Fine-Tuning OpenAI Language Models with Noisily Labeled Data
Reduce LLM prediction error by 37% via data-centric AI.
By Chris Mauck, Jonas Mueller
This article demonstrates how data-centric AI tools can improve a fine-tuned Large Language Model (LLM; a.k.a. Foundation Model). These tools optimize the dataset itself rather than altering the model architecture/hyperparameters — running the exact same fine-tuning code on the improved dataset boosts test-set performance by 37% on a politeness classification task studied here. We achieve similar accuracy gains via the same data-centric AI process across 3 state-of-the-art LLM models one can fine-tune via the OpenAI API: Davinci, Ada, and Curie. These are variants of the base LLM underpinning GPT-3/ChatGPT.
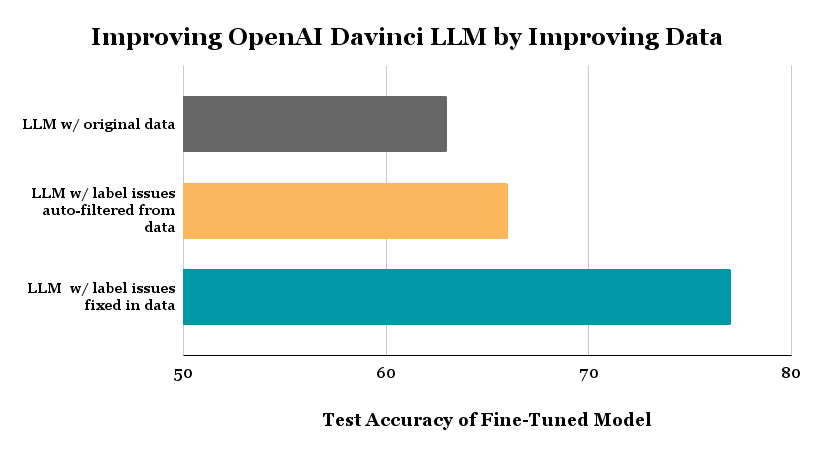
The above plot shows the test accuracy achieved for 3-class politeness classification of text by the same LLM fine-tuning code (fitting Davinci via OpenAI API) run on 3 different datasets: (1) the original dataset labeled by human annotators, (2) an auto-filtered version of this dataset in which we removed examples automatically estimated to be mislabeled via Confident Learning, (3) a cleaned version of the original data in which we manually fixed labels of examples estimated to be mislabeled (rather than filtering these examples).
Background
Labeled data powers AI/ML in the enterprise, but real-world datasets have been found to contain between 7-50% annotation errors. Imperfectly-labeled text data hampers the training (and evaluation of) ML models across tasks like intent recognition, entity recognition, and sequence generation. Although pretrained LLMs are equipped with a lot of world knowledge, their performance is adversely affected by noisy training data (as noted by OpenAI). Here we illustrate data-centric techniques to mitigate the effect of label noise without changing any code related to model architecture, hyperparameters, or training. These data quality improvement techniques should thus remain applicable even for future advanced LLMs like GPT-10.
Why Fine-tuning?
LLMs acquire powerful generative and discriminative capabilities after being pre-trained on most text across the internet. Nonetheless, ensuring the LLM produces reliable outputs for a particular business use-case often requires additional training on actual data from this domain labeled with the desired outputs. This domain-specific training is known as fine-tuning the LLM and can be done via APIs offered by OpenAI. Imperfections in the data annotation process inevitably introduce label errors in this domain-specific training data, posing a challenge for proper fine-tuning and evaluation of the LLM.
Why Data-Centric AI?
Here are quotes from OpenAI on their strategy for training state-of-the-art AI systems:
"Since training data shapes the capabilities of any learned model, data filtering is a powerful tool for limiting undesirable model capabilities.”
“We prioritized filtering out all of the bad data over leaving in all of the good data. This is because we can always fine-tune our model with more data later to teach it new things, but it’s much harder to make the model forget something that it has already learned.”
Clearly dataset quality is a vital consideration. Some organizations like OpenAI manually handle issues in their data to produce the very best models, but this is tons of work! Data-centric AI is an emerging science of algorithms to detect data issues, so you can systematically improve your dataset more easily with automation.
Our LLM in these experiments is the Davinci model from OpenAI, which is their most capable GPT-3 model, upon which ChatGPT is based.
Overview
Here we consider a 3-class variant of the Stanford Politeness Dataset, which has text phrases labeled as: impolite, neutral, or polite. Annotated by human raters, some of these labels are naturally low-quality.

This article walks through the following steps:
- Use the original data to fine-tune different state-of-the-art LLMs via the OpenAI API: Davinci, Ada, and Curie.
- Establish the baseline accuracy of each fine-tuned model on a test set with high-quality labels (established via consensus and high-agreement amongst many human annotators who rated each test example).
- Use Confident Learning algorithms to automatically identify hundreds of mislabeled examples.
- Remove the data with automatically-flagged label issues from the dataset, and then fine-tune the exact same LLMs on the auto-filtered dataset. This simple step reduces the error in Davinci model predictions by 8%!
- Introduce a no-code solution to efficiently fix the label errors in the dataset, and then fine-tune the exact same LLM on the fixed dataset. This reduces the error in Davinci model predictions by 37%!
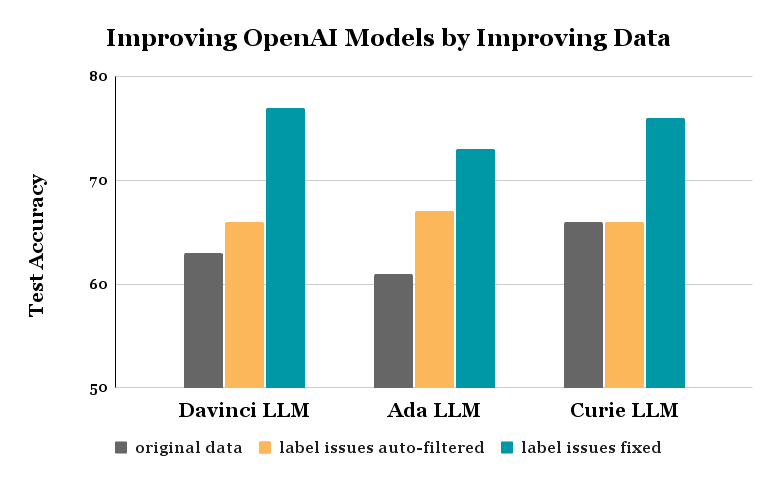
Similar gains are achieved via these same processes for the Ada and Curie models — in all cases, nothing was changed about the model nor the fine-tuning code!
Here’s a notebook you can run to reproduce the results demonstrated in this article and understand the code to implement each step.
Politeness Dataset
You can download the train and test sets here: train test
Our training dataset has 1916 examples each labeled by a single human annotator, and thus some may be unreliable. The test dataset has 480 examples each labeled by five annotators, and we use their consensus label as a high-quality approximation of the true politeness (measuring test accuracy against these consensus labels). To ensure a fair comparison, this test dataset remains fixed throughout our experiments (all label cleaning / dataset modification is only done in the training set). We reformat these CSV files into the jsonl file type required by OpenAI’s fine-tuning API.
Fine-tune and Evaluate LLM
Here’s how our code looks to fine-tune the Davinci LLM for 3-class classification and evaluate its test accuracy:
!openai api fine_tunes.create -t "train_prepared.jsonl" -v "test_prepared.jsonl" --compute_classification_metrics --classification_n_classes 3 -m davinci
--suffix "baseline"
>>> Created fine-tune: ft-9800F2gcVNzyMdTLKcMqAtJ5
Once the job completes, we query a fine_tunes.results endpoint to see the test accuracy achieved when fine-tuning this LLM on the original training dataset.
!openai api fine_tunes.results -i ft-9800F2gcVNzyMdTLKcMqAtJ5 > baseline.csv
df = pd.read_csv('baseline.csv')
baseline_acc = df.iloc[-1]['classification/accuracy']
>>> Fine-tuning Accuracy: 0.6312500238418579
Our baseline Davinci LLM achieves a test accuracy of 63% when fine-tuned on the raw training data with possibly noisy labels. Even a state-of-the-art LLM like the Davinci model produces lackluster results for this classification task, is it because the data labels are noisy?
Automatically Find Label Issues
Confident Learning is a recently developed suite of algorithms to estimate which data are mislabeled in a classification dataset. These algorithms require out-of-sample predicted class probabilities for all of our training examples and apply a novel form of calibration to determine when to trust the model over the given label in the data.
To obtain these predicted probabilities we:
- Use the OpenAI API to compute embeddings from the Davinci model for all of our training examples. You can download the embeddings here.
- Fit a logistic regression model on the embeddings and labels in the original data. We use 10-fold cross-validation which allows us to produce out-of-sample predicted class probabilities for every example in the training dataset.
# Get embeddings from OpenAI.
from openai.embeddings_utils import get_embedding
embedding_model = "text-similarity-davinci-001"
train["embedding"] = train.prompt.apply(lambda x: get_embedding(x, engine=embedding_model))
embeddings = train["embedding"].values
# Get out-of-sample predicted class probabilities via cross-validation.
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
labels = train["completion"].values
pred_probs = cross_val_predict(estimator=model, X=embeddings, y=labels, cv=10, method="predict_proba")
The cleanlab package offers an open-source Python implementation of Confident Learning. With one line of code, we can run Confident Learning using the model predicted probabilities to estimate which examples have label issues in our training dataset.
from cleanlab.filter import find_label_issues
# Get indices of examples estimated to have label issues:
issue_idx = find_label_issues(labels, pred_probs,
return_indices_ranked_by='self_confidence') # sort indices by likelihood of label error
Let’s take a look at a few of the label issues automatically identified in our dataset. Here’s one example that is clearly mislabeled:
- Phrase: I'll take a look at getLogEntries when I have time. Would you mind adding me as a committer?
- Label: impolite
Labeling errors like this are why we might be seeing poor model results.

Caption: A few of the top errors that were automatically identified.
Note: find_label_issues is able to determine which of the given labels are potentially incorrect given only the out-of-sample pred_probs.
Filter Label Issues and Fine-tune a more Robust LLM
Now that we have the indices of potentially mislabeled examples (identified via automated techniques), let’s remove these 471 examples from our training dataset. Fine-tuning the exact same Davinci LLM on the filtered dataset achieves a test accuracy of 66% (on the same test data where our original Davinci LLM achieved 63% accuracy). We reduced the error-rate of the model by 8% using less but better quality training data!
# Remove data flagged with potential label error.
train_cl = train.drop(issue_idx).reset_index(drop=True)
format_data(train_cl, "train_cl.jsonl")
# Train a more robust classifier with less erroneous data.
!openai api fine_tunes.create -t "train_cl_prepared.jsonl" -v "test_prepared.jsonl" --compute_classification_metrics --classification_n_classes 3 -m davinci --suffix "dropped"
# Evaluate model on test data.
!openai api fine_tunes.results -i ft-InhTRQGu11gIDlVJUt0LYbEx > autofiltered.csv
df = pd.read_csv('autofiltered.csv')
dropped_acc = df.iloc[-1]['classification/accuracy']
>>> 0.6604166626930237
Fixing the Label Errors
Instead of fixing the auto-detected label issues automatically via filtering, the smarter (yet more complex) way to improve our dataset would be to correct the label issues by hand. This simultaneously removes a noisy data point and adds an accurate one, but making such corrections manually is cumbersome. We did this manually using Cleanlab Studio, an enterprise data correction interface.
After replacing the bad labels we spotted with more suitable ones, we fine-tune the exact same Davinci LLM on the manually-corrected dataset. The resulting model achieves 77% accuracy (on the same test dataset as before), which is a 37% reduction in error from our original version of this model.
# Load in and format data with the manually fixed labels.
train_studio = pd.read_csv('train_corrected.csv')
format_data(train_studio, "train_corrected.jsonl")
# Train a more robust classifier with the fixed data.
!openai api fine_tunes.create -t "train_corrected_prepared.jsonl" -v "test_prepared.jsonl"
--compute_classification_metrics --classification_n_classes 3 -m davinci --suffix "corrected"
# Evaluate model on test data.
!openai api fine_tunes.results -i ft-MQbaduYd8UGD2EWBmfpoQpkQ > corrected .csv
df = pd.read_csv('corrected.csv')
corrected_acc = df.iloc[-1]['classification/accuracy']
>>> 0.7729166746139526
Note: throughout this entire process, we never changed any code related to model architecture/hyperparameters, training, or data preprocessing! All improvement strictly comes from increasing the quality of our training data, which leaves room for additional optimizations on the modeling side.
Evaluating other LLMs
We repeated this same experiment with two other recent LLM models OpenAI offers for fine-tuning: Ada and Curie. The resulting improvements look similar to those achieved for the Davinci model.
Conclusion
Data-centric AI is a powerful paradigm for handling noisy data via AI/automated techniques rather than tedious manual effort. There are now tools to help you efficiently find and fix data and label issues to improve any ML model (not just LLMs) for most types of data (not just text, but also images, audio, tabular data, etc). Such tools utilize any ML model to diagnose/fix issues in the data and then improve the data for any other ML model. These tools will remain applicable with future advances in ML models like GPT-10, and will only become better at identifying issues when used with more accurate models!
Practice data-centric AI to systematically engineer better data via AI/automation. This frees you to capitalize on your unique domain knowledge rather than fixing general data issues like label errors.
Chris Mauck is Data Scientist at Cleanlab.