Data Pipelines, Luigi, Airflow: Everything you need to know
This post focuses on the workflow management system (WMS) Airflow: what it is, what can you do with it, and how it differs from Luigi.
By Lorenzo Peppoloni, Lyft

This post is based on a talk I recently gave to my colleagues about Airflow.
In particular, the focus of the talk was: what’s Airflow, what can you do with it and how it differs from Luigi.
Why do you need a WMS
It’s really common in a company to have to move and transform data.
For example, you have plenty of logs stored somewhere on S3, and you want to periodically take that data, extract and aggregate meaningful information and then store them in an analytics DB (e.g., Redshift).
Usually, this kind of tasks are first performed manually, then, as things need to scale up, the process is automated and for example, triggered with cron. Ultimately, you reach a point where the good old cron is not able to guarantee a stable and robust performance. It’s simply not enough anymore.
That’s when you need a workflow management system (WMS).
Airflow
Airflow was developed at Airbnb in 2014 and it was later open-sourced. In 2016 it joined the Apache Software Foundation’s incubation program.
When asked “What makes Airflow different in the WMS landscape?”, Maxime Beauchemin (creator or Airflow) answered:
A key differentiator is the fact that Airflow pipelines are defined as code and that tasks are instantiated dynamically.
Hopefully, at the end of this post, you will be able to understand and, more importantly, to agree (or disagree) with this statement.
Let’s first define the main concepts.
Workflows as DAGs
In Airflow, a workflow is defined as a collection of tasks with directional dependencies, basically a directed acyclic graph (DAG).
Each node in the graph is a task, and edges define dependencies among the tasks.
Tasks belong to two categories:
- Operators: they execute some operation
- Sensors: they check for the state of a process or a data structure
Real-life workflows can go from just one task per workflow (you don’t always have to be fancy) to very complicated DAGs, almost impossible to visualise.
Main components
The main components of Airflow are:
- a Metadata Database
- a Scheduler
- an Executor

The metadata database stores the state of tasks and workflows. The scheduler uses the DAGs definitions, together with the state of tasks in the metadata database, and decides what needs to be executed.
The executor is a message queuing process (usually Celery) which decides which worker will execute each task.
With the Celery executor, it is possible to manage the distributed execution of tasks. An alternative is to run the scheduler and executor on the same machine. In that case, the parallelism will be managed using multiple processes.
Airflow provides also a very powerful UI. The user is able to monitor DAGs and tasks execution and directly interact with them through a web UI.
It is common to read that Airflow follows a “set it and forget it” approach, but what does that mean?
It means that once a DAG is set, the scheduler will automatically schedule it to run according to the specified scheduling interval.
Luigi
The easiest way to understand Airflow is probably to compare it to Luigi.
Luigi is a python package to build complex pipelines and it was developed at Spotify.
In Luigi, as in Airflow, you can specify workflows as tasks and dependencies between them.
The two building blocks of Luigi are Tasks and Targets. A target is a file usually outputted by a task, a task performs computations and consumes targets generated by other tasks.
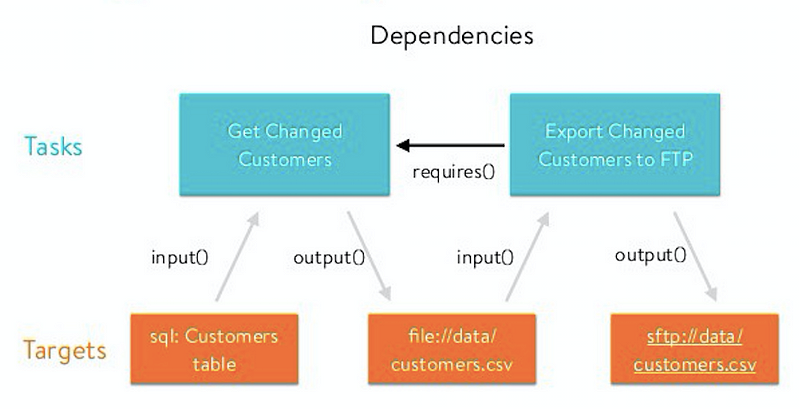
You can think about it as an actual pipeline. A task does its job and generates a target as a result, a second task takes the target file in input, performs some operations and output a second target file and so on.

A simple workflow
Let’s see how we can implement a simple pipeline composed of two tasks.
The first task generate a .txt file with a word (“pipeline” in this case), a second task reads the file and decorate the line adding “My”. The new line is written on a new file.
Each task is specified as a class derived from luigi.Task, the method output() specifies the output thus the target, run()specifies the actual computations performed by the task.
The method requires() specifies the dependencies between the tasks.
From the code, it’s pretty straightforward to see that the input of a task is the output of the other and so on.
Let’s see how we can do the same thing in Airflow.
First, we define and initialise the DAG, then we add two operators to the DAG.
The first one is a BashOperator which can basically run every bash command or script, the second one is a PythonOperator executing python code (I used two different operators here for the sake of presentation).
As you can see, there are no concepts of input and output. No information is shared between the two operators. There are ways to share information between operators (you basically share a string), but as a general rule: if two operators need to share information, then they should be probably combined into a single one.
A more complex workflow
Let’s now consider the case where we want to process more files at the same time.
In Luigi we can do it in multiple ways, none of which is really straightforward.
In this case, we have two tasks, each one of them processes all the files. The dependent task (t2) has to wait until t1 has processed all the files.
We used an empty file as a target to flag when each task finished its job.
We could add some parallelisation writing parallel for loops.
The problem with this solution is that t2 could start to process files gradually as soon as t1 started to produce its output, actually t2 does not have to wait until all the files are created by t1.
A common pattern in Luigi to do this is to create a wrapper task and use multiple workers.
Here is the code.
To run the task with multiple workers we can specify — workers number_of_workers when running the task.
A very common approach that you see in real life is to delegate the parallelisation. Basically, you use the first approach presented and you use Spark for example, inside the run() function, to actually do the processing.
Let’s do it with Airflow
Do you remember that in the initial quote it was written that DAGs are instantiated dynamically with code?
But what does that mean exactly?
It means that with Airflow you can do this
Tasks (and dependencies) can be added programmatically (e.g. in a for loop). The corresponding DAG looks like this.

At this point, you don’t have to worry about parallelisation. The Airflow executor knows from the DAG definition, that each branch can be run in parallel and that’s what it does!
Final Considerations
We touched a lot of points in this post, we spoke about workflows, about Luigi, about Airflow and how they differ.
Let’s make a quick recap.
Luigi
- It’s generally based on pipelines, tasks input and output share information and is connected together
- Target-based approach
- UI is minimal, there is no user interaction with running processes
- Does not have it’s own triggering
- Luigi does not support distributed execution
Airflow
- Based on DAGs representation
- In general, no information is shared between tasks, we want to parallelise as much as possible
- No powerful mechanism to communicate between tasks
- It has an executor, which manages distributed execution (you need to set it up)
- The approach is “set it and forget it“ since it has its own scheduler
- Powerful UI, you can see executions and interact with running tasks.
Conclusions: In the article we had a look at Airflow and Luigi and how the two differs in the landscape of workflow management systems. We had a look at some very simple examples of pipelines and how they can implement with both the tools. Finally we summed up the main differences between Luigi and Airflow.
If you enjoy the article and you found it useful feel free to ???? or share.
Cheers
Bio: Lorenzo Peppoloni is a tech enthusiast, life-long learner, with a PhD in Robotics. He writes about his day to day experience in Software and Data Engineering.
Original. Reposted with permission.
Related:
- A Beginner’s Guide to the Data Science Pipeline
- How A Data Scientist Can Improve Productivity
- Manage your Machine Learning Lifecycle with MLflow – Part 1