Pedestrian Detection in Aerial Images Using RetinaNet
Object Detection in Aerial Images is a challenging and interesting problem. By using Keras to train a RetinaNet model for object detection in aerial images, we can use it to extract valuable information.
By Priyanka Kochhar, Deep Learning Consultant
Introduction
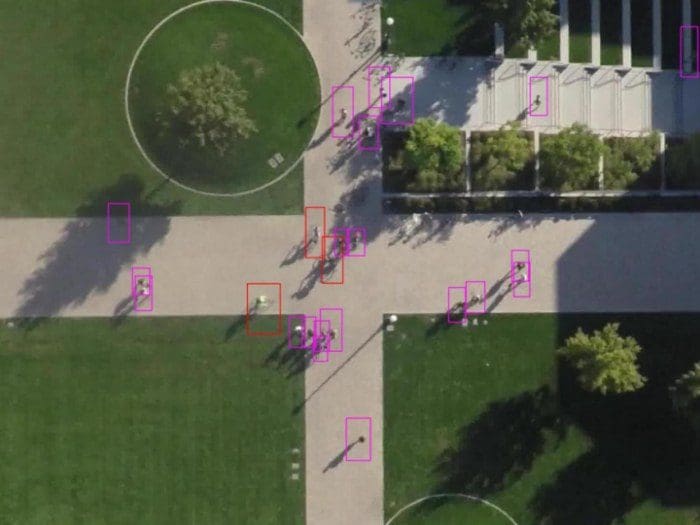
Object Detection in Aerial Images is a challenging and interesting problem. With the cost of drones decreasing, there is a surge in amount of aerial data being generated. It will be very useful to have models that can extract valuable information from aerial data. Retina Net is the most famous single stage detector and in this blog, I want to test it out on an aerial images of pedestrians and bikers from the Stanford Drone Data set. See a sample image below. This is a challenging problem since most objects are only a few pixels wide, some objects are occluded and objects in shade are even harder to detect. I have read several blogs of object detection on aerial images or cars/planes but there are only a few links for pedestrian detection aerially which is especially challenging.
Retina Net
RetinaNet is a single stage detector that uses Feature Pyramid Network (FPN) and Focal loss for training. Feature pyramid network is a structure for multiscale object detection introduced in this paper. It combines low-resolution, semantically strong features with high-resolution, semantically weak features via a top-down pathway and lateral connections. The net result is that it produces feature maps of different scale on multiple levels in the network which helps with both classifier and regressor networks.
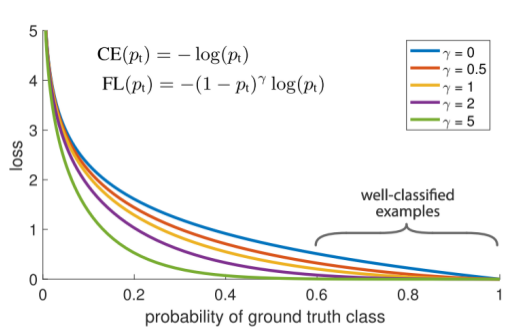
The Focal Loss is designed to address the single-stage object detection problems with the imbalance where there is a very large number of possible background classes and just a few foreground classes. This causes training to be inefficient as most locations are easy negatives that contribute no useful signal and the massive amount of these negative examples overwhelm the training and reduces model performance. Focal loss is based on cross entropy loss as shown below and by adjusting the gamma parameter, we can reduce the loss contribution from well classified examples.
In this blog, I want to talk about how to train a RetinaNet model on Keras. I haven’t done enough justice to the theory behind RetinaNet. I used this link to understand the model and would highly recommend it. My first trained model worked quite well in detecting objects aerially as shown in the video below. I have also open sourced the code on my Github link.

Stanford Drone DataSet
Stanford Drone Data is a massive data set of aerial images collected by drone over the Stanford campus. The data set is ideal for object detection and tracking problems. It contains about 60 aerial videos. For each video we have bounding box coordinates for the 6 classes — “Pedestrian”, “Biker”, “Skateboarder”, “Cart”, “Car” and “ Bus”. The data set is very rich in pedestrians and bikers with these 2 classes covering about 85%-95% of the annotations.
Training a RetinaNet in Keras on Stanford Drone Data Set
To train the Retina Net, I used this implementation in Keras. It is very well documented and works without bugs. Thanks a lot to Fizyr for open sourcing their implementation!
The main steps I followed were:
- Selecting a sample of images from the massive stanford drone data set for building the model. I took about 2200 training images with 30,000+ annoations and kept around 1000 images for validation. I have put my image data set on google drive here for anyone interested in skipping this step.
- Generating annotations in the format required for Retina Net. Retina Net requires all annotations to be in the format.
path/to/image.jpg,x1,y1,x2,y2,class_name
I converted Stanford annotations in this format and my train and validation annotations are uploaded to my Github.
- Adjusting the anchor sizes: The Retina Net has default anchor sizes of 32, 64, 128, 256, 512. These anchor sizes work well for most objects however since we are working on aerial images, some objects may be smaller than 32. This repo provides a handy tool for checking if existing anchors suffice. In the image below annotations in green are covered by existing in anchors and those in red are ignored. As can been seen a good portion of annotations are too small for even the smallest anchor size.

So I adjusted the anchors to drop the biggest one of 512 and instead add a small anchor of size 16. This results in a noticeable improvement as shown below:

- With all this we are ready to start training. I kept most other default parameters including the Resnet50 backbone and started training by:
keras_retinanet/bin/train.py --weights snapshots/resnet50_coco_best_v2.1.0.h5 --config config.ini csv train_annotations.csv labels.csv --val-annotations val_annotations.csv
Here weights are the COCO weights that can be used to jump start training. The annotations for training and validation are the input data and config.ini has the updated anchor sizes. All the files are on my Github repo too.
That’s it! The model is slow to train and I trained it overnight. I tested the accuracy of the trained model by checking for mean average precision (MAP) on the test set. As can be seen below the first trained model had a very good MAP of 0.63. The performance is especially good on car and bus classes which are easy to see aerially. The MAP on Biker class is low as this is often confused by pedestrian. I am currently working on further improving accuracy of the Biker class.
Biker: 0.4862 Car:0.9363 Bus: 0.7892 Pedestrian: 0.7059 Weighted: 0.6376
Conclusion
Retina Net is a powerful model that uses Feature Pyramid Networks. It is able to detect objects aerially on a very challenging data set where object sizes are quite small. I was able to train a Retina Net with half a day of work. The first version of the trained model has pretty good performance. I am still exploring how to further adapt Retina Net architecture to have a higher accuracy in aerial detection. That will be covered in my next blog.
I hope you liked the blog and try training the model yourself too.
I have my own deep learning consultancy and love to work on interesting problems. I have helped many startups deploy innovative AI based solutions. Check us out at — http://deeplearninganalytics.org/.
You can also see my other writings at: http://deeplearninganalytics.org/blog
If you have a project that we can collaborate on, then please contact me through my website or at priya.toronto3@gmail.com
References
Bio: Priyanka Kochhar has been a data scientist for 10+ years. She now has her own deep learning consultancy and loves to work on interesting problems. She has helped several startups deploy innovative AI based solutions. If you have a project that she can collaborate on then please contact her at priya.toronto3@gmail.com
Original. Reposted with permission.
Related:
- People Tracking using Deep Learning
- Introduction to Deep Learning with Keras
- The Keras 4 Step Workflow