A Gentle Guide to Starting Your NLP Project with AllenNLP
For those who aren’t familiar with AllenNLP, I will give a brief overview of the library and let you know the advantages of integrating it to your project.
By Yasufumi Taniguchi, NLP Engineer

Do you happen to know the library, AllenNLP? If you’re working on Natural Language Processing (NLP), you might hear about the name. However, I guess a few people actually use it. Or the other has tried before but hasn’t know where to start because there are lots of functions. For those who aren’t familiar with AllenNLP, I will give a brief overview of the library and let you know the advantages of integrating it to your project.
AllenNLP is the deep learning library for NLP. Allen Institute for Artificial Intelligence, which is one of the leading research organizations of Artificial Intelligence, develops this PyTorch-based library. Using AllenNLP to develop a model is much easier than building a model by PyTorch from scratch. Not only it provides easier development but also supports the management of the experiments and its evaluation after development. AllenNLP has the feature to focus on research development. More specifically, it’s possible to prototype the model quickly and makes easier to manage the experiments with a lot of different parameters. Also, it has consideration using readable variable names.
We might have the experience to get messy codes or lost our important experimental result by coding from scratch.

In AllenNLP, we should follow the development and experiment flow below.
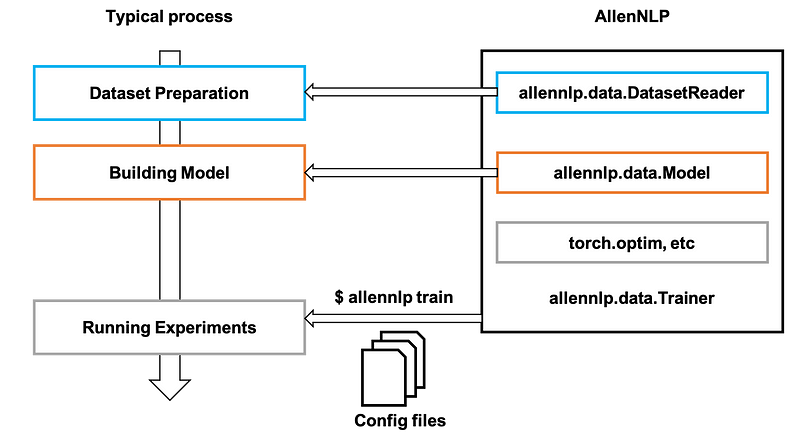
According to your own research project, you only need to implement DatasetReader and Model, and then run your various experiments with config files. Basically, we need to understand three features below to start our project with AllenNLP
- Define Your DatasetReader
- Define Your Model
- Setup Your Config Files
In other words, once you get to understand it, you are able to do scalable development. In this post, I’ll explain the three key features above with tackling a sentiment analysis task. Also, you can check the code using in the post as follows:
Let’s get started!
0. Quick Recap: Sentiment Analysis
Here I’ll explain the basis of sentiment analysis task for those who aren’t familiar with it. So if you’ve already known it well, please proceed the next section: 1. Define DatasetReader.
Sentiment analysis is a task that tries to classify the polarity (positive or negative) of a given document. In this post, we use the movie reviews in IMDBas given documents. For example, we’re going to find the positive and the negative reviews in Avengers: Endgame’s User Reviews. In this time, we’ll use the dataset provided in the link below.
We’re going to build the model takes the documents (the reviews) as input and predicts the label (the polarity) as output. We should prepare the pair of the document and the label as the dataset.
1. Define Your DatasetReader
The figure below shows the DatasetReader class in AllenNLP. This class mainly handles the data using in the task.

The DatasetReader takes raw dataset as input and applies the preprocessing like lowercasing, tokenization and so on. Finally, it outputs the list of the Instance object which holds preprocessed each data as attributes. In this post, the Instance object has the document and the label information as attributes.
First, we should inherit the DatasetReader class to make our own. Then we need to implement the three methods: __init__ ,_readandtext_to_instance. So let’s look at the way how to implement our own DatasetReader. I’ll skip the implementation of the read method because it doesn’t relate to the usage of AllenNLP so much. But if you’re interested in it, you can refer to this link though.
The implementation __init__ will be as follows. We can control the arguments of this method via config files.
@DatasetReader.register('imdb')
ImdbDatasetReader(DatasetReaer):
def __init__(self, token_indexers, tokenizer):
self._tokenizer = tokenizer
self._token_indexers = token_indexers
In this post, I set token_indexers and tokenizer as the arguments because I assume that we change the way of indexing or tokenization in the experiments. The token_indexers performs indexing and the tokenizerperforms tokenization. The class I implemented has the decorator(DatasetReader.register('imdb')) which enables us to control it by config files.
The implementation text_to_instance will be as follows. This method is the main process of DatasetReader. The text_to_instance takes each raw data as input, applies some preprocessing and output each raw data as a Instance. In IMDB, it takes the review string and the polarity label as input.
@DatasetReader.register('imdb')
ImdbDatasetReader(DatasetReaer):
...
def text_to_instance(self, string: str, label: int) -> Instance:
fields = {}
tokens = self._tokenizer.tokenize(string)
fields['tokens'] = TextField(tokens, self._token_indexers)
fields['label'] = LabelField(label, skip_indexing=True)
return Instance(fields)
In AllenNLP, the Instance’s attributes correspond to the Field. We can create the Instance from the dictionary of the Fields. The Instance’s attributes stand each data like a document or a label. In IMDB, the Instance hash two attributes: the review and the label. The review and the label correspond to the TextField and the LabelField respectively.
The mentioned above is the way to define our DatasetReader. You can refer to the whole code from this link.
2. Define Your Model
The figure below shows the Model class in AllenNLP. This class mainly builds the model to solve the task.

The Model takes the data as input and outputs the results of the forward computation and the evaluation metrics as the dictionary.
First, we should inherit the Model class to make our own. Then we need to implement the three methods: __init__ ,forward andget_metrics. Here we implement the polarity classification model for IMDB’s reviews with Recurrent Neural Network (RNN).
The implementation __init__ will be as follows. We can control the arguments of this method via config files the same as the DatasetReader.
@Model.register('rnn_classifier')
class RnnClassifier(Model):
def __init__(self, vocab, text_field_embedder,
seq2vec_encoder, label_namespace):
super().__init__(vocab)
self._text_field_embedder = text_field_embedder
self._seq2vec_encoder = seq2vec_encoder
self._classifier_input_dim = self._seq2vec_encoder.get_output_dim()
self._num_labels = vocab.get_vocab_size(namespace=label_namespace)
self._classification_layer = nn.Linear(self._classifier_input_dim, self._num_labels)
self._accuracy = CategoricalAccuracy()
self._loss = nn.CrossEntropyLoss()
In this post, I set text_field_embedder and seq2vec_encoder as the arguments because I assume that we change the way of embedding or RNN types in the experiments. The text_field_embedder embeds the token as the vector and the seq2vec_encoder encodes the sequence of the tokens with RNN (Technically you can use other types except for RNN). The class I implemented has the decorator (Model.register('rnn_classifier')) which enables us to control it by config files.
The implementation of forward will be as follows. This method is the main process of Model. The forward takes the data as input, calculate by the forward computation, and outputs the results of predicted labels and the evaluation metrics as the dictionary. Most implementation is the same as the way of PyTorch. However, please note that we should return results as the dictionary.
def forward(self, tokens, label=None):
embedded_text = self._text_field_embedder(tokens)
mask = get_text_field_mask(tokens).float()
encoded_text = self._dropout(self._seq2vec_encoder(embedded_text, mask=mask))
logits = self._classification_layer(encoded_text)
probs = F.softmax(logits, dim=1)
output_dict = {'logits': logits, 'probs': probs}
if label is not None:
loss = self._loss(logits, label.long().view(-1))
output_dict['loss'] = loss
self._accuracy(logits, label)
return output_dict
This implementation above computes the classification probabilities for polarity, the cross-entropy loss, and the accuracy. We compute the classification probabilities from the output of RNN through softmax. Also, we compute the model’s classification accuracy if the label is given. Finally, it outputs each computational result as the dictionary (output_dict).
The implementation get_metrics will be as follows.
def get_metrics(self, reset=False):
return {'accuracy': self._accuracy.get_metric(reset)}
It returns the value of the accuracy as the dictionary. This is because we use the model’s accuracy as the metric in this time. We can use multiple values in the get_metrics method.
The mentioned above is the way to define our Model. You can refer to the whole code from this link.
3. Setup Your Config Files
The figure below shows the way how to run our experiments in AllenNLP. We can run our experiments by passing our config files to the allennlp traincommand.
I’ll explain the way how to make our config files to control our experiments. We can make config files with the GUI interface via the command below. But I’ll explain from scratch for better understanding.
allennlp configure --include-package allennlp_imdb
The config file mainly consists of the dataset_reader field, the model field, and the trainer field.
{
"dataset_reader": {...},
"model": {...},
"trainer": {...}
}
The dataset_reader field and the model field specify the settings of the DatasetReader and the Model we implemented so far respectively. Also, the trainer field specifies the settings for optimizers, the number of epochs, and devices (CPU/GPU). You can refer to the whole config files from this link. Next, I’ll explain the important parts of these three fields each.
The settings for DatasetReader will be as follows.
"dataset_reader": {
"type": "imdb",
"token_indexers": {
"tokens": {
"type": "single_id"
}
},
"tokenizer": {
"type": "word"
}
}
First, we specify which DatasetReader we use in type. We can use our ImdbDatasetReader to set type as imdb because it’s ready to use by @DatasetReader.register('imdb'). AllenNLP provides a lot of popular datasets already. You can check these from the document.
Then, we specify the arguments for the ImdbDatasetReader.__init__ method. We use SingleIdTokenIndexer for token_indexers because we want the token to correspond to the single id. Also, we use WordTokenizer for tokenizer because we want the token to be the one word.
The settings for Model will be as follows.
"model": {
"type": "rnn_classifier",
"text_field_embedder": {
"token_embedders": {
"type": "embedding",
...
}
},
"seq2vec_encoder": {
"type": "gru",
...
}
}
First, we specify which Model we use in type the same as DatasetReader. We can use our RnnClassifier to set type as rnn_classifier because it’s ready to use by @Model.register('rnn_classifier').
Then, we specify the arguments for the RnnClassifier.__init__ method. We use Embedding for text_field_embedder because we want to embed the word as the vector. Also, we use GRU for seq2vec_encoder because we want to encode the sequence of embedded words via GRU.
The settings for Trainer will be as follows.
"trainer": {
"num_epochs": 10,
"optimizer": {
"type": "adam"
}
}
The num_epochs specifies the number of epochs to train. The optimizerspecifies the optimizer to update the parameters, in this case, we choose to use adam.
The mentioned above is the way to set up your config file.
We can run the experiment by executing the following command:
allennlp train \
--include-package allennlp_imdb \
-s /path/to/storage \
-o '{"trainer": {"cuda_device": 0}} \
training_config/base_cpu.jsonnet
We need to make our new config file when we want to change the experimental setting. But we can change the setting by the following command though if the changes are a few. The command below updates GRU to LSTM.
allennlp train \
--include-package allennlp_imdb \
-s /path/to/storage \
-o '{"trainer": {"cuda_device": 0}} \
-o '{"model": {"seq2vec_encoder": {"type": "lstm"}}}' \
training_config/base_cpu.jsonnet
That’s all for the explanation. Thank you for reading my post. I hope you understand the way how to build your data loader and model and manage your experiments in AllenNLP.
Thanks to BrambleXu.
Bio: Yasufumi Taniguchi is an NLP Engineer at a Japanese company. His interest lies in question answering, information retrieval, and open-source development.
Original. Reposted with permission.
Related:
- NLP vs. NLU: from Understanding a Language to Its Processing
- Practical Speech Recognition with Python: The Basics
- Examining the Transformer Architecture – Part 2: A Brief Description of How Transformers Work