Hosting Language Models on a Budget
Learn how to run your own language model for free using lightweight models and Hugging Face Spaces.

Image by Editor
# Introduction
ChatGPT, Claude, Gemini. You know the names. But here's a question: what if you ran your own model instead? It sounds ambitious. It's not. You can deploy a working large language model (LLM) in under 10 minutes without spending a dollar.
This article breaks it down. First, we'll figure out what you actually need. Then we'll look at real costs. Finally, we'll deploy TinyLlama on Hugging Face for free.
Before you launch your model, you probably have a lot of questions on your mind. For instance, what tasks am I expecting my model to perform?
Let’s try answering this question. If you need a bot for 50 users, you don’t need GPT-5. Or if you are planning to do sentiment analysis on 1,200+ tweets a day, you may not need a model with 50 billion parameters.
Let’s first look at some popular use cases and the models that can perform those tasks.
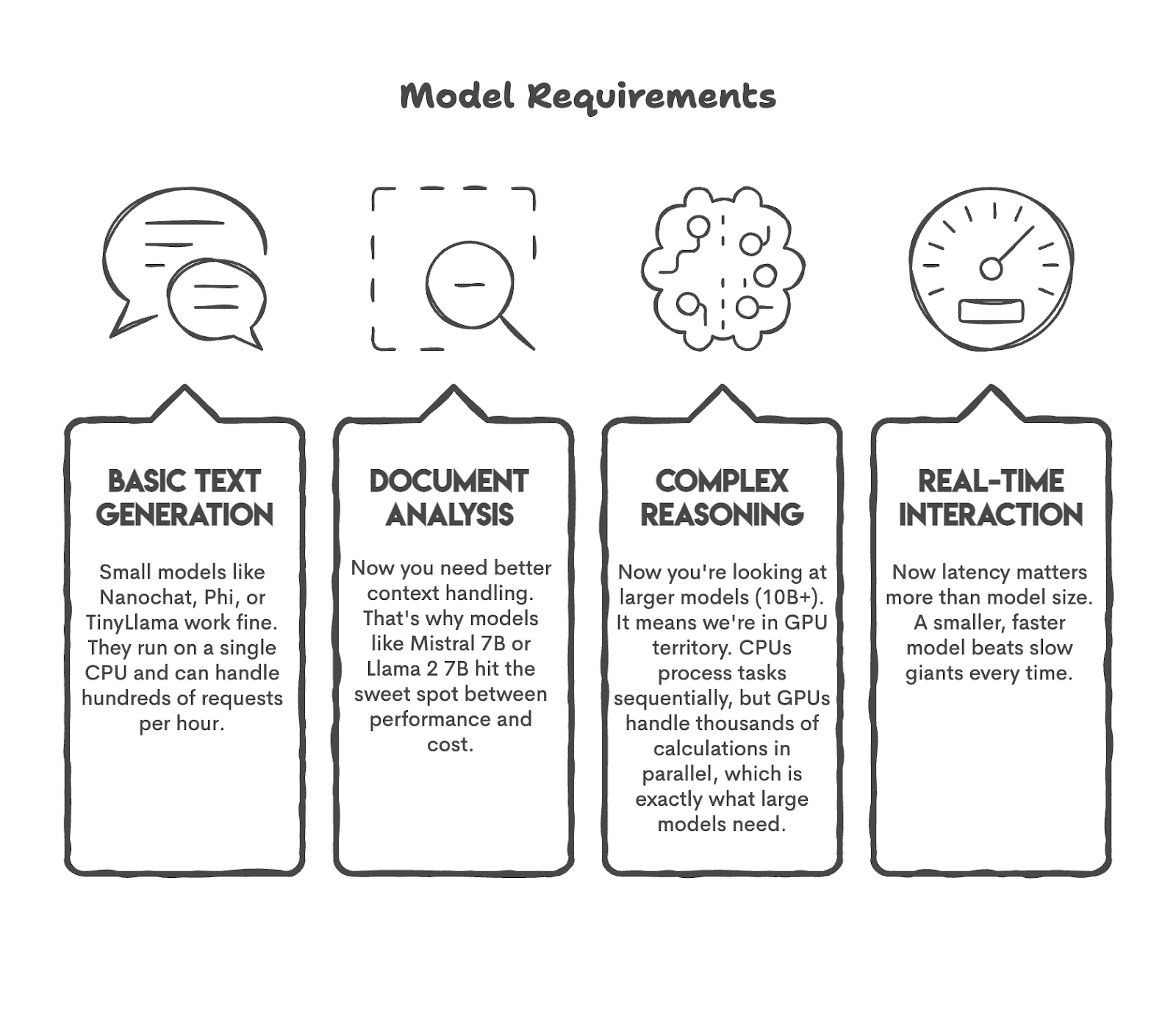
As you can see, we matched the model to the task. This is what you should do before beginning.
# Breaking Down the Real Costs of Hosting an LLM
Now that you know what you need, let me show you how much it costs. Hosting a model is not just about the model; it is also about where this model runs, how frequently it runs, and how many people interact with it. Let’s decode the actual costs.
// Compute: The Largest Cost You’ll Face
If you run a Central Processing Unit (CPU) 24/7 on Amazon Web Services (AWS) EC2, that would cost around \$36 per month. However, if you run a Graphics Processing Unit (GPU) instance, it would cost around $380 per month — more than 10x the cost. So be careful about calculating the cost of your large language model, because this is the main expense.
(Calculations are approximate; to see the real price, please check here: AWS EC2 Pricing).
// Storage: Small Cost Unless Your Model Is Massive
Let’s roughly calculate the disk space. A 7B (7 billion parameter) model takes around 14 Gigabytes (GB). Cloud storage expenses are around \$0.023 per GB per month. So the difference between a 1GB model and a 14GB model is just roughly \$0.30 per month. Storage costs can be negligible if you don't plan to host a 300B parameter model.
// Bandwidth: Cheap Until You Scale Up
Bandwidth is important when your data moves, and when others use your model, your data moves. AWS charges \$0.09 per GB after the first GB, so you are looking at pennies. But if you scale to millions of requests, you should calculate this intently too.
(Calculations are approximate; to see the real price, please check here: AWS Data Transfer Pricing).
// Free Hosting Options You Can Use Today
Hugging Face Spaces lets you host small models for free with CPU. Render and Railway offer free tiers that work for low-traffic demos. If you're experimenting or building a proof-of-concept, you can get pretty far without spending a cent.
# Pick a Model You Can Actually Run
Now we know the costs, but which model should you run? Each model has its advantages and disadvantages, of course. For instance, if you download a 100-billion-parameter model to your laptop, I guarantee it won't work unless you have a top-notch, specifically built workstation.
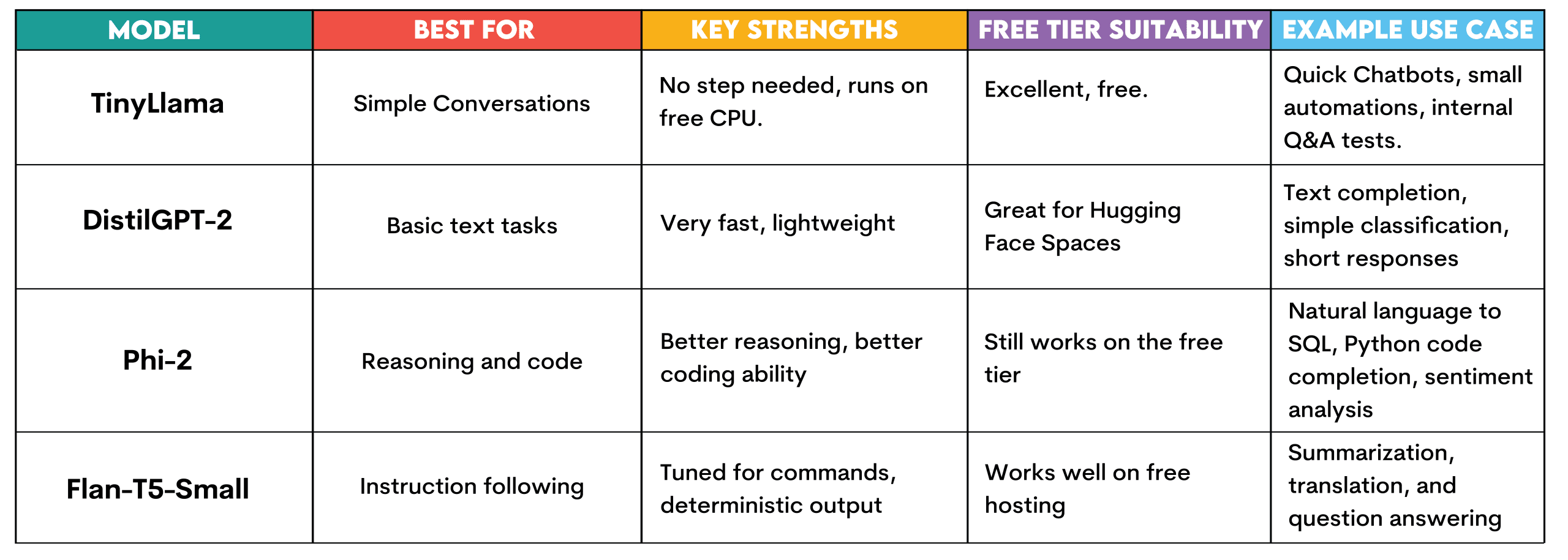
Let’s see the different models available on Hugging Face so you can run them for free, as we are about to do in the next section.
TinyLlama: This model requires no setup and runs using the free CPU tier on Hugging Face. It is designed for simple conversational tasks, answering simple questions, and text generation.
It can be used to build quickly and test chatbots, run quick automation experiments, or create internal question-answering systems for testing before expanding into an infrastructure investment.
DistilGPT-2: It's also swift and lightweight. This makes it perfect for Hugging Face Spaces. Okay for completing text, very simple classification tasks, or short responses. Suitable for understanding how LLMs function without resource constraints.
Phi-2: A small model developed by Microsoft that proves quite effective. It still runs on the free tier from Hugging Face but offers improved reasoning and code generation. Employ it for natural language-to-SQL query generation, simple Python code completion, or customer review sentiment analysis.
Flan-T5-Small: This is the instruction-tuning model from Google. Created to respond to commands and provide answers. Useful for generation when you want deterministic outputs on free hosting, such as summarization, translation, or question-answering.
# Deploy TinyLlama in 5 Minutes
Let’s build and deploy TinyLlama by using Hugging Face Spaces for free. No credit card, no AWS account, no Docker headaches. Just a working chatbot you can share with a link.
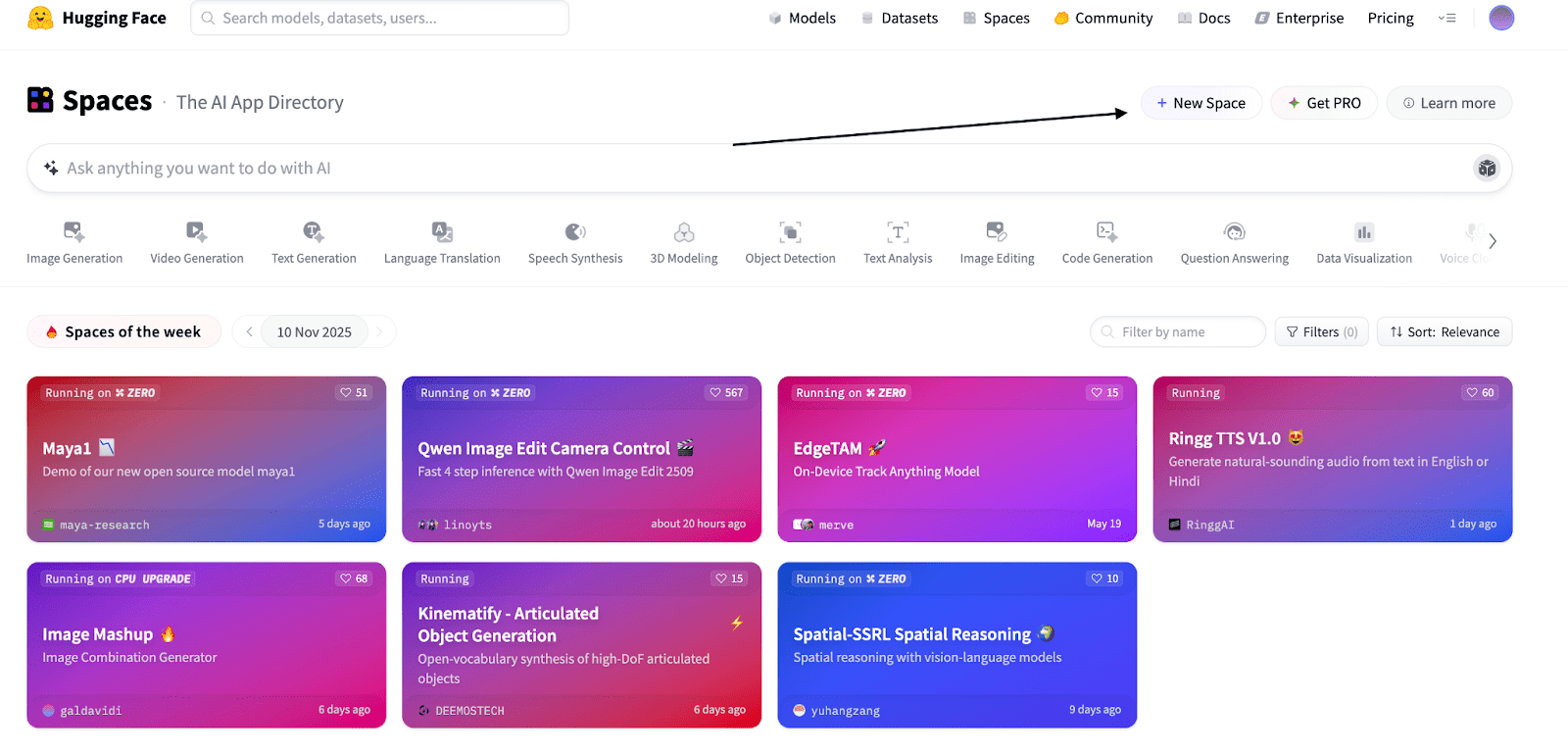
// Step 1: Go to Hugging Face Spaces
Head to huggingface.co/spaces and click "New Space", like in the screenshot below.
Name the space whatever you want and add a short description.
You can leave the other settings as they are.
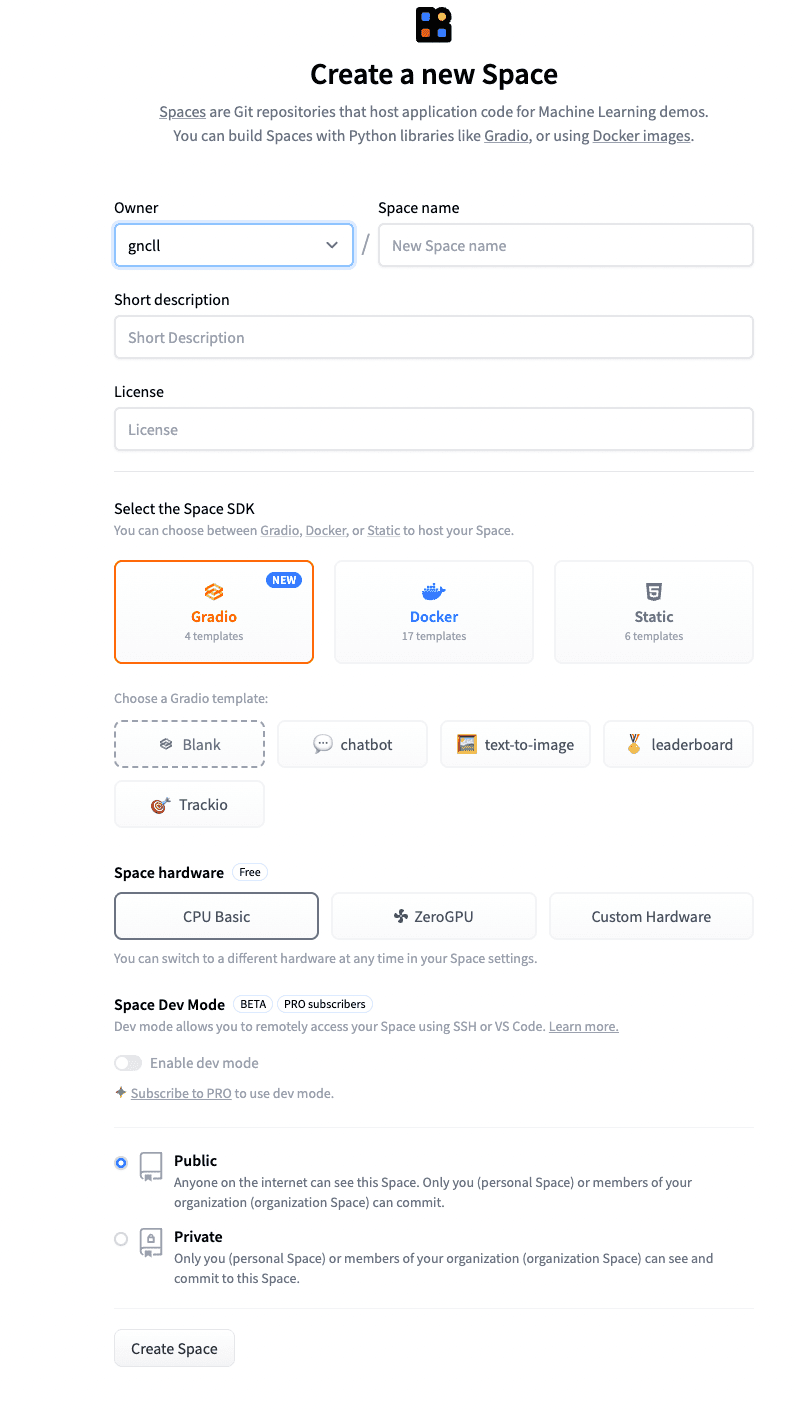
Click “Create Space”.
// Step 2: Write the app.py
Now, click on “create the app.py” from the screen below.
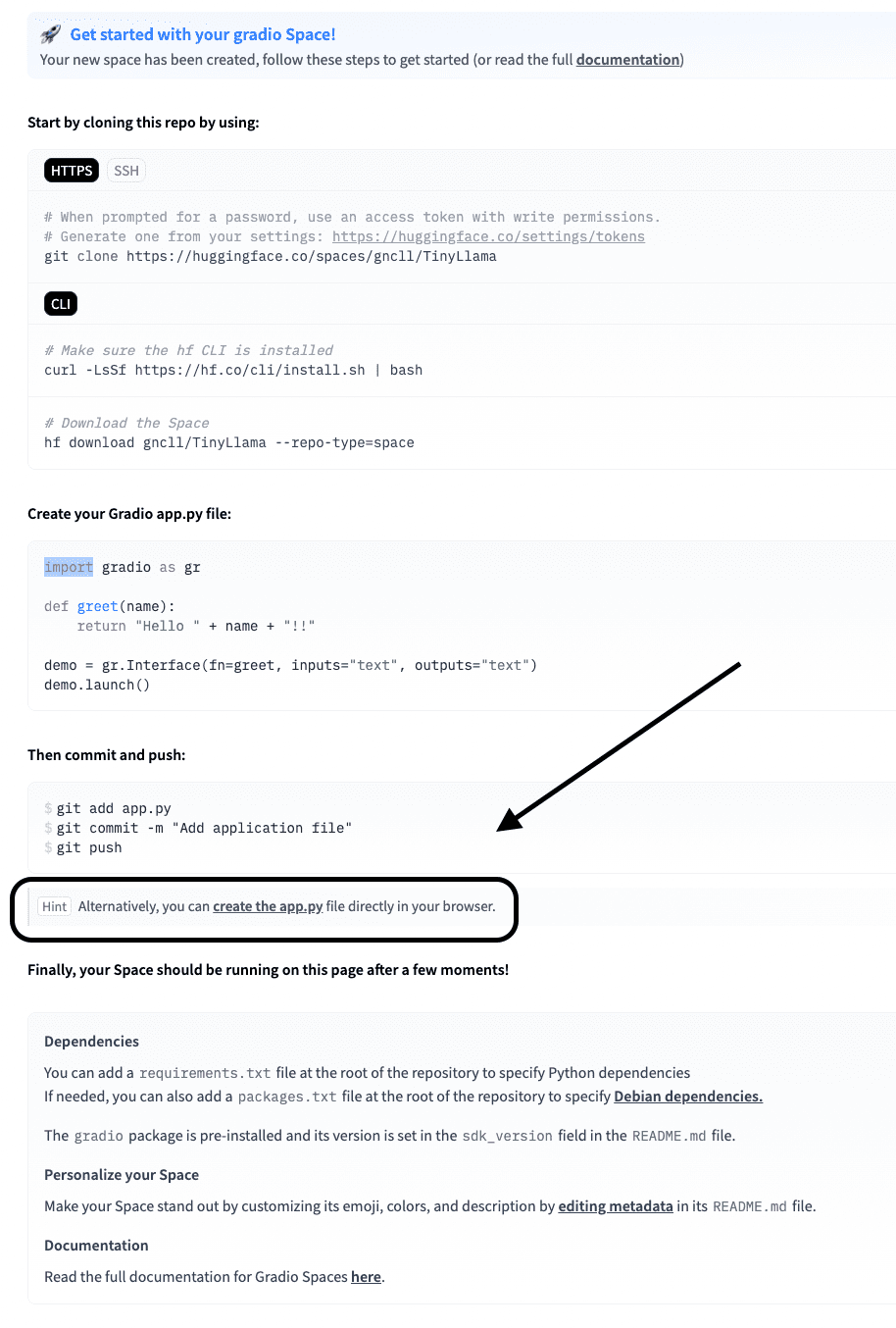
Paste the code below inside this app.py.
This code loads TinyLlama (with the build files available at Hugging Face), wraps it in a chat function, and uses Gradio to create a web interface. The chat() method formats your message correctly, generates a response (up to a maximum of 100 tokens), and returns only the reply from the model (it does not include repeats) to the question you asked.
Here is the page where you can learn how to write code for any Hugging Face model.
Let's see the code.
import gradio as gr
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "TinyLlama/TinyLlama-1.1B-Chat-v1.0"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
def chat(message, history):
# Prepare the prompt in Chat format
prompt = f"<|user|>\n{message}\n<|assistant|>\n"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(
**inputs,
max_new_tokens=100,
temperature=0.7,
do_sample=True,
pad_token_id=tokenizer.eos_token_id
)
response = tokenizer.decode(outputs[0][inputs['input_ids'].shape[1]:], skip_special_tokens=True)
return response
demo = gr.ChatInterface(chat)
demo.launch()
After pasting the code, click on “Commit the new file to main.” Please check the screenshot below as an example.
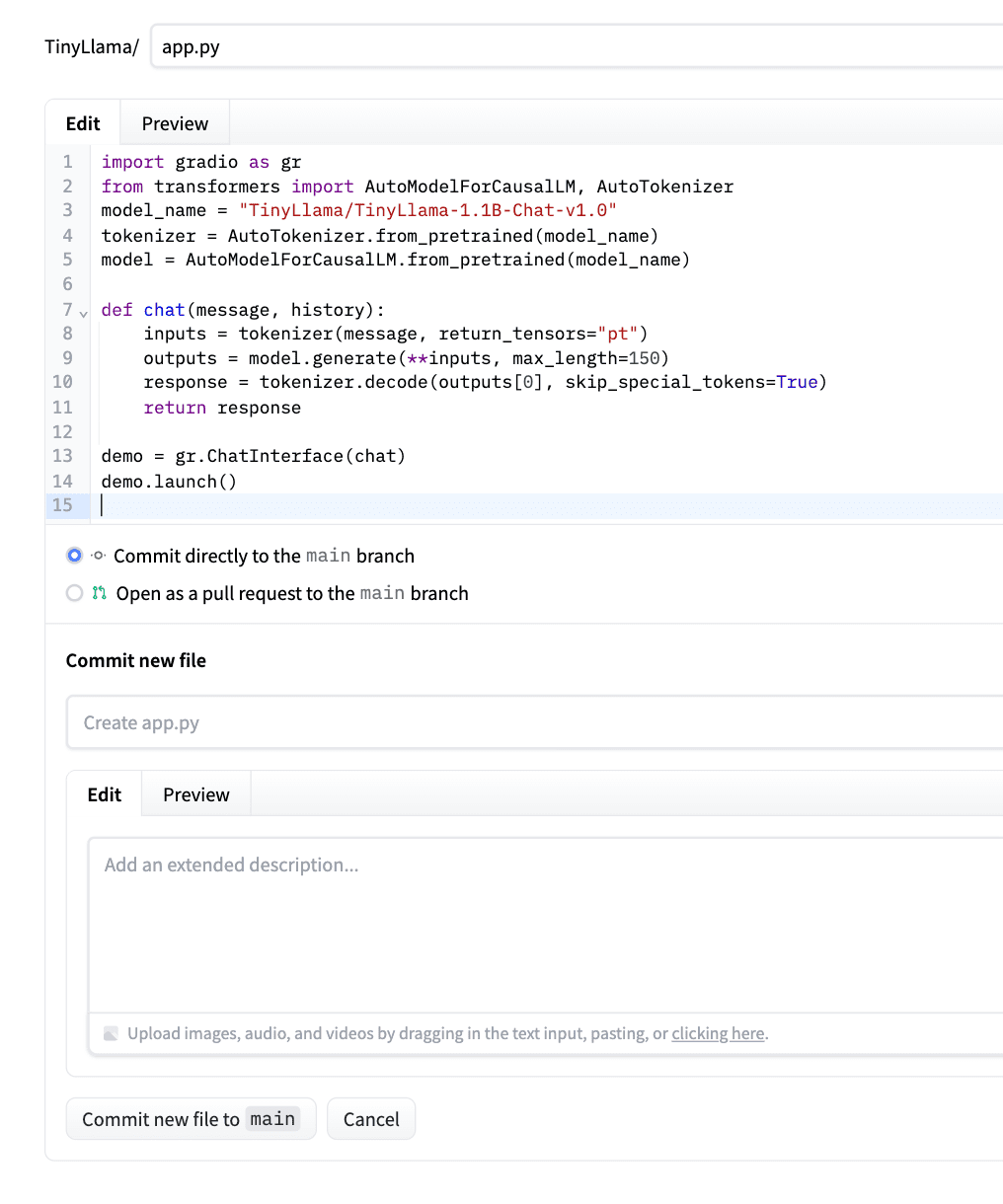
Hugging Face will automatically detect it, install dependencies, and deploy your app.

During that time, create a requirements.txt file or you’ll get an error like this.

// Step 3: Create the Requirements.txt
Click on “Files” in the upper right corner of the screen.

Here, click on “Create a new file,” like in the screenshot below.

Name the file “requirements.txt” and add 3 Python libraries, as shown in the following screenshot (transformers, torch, gradio).
Transformers here loads the model and deals with the tokenization. Torch runs the model since it provides the neural network engine. Gradio creates a simple web interface so users can chat with the model.

// Step 4: Run and Test Your Deployed Model
When you see the green light “Running”, that means you are done.

Now let’s test it.
You can test it by first clicking on the app from here.

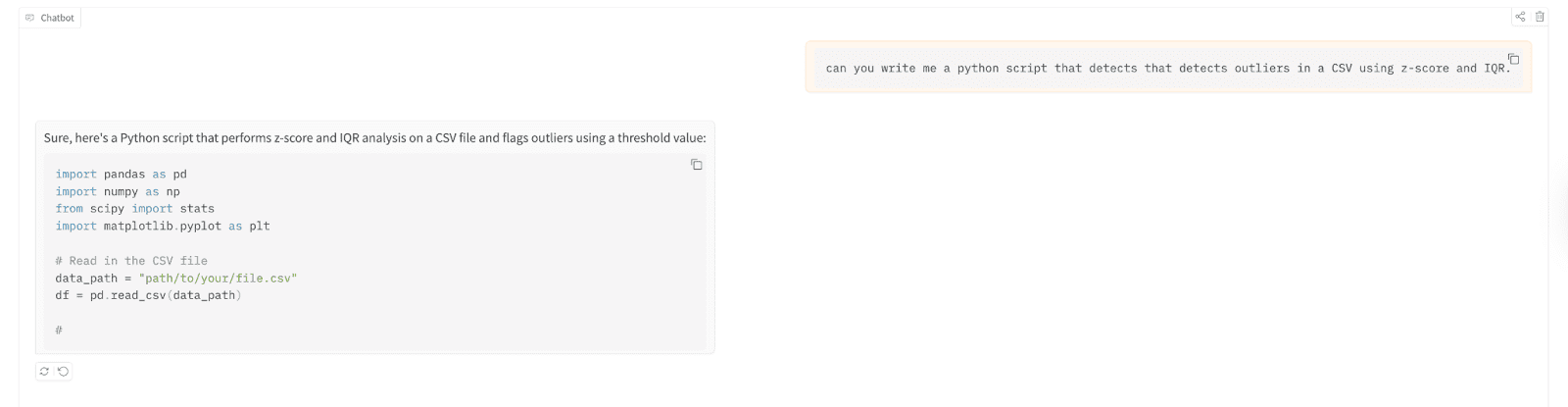
Let’s use it to write a Python script that detects outliers in a comma-separated values (CSV) file using z-score and Interquartile Range (IQR).
Here are the test results;
// Understanding the Deployment You Just Built
The result is that you are now able to spin up a 1B+ parameter language model and never have to touch a terminal, set up a server, or spend a dollar. Hugging Face takes care of hosting, the compute, and the scaling (to a degree). A paid tier is available for more traffic. But for the purposes of experimentation, this is ideal.
The best way to learn? Deploy first, optimize later.
# Where to Go Next: Improving and Expanding Your Model
Now you have a working chatbot. But TinyLlama is just the beginning. If you need better responses, try upgrading to Phi-2 or Mistral 7B using the same process. Just change the model name in app.py and add a bit more compute power.
For faster responses, look into quantization. You can also connect your model to a database, add memory to conversations, or fine-tune it on your own data, so the only limitation is your imagination.
Nate Rosidi is a data scientist and in product strategy. He's also an adjunct professor teaching analytics, and is the founder of StrataScratch, a platform helping data scientists prepare for their interviews with real interview questions from top companies. Nate writes on the latest trends in the career market, gives interview advice, shares data science projects, and covers everything SQL.