PySyft and the Emergence of Private Deep Learning
PySyft is an open-source framework that enables secured, private computations in deep learning, by combining federated learning and differential privacy in a single programming model integrated into different deep learning frameworks such as PyTorch, Keras or TensorFlow.

Trust is a key factor in the implementation of deep learning applications. From training to optimization, the lifecycle of a deep learning model is tied to trusted data exchanges between different parties. That dynamic is certainly effective for a lab environment but results are vulnerable to all sorts of security attacks that manipulate the trusted relationships among the different participants in a model. Let’s take the example of a credit scoring model that uses a financial transaction to classify the credit risk of a specific customer.
The traditional mechanisms for training or optimizing a model assume that the entities performing those actions will have full access to those financial datasets which opens the door to all sorts of privacy risks. As deep learning evolves, the need for mechanisms that enforce privacy constraints during the lifecycle of the datasets and model is becoming increasingly important. Among the technologies trying to address this monumental challenge, PySyft is a recent framework that has been steadily gaining traction within the deep learning community.
The importance of privacy in deep learning application is directly tied to the emergence of distributed, multi-party models. The traditional approach to deep learning solutions relies on centralized parties that control the entire lifecycle of a model even if using large distributed computing infrastructure. This is the case of an organization that creates a prediction model that manages the preferences of customers visiting its website. However, centralized deep learning topologies have proven impractical in scenarios such as mobile or internet of things(IOT) that rely on a large number of devices producing data and executing models.
In those scenarios, the distributed parties are not only often producing sensitive datasets but also executing and evaluating the performance of deep learning models. That dynamic requires a bidirectional privacy relationship between different parties responsible for creating, training and executing deep learning models.
The transition towards more distributed architectures is one of the primary forces behind the need for strong privacy mechanisms in deep learning models. That’s the challenge that PySyft setup to address but it wouldn’t have been possible without the evolution of several areas of research in machine learning and distributed programming.
The Enablers
Privacy in deep learning models has been a well-known problem for years but the technologies that can provide a solution are just now achieving certain levels of viability. In the case of PySyft, the framework leverages three of the most fascinating techniques in machine learning and cryptography of the last decade:
- Secured Multi-Party Computations
- Federated Learning
- Differential Privacy
Secured Multi-Party Computations
Secured Multi-Party Computations (sMPC) is a cryptographic technique that allows different parties to perform computations over inputs while maintaining those inputs private. In computer science theory, sMPC is often seen as a solution to the famous Yao’s Millionaires’ Problem introduced in the 1980s by the computer scientist Andrew Yao. The problem describes a setting in which multiple millionaires would like to know which of them is richer without disclosing their actual wealth. The millionaire’s problem is present in many real world scenarios such as auctions, elections or online gaming.
Conceptually, sMPC replaces the need for a trusted intermediary with secured computations. In the sMPC model, a set of parties with private inputs compute distributed functions such as security properties like fairness, privacy and correctness are preserved.
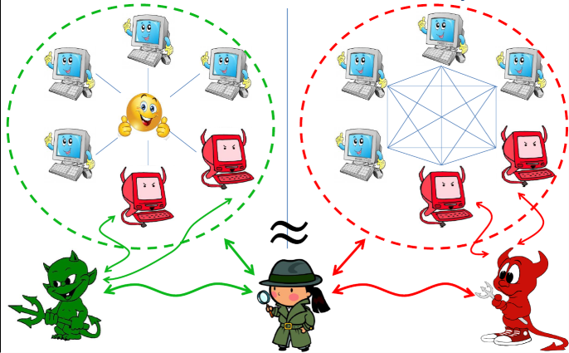
Federated learning is a new learning architecture for AI systems that operate in highly distributed topologies such as mobile or internet of things(IOT) systems. Initially proposed by Google research labs, federated learning represents an alternative to centralized AI training in which a shared global model is trained under the coordination of a central server, from a federation of participating devices. In that model, the different devices can contribute to the training and knowledge of the model while keeping most of the data in the device.
In a federated learning model, a party downloads the a deep learning model, improves it by learning from data on a given device, and then summarizes the changes as a small focused update. Only this update to the model is sent to the cloud, using encrypted communication, where it is immediately averaged with other user updates to improve the shared model. All the training data remains on the original device, and no individual updates are stored in the cloud.
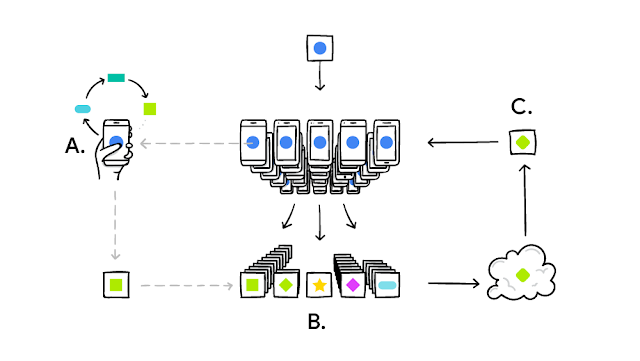
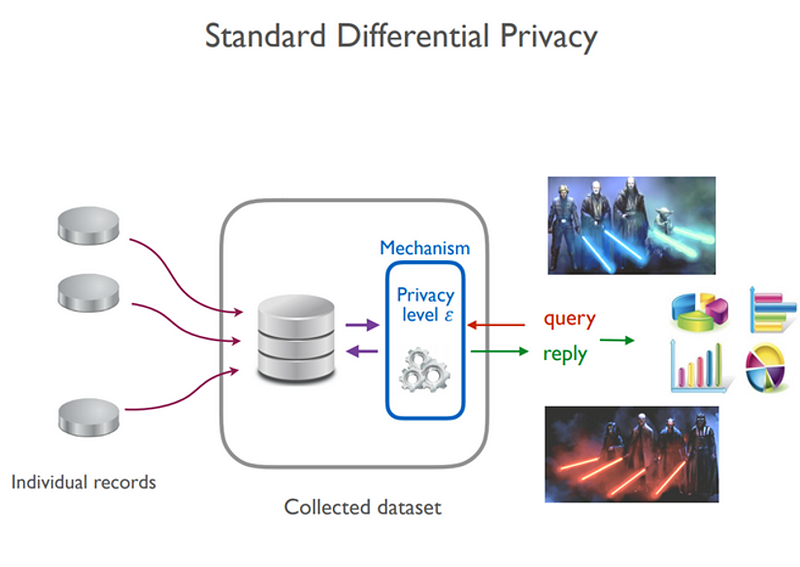
Differential privacy is a technique used to limit the impact that statistical algorithms can have on the privacy of subjects whose information is part of a larger dataset. Roughly, an algorithm is differentially private if an observer seeing its output cannot tell if a particular individual’s information was used in the computation. Differential privacy often discussed in the context of identifying individuals whose information may be in a database. Although it does not directly refer to identification and re-identification attacks, differentially private algorithms provably resist such attacks.
PySyft
PySyft is a framework that enables secured, private computations in deep learning models. PySyft combines federated learning, secured multiple-party computations and differential privacy in a single programming model integrated into different deep learning frameworks such as PyTorch, Keras or TensorFlow. The principles of PySyft were originally outlined in a research paper and its first implementation was lead by OpenMind, one of the leading decentralized AI platforms.
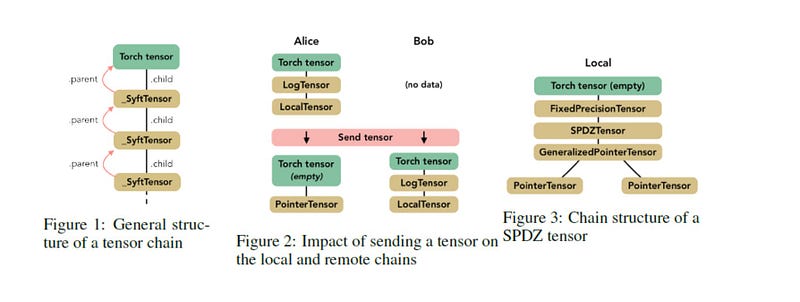
The core component of PySyft is an abstraction called the SyftTensor. SyftTensors are meant to represent a state or transformation of the data and can be chained together. The chain structure always has at its head the PyTorch tensor, and the transformations or states embodied by the SyftTensors are accessed downward using the child attribute and upward using the parent attribute.
Using PySyft is relatively simple and not very different than your standard PyTorch or Keras program. The animation below illustrates a simple classification model developed using PySyft.
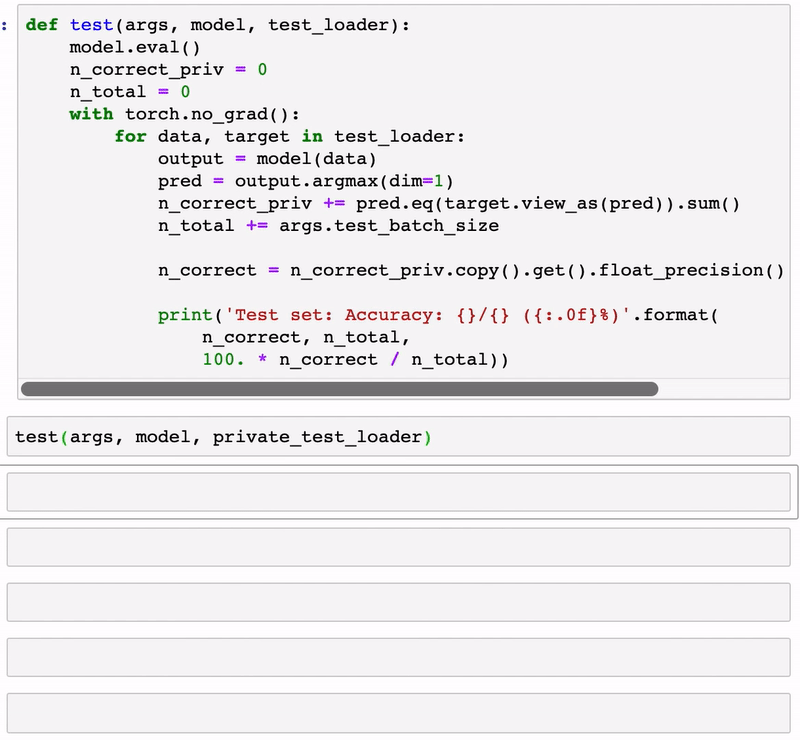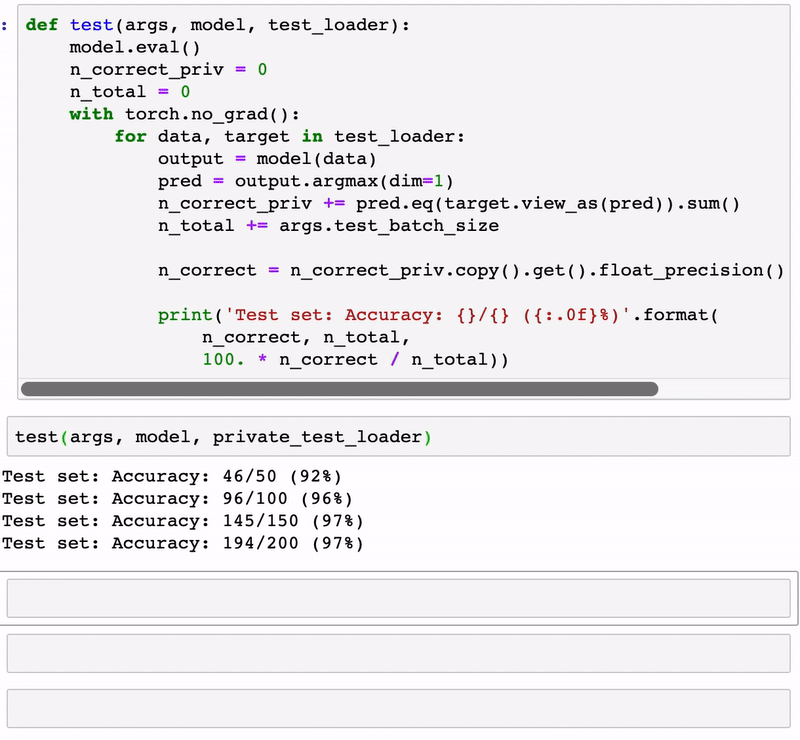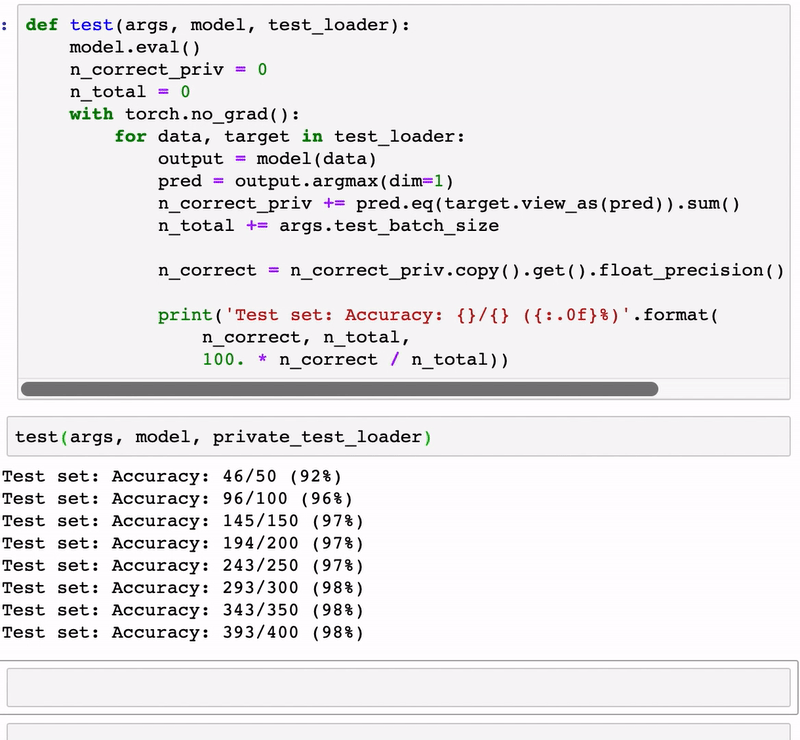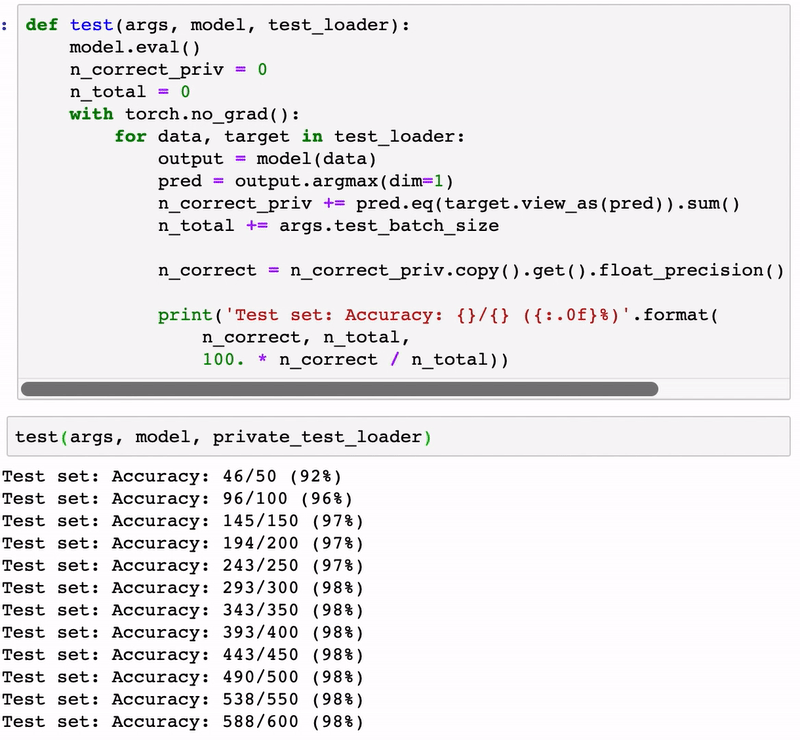
PySyft represents one of the first attempts to enable robust privacy models in deep learning programs. As the space evolves, privacy is likely to become one of the foundational building blocks of the next generation of deep learning frameworks.
Original. Reposted with permission.
Bio: Jesus Rodriguez is a technology expert, executive investor, and startup advisor. A software scientist by background, Jesus is an internationally recognized speaker and author with contributions that include hundreds of articles and presentations at industry conferences.
Related: