 4 Reasons Why Your Machine Learning Code is Probably Bad
4 Reasons Why Your Machine Learning Code is Probably Bad
 4 Reasons Why Your Machine Learning Code is Probably Bad
4 Reasons Why Your Machine Learning Code is Probably BadYour current ML workflow probably chains together several functions executed linearly. Instead of linearly chaining functions, data science code is better written as a set of tasks with dependencies between them. That is your data science workflow should be a DAG.
By Norman Niemer, Chief Data Scientist
Your current workflow probably chains several functions together like in the example below. While quick, it likely has many problems:
- it doesn't scale well as you add complexity
- you have to manually keep track of which functions were run with which parameter
- you have to manually keep track of where data is saved
- it's difficult for others to read
import pandas as pd
import sklearn.svm, sklearn.metrics
def get_data():
data = download_data()
data = clean_data(data)
data.to_pickle('data.pkl')
def preprocess(data):
data = apply_function(data)
return data
# flow parameters
reload_source = True
do_preprocess = True
# run workflow
if reload_source:
get_data()
df_train = pd.read_pickle('data.pkl')
if do_preprocess:
df_train = preprocess(df_train)
model = sklearn.svm.SVC()
model.fit(df_train.iloc[:,:-1], df_train['y'])
print(sklearn.metrics.accuracy_score(df_train['y'],model.predict(df_train.iloc[:,:-1])))
What to do about it?
Instead of linearly chaining functions, data science code is better written as a set of tasks with dependencies between them. That is your data science workflow should be a DAG.
So instead of writing a function that does:
def process_data(data, parameter):
if parameter:
data = do_stuff(data)
else:
data = do_other_stuff(data)
data.to_pickle('data.pkl')
return data
You are better of writing tasks that you can chain together as a DAG:
class TaskProcess(d6tflow.tasks.TaskPqPandas): # define output format
def requires(self):
return TaskGetData() # define dependency
def run(self):
data = self.input().load() # load input data
data = do_stuff(data) # process data
self.save(data) # save output data
The benefits of doings this are:
- All tasks follow the same pattern no matter how complex your workflow gets
- You have a scalable input
requires()and processing functionrun() - You can quickly load and save data without having to hardcode filenames
- If the input task is not complete it will automatically run
- If input data or parameters change, the function will automatically rerun
An example machine learning DAG
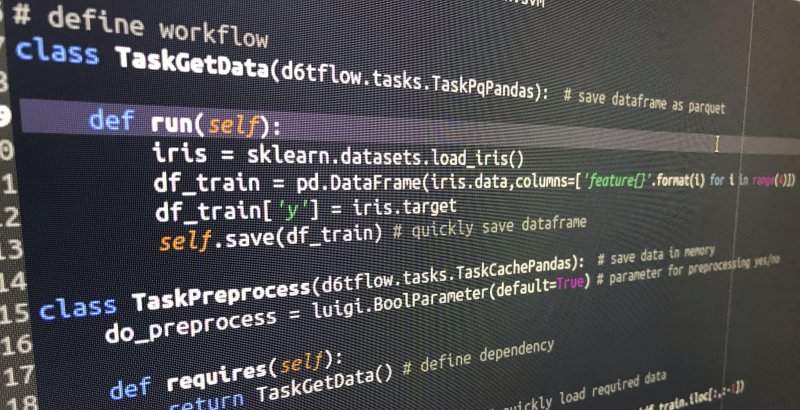
Below is a stylized example of a machine learning flow which is expressed as a DAG. In the end you just need to run TaskTrain() and it will automatically know which dependencies to run. For a full example see https://github.com/d6t/d6tflow/blob/master/docs/example-ml.md
import pandas as pd
import sklearn, sklearn.svm
import d6tflow
import luigi
# define workflow
class TaskGetData(d6tflow.tasks.TaskPqPandas): # save dataframe as parquet
def run(self):
data = download_data()
data = clean_data(data)
self.save(data) # quickly save dataframe
class TaskPreprocess(d6tflow.tasks.TaskCachePandas): # save data in memory
do_preprocess = luigi.BoolParameter(default=True) # parameter for preprocessing yes/no
def requires(self):
return TaskGetData() # define dependency
def run(self):
df_train = self.input().load() # quickly load required data
if self.do_preprocess:
df_train = preprocess(df_train)
self.save(df_train)
class TaskTrain(d6tflow.tasks.TaskPickle): # save output as pickle
do_preprocess = luigi.BoolParameter(default=True)
def requires(self):
return TaskPreprocess(do_preprocess=self.do_preprocess)
def run(self):
df_train = self.input().load()
model = sklearn.svm.SVC()
model.fit(df_train.iloc[:,:-1], df_train['y'])
self.save(model)
# Check task dependencies and their execution status
d6tflow.preview(TaskTrain())
'''
└─--[TaskTrain-{'do_preprocess': 'True'} (PENDING)]
└─--[TaskPreprocess-{'do_preprocess': 'True'} (PENDING)]
└─--[TaskGetData-{} (PENDING)]
'''
# Execute the model training task including dependencies
d6tflow.run(TaskTrain())
'''
===== Luigi Execution Summary =====
Scheduled 3 tasks of which:
* 3 ran successfully:
- 1 TaskGetData()
- 1 TaskPreprocess(do_preprocess=True)
- 1 TaskTrain(do_preprocess=True)
'''
# Load task output to pandas dataframe and model object for model evaluation
model = TaskTrain().output().load()
df_train = TaskPreprocess().output().load()
print(sklearn.metrics.accuracy_score(df_train['y'],model.predict(df_train.iloc[:,:-1])))
# 0.9733333333333334
Conclusion
Writing machine learning code as a linear series of functions likely creates many workflow problems. Because of the complex dependencies between different ML tasks it is better to write them as a DAG. https://github.com/d6t/d6tflow makes this very easy. Alternatively you can use luigi and airflow but they are more optimized for ETL than data science.
Bio: Norman Niemer is the Chief Data Scientist at a large asset manager where he delivers data-driven investment insights. He holds a MS Financial Engineering from Columbia University and a BS in Banking and Finance from Cass Business School (London).
Original. Reposted with permission.
Related:
- The Machine Learning Project Checklist
- Data Science Project Flow for Startups
- End To End Guide For Machine Learning Projects