Data Science with Optimus Part 1: Intro
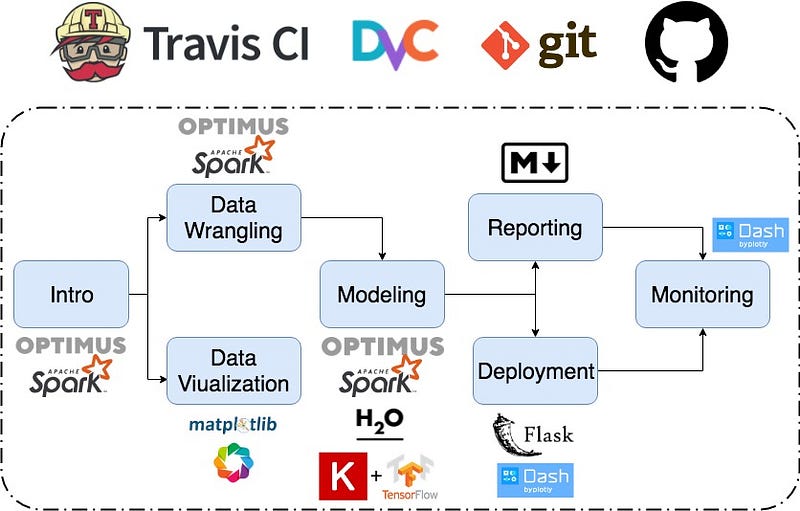
With Optimus you can clean your data, prepare it, analyze it, create profilers and plots, and perform machine learning and deep learning, all in a distributed fashion, because on the back-end we have Spark, TensorFlow, Sparkling Water and Keras. It’s super easy to use.
Data science has reached new levels of complexity and of course awesomeness. I’ve been doing this for years now, I’m what I want for people is to have a clear and easy path to do their job.
I’ve been talking about data science and more for a while now, but it’s time to get our hands dirty and code together.
This is the beginning of a series on articles about data science with Optimus, Spark and Python.
What is Optimus?

If you been following me for a while, you know that me and the Iron-AI team created a library called Optimus.
Optimus V2 was created to make data cleaning a breeze. The API was designed to be super easy for newcomers and very familiar for people that come from working with pandas. Optimus expands the Spark DataFrame functionality, adding .rows and .cols attributes.
With Optimus you can clean your data, prepare it, analyze it, create profilers and plots, and perform machine learning and deep learning, all in a distributed fashion, because on the back-end we have Spark, TensorFlow, Sparkling Water and Keras.
It’s super easy to use. It’s like the evolution of pandas, with a piece of dplyr, joined by Keras and Spark. The code you create with Optimus will work on your local machine, and with a simple change of masters, it can run on your local cluster or in the cloud.
You will see a lot of interesting functions created to help with every step of the data science cycle.
Optimus is perfect as a companion for an agile methodology for data science because it can help you in almost all the steps of the process, and it can easily connect to other libraries and tools.
If you want to read more about an Agile DS Methodology check this out:
Installing Optimus
The install process it’s very simple. Just run the command:
pip install optimuspyspark
And you are ready to rock and roll.
Running Optimus (and Spark, Python, etc.)

Creating a data science environment should be easy. Both for trying stuff and for production. When I was starting thinking on these series of articles I was shocked to find out how hard is to prepare a reproducible environment for data science with free tools.
Some of the contestants were:
Google Colaboratory
colab.research.google.com
But without a doubt the winner for me was MatrixDS:
A Community for Data Scientists by Data Scientists
matrixds.com
With this tool you have a free environment for Python (with JupyterLab) and for R (with R Studio), also tools for presenting like Shiny and Bokeh, and much more. And for free. You will be able to run everything in the repo:
Inside of MatrixDS with a simple fork of the project:
Just create an account and you’re good to go.
The journey
The path above is how I’m going to structure the different blogs, tutorials and articles in the series. I have to tell you right now that I’m preparing a full course that will cover some of this tools with a business perspective with Business Science, here you can see more:
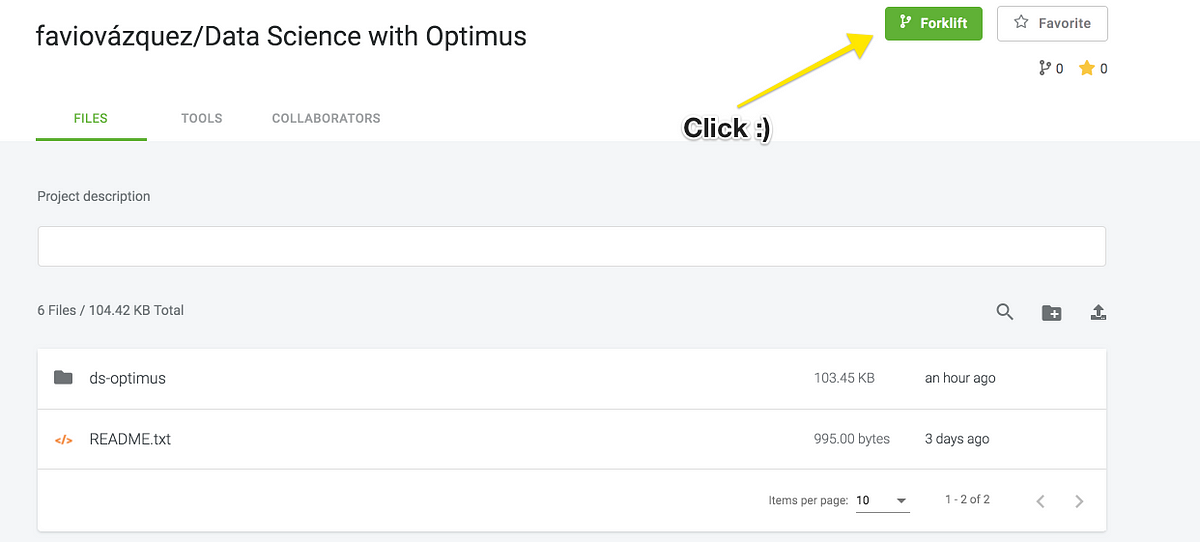
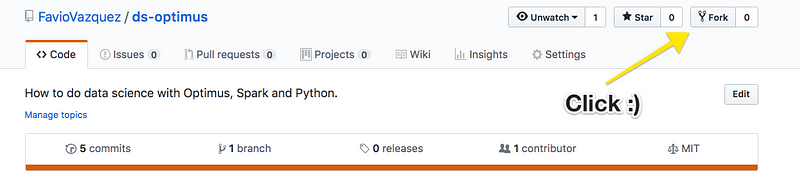
The first part is on MatrixDS and GitHub, so you can just Fork in on GitHub and Forklift it on MatrixDS.
On MatrixDS click on Forklift:
Here’s the notebook, but please check it out in the platforms :)
For updates follow me on Twitter and LinkedIn :).
Bio: Favio Vazquez is a physicist and computer engineer working on Data Science and Computational Cosmology. He has a passion for science, philosophy, programming, and music. He is the creator of Ciencia y Datos, a Data Science publication in Spanish. He loves new challenges, working with a good team and having interesting problems to solve. He is part of Apache Spark collaboration, helping in MLlib, Core and the Documentation. He loves applying his knowledge and expertise in science, data analysis, visualization, and automatic learning to help the world become a better place.
Original. Reposted with permission.
Related:
- Practical Apache Spark in 10 Minutes
- Data Pipelines, Luigi, Airflow: Everything you need to know
- 4 Reasons Why Your Machine Learning Code is Probably Bad