An introduction to explainable AI, and why we need it
We introduce explainable AI, why it is needed, and present the Reversed Time Attention Model, Local Interpretable Model-Agnostic Explanation and Layer-wise Relevance Propagation.
By Patrick Ferris.

The Black Box - a metaphor that represents the unknown inner mechanics of functions like neural networks
Neural networks (and all of their subtypes) are increasingly being used to build programs that can predict and classify in a myriad of different settings.
Examples include machine translation using recurrent neural networks, and image classification using a convolutional neural network. Research published by Google DeepMind has sparked interest in reinforcement learning.
All of these approaches have advanced many fields and produced usable models that can improve productivity and efficiency.
However, we don’t really know how they work.
I was fortunate enough to attend the Knowledge Discovery and Data Mining(KDD) conference this year. Of the talks I went to, there were two main areas of research that seem to be on a lot of people’s minds:
- Firstly, finding a meaningful representation of graph structures to feed into neural networks. Oriol Vinyalsfrom DeepMind gave a talk about their Message Passing Neural Networks.
- The second area, and the focus of this article, are explainable AI models. As we generate newer and more innovative applications for neural networks, the question of ‘How do they work?’ becomes more and more important.
Why the need for Explainable Models?
Neural Networks are not infallible.
Besides the problems of overfitting and underfitting that we’ve developed many tools (like Dropout or increasing the data size) to counteract, neural networks operate in an opaque way.
We don’t really know why they make the choices they do. As models become more complex, the task of producing an interpretable version of the model becomes more difficult.
Take, for example, the one pixel attack (see here for a great video on the paper). This is carried out by using a sophisticated approach which analyzes the CNNs and applies differential evolution (a member of the evolutionary class of algorithms).
Unlike other optimisation strategies which restrict the objective function to be differentiable, this approach uses an iterative evolutionary algorithm to produce better solutions. Specifically, for this one pixel attack, the only information required was the probabilities of the class labels.

From One pixel attack for fooling deep neural networks by Jiawei Su et al.
The relative ease of fooling these neural networks is worrying. Beyond this lies a more systemic problem: trusting a neural network.
The best example of this is in the medical domain. Say you are building a neural network (or any black-box model) to help predict heart disease given a patient’s records.
When you train and test your model, you get a good accuracy and a convincing positive predictive value. You bring it to a clinician and they agree it seems to be a powerful model.
But they will be hesitant to use it because you (or the model) cannot answer the simple question: “Why did you predict this person as more likely to develop heart disease?”
This lack of transparency is a problem for the clinician who wants to understand the way the model works to help them improve their service. It is also a problem for the patient who wants a concrete reason for this prediction.
Ethically, is it right to tell a patient that they have a higher probability of a disease if your only reasoning is that “the black-box told me so”? Health care is as much about science as it is about empathy for the patient.
The field of explainable AI has grown in recent years, and this trend looks set to continue.
What follows are some of the interesting and innovative avenues researchers and machine learning experts are exploring in their search for models which not only perform well, but can tell you why they make the choices they do.
Reversed Time Attention Model (RETAIN)
The RETAIN model was developed at Georgia Institute of Technology by Edward Choi et al. It was introduced to help doctors understand why a model was predicting patients to be at risk of heart failure.
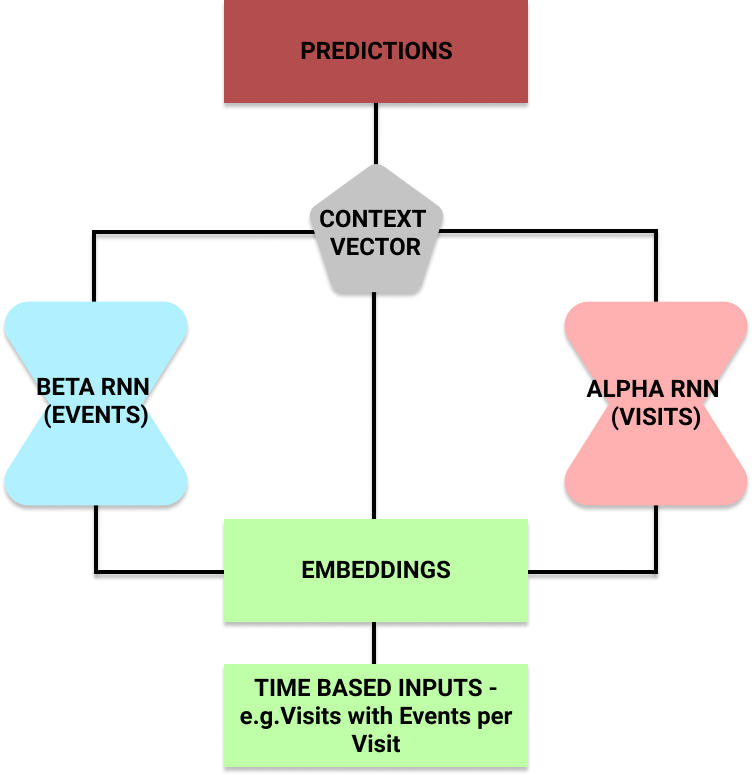
The RETAIN Recurrent Neural Network Model makes use of Attention Mechanisms to improve interpretability
The idea is, given a patients’ hospital visits records which also contain the events of the visit, they could predict the risk of heart failure.
The researchers split the input into two recurrent neural networks. This let them use the attention mechanism on each to understand what the neural network was focusing on.
Once trained, the model could predict a patient’s risk. But it could also make use of the alpha and beta parameters to output which hospital visits (and which events within a visit) influenced its choice.
Local Interpretable Model-Agnostic Explanations (LIME)
Another approach that has become fairly common in use is LIME.
This is a post-hoc model — it provides an explanation of a decision after it has been made. This means it isn’t a pure ‘glass-box’, transparent model (like decision trees) from start to finish.
One of the main strengths of this approach is that it’s model agnostic. It can be applied to any model in order to produce explanations for its predictions.
The key concept underlying this approach is perturbing the inputs and watching how doing so affects the model’s outputs. This lets us build up a picture of which inputs the model is focusing on and using to make its predictions.
For instance, imagine some kind of CNN for image classification. There are four main steps to using the LIME model to produce an explanation:
- Start with a normal image and use the black-box model to produce a probability distribution over the classes.
- Then perturb the input in some way. For images, this could be hiding pixels by coloring them grey. Now run these through the black-box model to see the how the probabilities for the class it originally predicted changed.
- Use an interpretable (usually linear) model like a decision tree on this dataset of perturbations and probabilities to extract the key features which explain the changes. The model is locally weighted — meaning that we care more about the perturbations that are most similar to the original image we were using.
- Output the features (in our case, pixels) with the greatest weights as our explanation.
Layer-wise Relevance Propagation (LRP)
This approach uses the idea of relevance redistribution and conservation.
We start with an input (say, an image) and its probability of a classification. Then, work backwards to redistribute this to all of the inputs (in this case pixels).
The redistribution process is fairly simple from layer to layer.
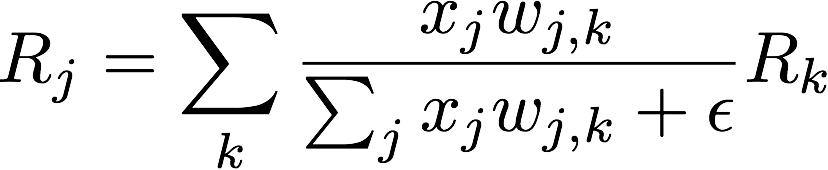
Don’t be scared — this equation is just weighting relevances based on neuron activation and weight connnection
In the above equation, each term represents the following ideas:
- x_j — the activation value for neuronj in layer l
- w_j,k — the weighting of the connection between neuronj in layer l and neuron k in layer l + 1
- R_j — Relevance scores for each neuron in layerl
- R_k — Relevance scores for each neuron in layerl+1
The epsilon is just a small value to prevent dividing by zero.
As you can see, we can work our way backwards to determine the relevance of individual inputs. Further, we can sort these in order of relevance. This lets us extract a meaningful subset of inputs as our most useful or powerful in making a prediction.
What next?
The above methods for producing explainable models are by no means exhaustive. They are a sample of some of the approaches researchers have tried using to produce interpretable predictions from black-box models.
Hopefully this post also sheds some light onto why it is such an important area of research. We need to continue researching these methods, and develop new ones, in order for machine learning to benefit as many fields as possible — in a safe and trustworthy fashion.
If you find yourself wanting more papers and areas to read about, try some of the following.
- DeepMind’s research on Concept Activation Vectors, as well as the slidesfrom Victoria Krakovna’s talk at Neural Information Processing Systems (NIPS) conference.
- A paper by Dung Huk Park et al. on datasets for measuring explainable models.
- Finale Doshi-Velez and Been Kim’s paper on the field in general
Artificial intelligence should not become a powerful deity which we follow blindly. But neither should we forget about it and the beneficial insight it can have. Ideally, we will build flexible and interpretable models that can work in collaboration with experts and their domain knowledge to provide a brighter future for everyone.
Bio: Patrick Ferris is a nineteen year old programmer, blogger and all-round tech enthusiast, and currently Editor in Chief of the Hacker's at Cambridge blog.
Original. Reposted with permission.
Resources:
- On-line and web-based: Analytics, Data Mining, Data Science, Machine Learning education
- Software for Analytics, Data Science, Data Mining, and Machine Learning
Related:
- XAI – A Data Scientist’s Mouthpiece
- Explainable AI or Halting Faulty Models ahead of Disaster
- The AI Black Box Explanation Problem