an uncertain process, some results can’t be guaranteed, but with the right project management methodology, the process can be successfully controlled in order to achieve our goals. Finally, if you are interested in project workflows from product design until model completion and maintenance, Shay Palachy wrote an excellent post.
I would like to thank (in alphabetical order) to Alon Nisser, Guy Nesher, Ido Ivri, Kobi Hikri, Moshe Hadad, Netanel Davidovitz, Samuel Jefroykin, Simon Reisman for their invaluable insight into Agile methodology, critique, proof-reading and comments.
Bio: Ori Cohen has a PhD in Computer science with focus in machine-learning. He leads the data-science team in Zencity.io, trying to positively influence citizen lives.
Original. Reposted with permission.
Related:
- Data Science Project Flow for Startups
- Getting Real World Results From Agile Data Science Teams
- Turbo Charge Agile Processes with Deep Learning