Pre-training, Transformers, and Bi-directionality
Bidirectional Encoder Representations from Transformers BERT (Devlin et al., 2018) is a language representation model that combines the power of pre-training with the bi-directionality of the Transformer’s encoder (Vaswani et al., 2017). BERT improves the state-of-the-art performance on a wide array of downstream NLP tasks with minimal additional task-specific training.
By Bilal Shahid (Edited by Danny Luo, Susan Chang, Serena McDonnell & Lindsay Brin)
Bidirectional Encoder Representations from Transformers BERT (Devlin et al., 2018) is a language representation model that combines the power of pre-training with the bi-directionality of the Transformer’s encoder (Vaswani et al., 2017). BERT improves the state-of-the-art performance on a wide array of downstream NLP tasks with minimal additional task-specific training. This paper was presented and discussed in an AISC session led by Danny Luo. The details of the event can be found on the AISC website, and the Youtube video of the session can be found here. In this article, we start off by describing the model architecture. We then dive into the training mechanics, main contributions of the paper, experiments, and results.
Model Architecture
BERT is a multi-layer Transformer encoder (Vaswani et al., 2017) with bi-directionality. A Transformer’s architecture is purely based on self-attention, abandoning the RNN and CNN architectures commonly used for sequence modelling. The goal of self-attention is to capture the representation of each sequence by relating different positions of the sequence. Using this foundation, BERT breaks the familiar left-to-right indoctrination that is inherent in earlier text analysis and representation models. The original Transformer architecture, as depicted in (Vaswani et al., 2018), is shown below. Note that BERT uses only the encoder portion (left side) of this Transformer.
![]()
Figure 2 - Transformer Architecture (Vaswani etal., 2018). BERT only uses the encoder part of this Transformer, seen on the left.
Input Representation
BERT represents a given input token using a combination of embeddings that indicate the corresponding token, segment, and position. Specifically, WordPiece embeddings (Wu et al., 2016)with a token vocabulary of 30,000 are used. The input representation is optimized to unambiguously represent either a single text sentence or a pair of text sentences. In the case of two sentences, each token in the first sentence receives embedding A, and each token in the second sentence receives embedding B, and the sentences are separated by the token [SEP]. The supported sequence length is 512 tokens. The following is an example of how an input sequence is represented in BERT.
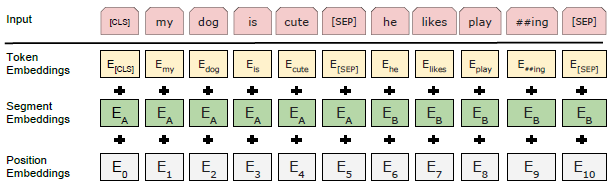
Figure 3: BERT input representation (Devlin et al., 2018)
Novel Training Tasks for New Learning Objectives
The first major contribution of this paper is the use of two novel tasks to pre-train BERT. The first task is the Masked Language Model (MLM), which introduces a new training objective for pre-training, and enables the training of a deep bidirectional embedding. With MLM, instead of predicting the complete incoming sequence by going from left to right or vice versa, the model masks a percentage of tokens at random, and only predicts those masked tokens. However, a simplistic masking of some tokens, with a tag like [MASK], will introduce a mismatch between pre-training and fine-tuning, because [MASK] will remain unseen by the system during fine-tuning. To overcome this, and with the goal to bias the representation towards the observed word, the following masking criterion is adopted: 15% of all WordPiece tokens (Wu et al., 2016) in a sequence are masked at random. Of all these masked tokens, 80% are replaced with the [MASK] token, 10% are replaced with random words, and 10% use the original words.
The second task is ‘next sentence prediction’. This pre-training task allows the language model to capture relationships between sentences, which is useful for downstream tasks such as Question Answering and Natural Language inference. Specifically, each pre-training example for this task consists of a sequence of two sentences. 50% of the time, the actual next sentence follows the first sentence, while 50% of the time a completely random sentence follows. BERT must identify if the second sentence indeed follows the first sentence in the original text. The purpose of the next sentence prediction task is to improve performance on tasks involving pairs of sentences.
Pre-training Specifics
The pre-training procedure uses BooksCorpus (800M words) (Zhu et al., 2015) and text passages from English Wikipedia (2,500 words). Each training input sequence consists of two spans of texts (referred to as “sentences” in this text, but could be longer or shorter than an actual linguistic sentence) from the corpus. The two spans are concatenated as (embedding A - [SEP] - embedding B). In keeping with the ‘next sentence prediction’ task, 50% of the time B is a ‘random’ sentence. WordPiece tokenization is applied next, followed by MLM. Adam (1e-4) is the optimization objective, and the GELU activation function is used, rather than the standard RELU, following the approach of OpenAI GPT (Radford et al., 2018). Training loss is the sum of mean MLM likelihood, and mean sentence prediction likelihood.
Two sizes of BERT are used: ‘BERT-base,’ which has an identical model size to current state-of-the-art OpenAI GPT to allow for comparison, and ‘BERT-large,’ which is larger in size, and shows the true potential of BERT. The two sizes can be seen below:

NOTE: Number of attention heads is a Transformer specific parameter.
The use of pre-trained language models has been found to significantly improve results, compared to training from scratch, for many NLP tasks at both the sentence level (e.g. Question Answering, Machine Translation) and the token level (e.g. Name Entity Recognition, Parts of Speech Tagging). A pre-trained language model can be applied to downstream tasks using two approaches: a feature-based approach or a fine-tuning approach. The feature-based approach uses the learned embeddings of the pre-trained model as a feature in the training of the downstream task. In contrast, the fine-tuning approach (which BERT focuses on) re-trains the pre-trained model on that downstream task, using a minimal number of task-specific parameters. In any case, the more the model can generalize to solve a variety of downstream tasks with the least re-training, the better. We describe the specifics of BERT’s fine-tuning approach below.
Fine-tuning Procedure
The fine-tuning procedure follows the pre-training step, and in particular refers to the fine-tuning of downstream NLP tasks. In this procedure, a classification layer is added that computes the label probabilities using the standard softmax. The parameters for this classification are the only parameters that are added at this point. The parameters from BERT and the added classification layer are then jointly fine-tuned. Other than batch size, learning rate, and number of training epochs, all the hyperparameters are the same as during pre-training.
Pushing the Envelope over Uni-directionality
BERT is the first language representation model that exploits deep bi-directionality in text when pre-training the model. By taking in the entire input sequence at once, it allows pre-training on the text to use the context from both sides of the input sequence: left to right, and right to left. This approach provides a more contextual training of the language representation than previous models, such as ELMo (Peters et al., 2018) and OpenAI GPT. OpenAI GPT uses the traditional unidirectional approach, while ELMo independently trains language models from left to right, and right to left, and then concatenates the two into a single model. Bi-directionality in the true sense, is the second key contribution of BERT.
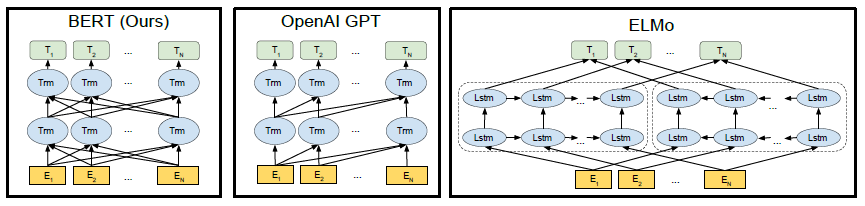
Figure 1: Pre-training model architectures. BERT is the only model that uses a bidirectional Transformer (Devlin et al., 2018)
Ablation Studies
To isolate the specific improvements enabled by BERT, compared to previous work, ablation studies on BERT’s pre-training tasks, model size, number of training steps, etc. were conducted. Readers interested in the isolated contributions of individual components of BERT can refer to the paper for more details.
Results of Experiments
The results of BERT fine-tuning on 11 NLP tasks are presented. Eight of these tasks are part of the GLUE Datasets (General Language Understanding Evaluation, Wang et al., 2018), while the remaining are from SQuAD, NER, and SWAG. From an NLP viewpoint, these 11 tasks are diverse and cover a broad array of problems, as depicted in the table below. The task-specific models are formed by incorporating only a single additional layer to BERT, so a minimal number of parameters are to be learned from scratch. Generally speaking, the input representation for the task-specific models (GLUE, SQuAD, SWAG) is formed in a manner similar to BERT’s training. That is, each input sequence is packed to form a single sequence, regardless of its composition (sentence-sentence pair, question-paragraph pair, etc.), and then BERT’s artifacts, i.e. embeddings A & B, special tokens [CLS] and [SEP], etc. are fed into the newly added layer.
The table below provides a brief description of the 11 NLP tasks that BERT tests on:


The results of these tasks show that BERT performs better than the state-of-the-art OpenAI GPT in all tasks, albeit marginally in some cases. In the case of GLUE, BERT-base and BERT-large obtain a 4.4% and 6.7% average accuracy improvement, respectively, over the state-of-the-art. For SQuAD, BERT’s best performing system tops the leaderboard system by a difference of +1.5 F1 score in ensembling, and +1.3 F1 score as a single system. For SWAG, BERT-large outperforms the baseline ESIM+ELMo system by +27.1%. For NER, BERT-large outperforms the existing SOTA, Cross-View Training with multi-task learning (Clark et al., 2018), by +0.2 on CoNLL-2003 NER Test.
Conclusion
As with other areas of machine learning, development of superior pre-trained language models is a work in progress. BERT, with its deep bidirectional architecture and novel pre-training tasks, is an important advancement in this area of NLP research. Future research could explore improvements such as further reducing downstream training, and expanding to broader NLP applications than BERT.
Original. Reposted with permission.
Related:
- Large-Scale Evolution of Image Classifiers
- Interpolation in Autoencoders via an Adversarial Regularizer
- GANs Need Some Attention, Too