We Created a Lazy AI
This article is an overview of how to design and implement reinforcement learning for the real world.
By Ian Xiao, Engagement Lead at Dessa

TLDR: Many articles explain the concepts of Reinforcement Learning (RL), but not many discuss how to actually design and implement one for the real world. In this article, I will share a paradigm-shifting lesson from implementing an RL solution for the city of New York, some insights, and a generalizable Reference Architecture.
Like What You Read? Follow me on Medium, LinkedIn, or Twitter.
Credits: Thanks to Alex Shannon, Prince Abunku, and Breton Arnaboldi, my amazing teammates at NYU, for contributing and making this happen.
But, Drinks First?
Imagine you are at a party. You are a bit (or very) drunk. You volunteer to play a drinking game to impress an (or multiple) attractive acquaintances.
Someone blindfolds you, gives you a glass and a bottle of beer, and shouts: “Start pouring!”
What would you do?
You probably have the following reactions: sh*t, what am I supposed to do!? how do I win!? what happens if I lose!?
It turns out that the rule is this: you need to fill the beer as close to a mark on the glass as possible in 10 seconds. You can pour beer in and out.
Welcome to the mind of our RL solution who faces a similar task, but for a nobler and meaningful purpose.
The Beer Problem in the Real World
There is a big problem in our eco-friendly bike-sharing businesses. Throughout the day, each bike station (the glass) can have too little or too many bikes (the beer).

This is very inconvenient for bikers and costs millions of dollars to manage the operation. A while ago, my team at NYU was tasked to come up with an AI solution to help manage the bike stocks with minimum human intervention.
The objective: keep the stock at each bike station between 1 and 50 throughout the day (think about the mark on the glass). This is known as the Rebalancing Problem in the sharing economy.
The constraints: because of operation limitations, teams can only move 1, 3, or 10 bikes in each hour of the day (the amount of beer you can pour in or out). Of course, they can choose to not do anything. The more bikes the team moves, the more expensive it is.
Our Lazy RL Solution
We decided to use RL because it overcomes many limitations of traditional methods (e.g. Rule-based and Forecasting).
If you want to catch up on what RL is and some of its key concepts, Jonathan Hui wrote a very good introduction and Thomas Simonini explained Q-Learning, an RL algorithm used in our solution, in more detail.
It turns out, we created a very lazy AI. When bike stock gets over ~60, it would often choose to do nothing or the minimal (move 1 or 3 bikes). It seems counter-intuitive, but it’s quite wise.
According to human intuitions, we might move as many bikes as possible to keep it under 50, especially when the stations are getting full. But, the RL recognized the cost of moving bikes (the more bikes it moves, the more it costs) and the chances of succeeding under certain situations. Given how much time is left, it’s simply impossible to meet the objective. It knows the best option is to “give up”. So, sometimes it’s better to give up than keep trying.
There are different ways to “nudge” the AI to avoid being lazy. It has to do with how we design the reward functions. We will cover this in the next article, so read on for now.
So what? Similar to the famous Move 37 and 78 by Google’s Alpha Go, when AI makes unconventional decisions, they challenge our biases, help break the curse of knowledge, and nudge us toward an uncharted path.
Creating AI is as much a journey of discovery into the inner workings of our own minds as it is an invention. — Demis Hassabis, Founder of DeepMind, The World in 2020 on the Economist
But, be cautious. Nothing should replace human value systems so we don’t fall off the cliff or get lost.
Let’s Get Real
How does the RL manage a Bike Station? The following graph shows how bike stock changes from hour 0 to 23 with and without RL.
- Blue is the trend of bike stock without RL.
- Yellow is with a naive RL. It simply keeps removing bikes. It’s costly.
- Green is with a better trained RL. It removes just enough bikes to meet the objective. It’s more conscious of the cost.

How does the RL decide what to do? The following is a snapshot of the Q Table of our RL solution after 98,000 training episodes. It explains how our RL decides what to do (horizontal) given how many bikes there are at a station (verticle). The RL is unlikely to choose to do anything in red. Take a look at the bottom red area.
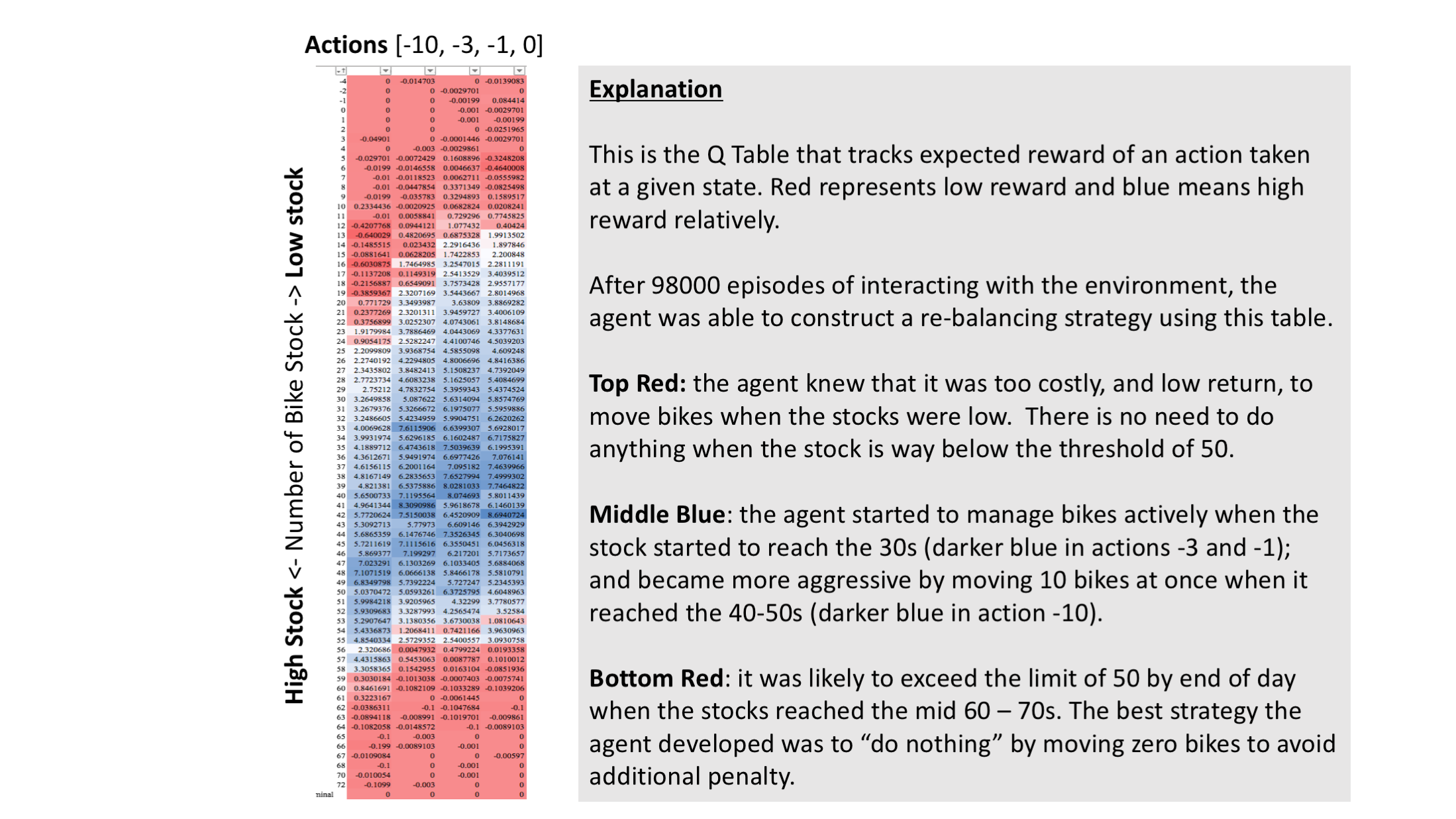
How smart can the RL become? The following looks at how well the RL manages a bike station. With more learning, the RL is able to improve the overall success rate gradually to an impressive 98%.

This looks awesome, how does our solution work? Here is a high-level architecture. This is a generalizable design for most of the RL applications. Each RL solution needs to have the following three basic components: a Training Loop, an Agent, and an Environment.
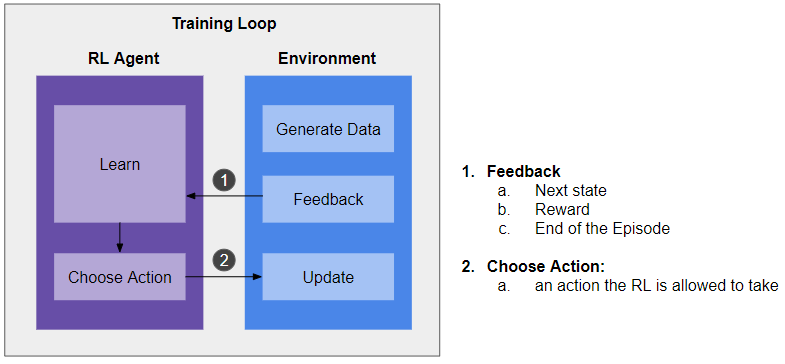
The Training Loop: the loop facilitates the running of episodes. Each episode means an end to end process of an event (in this case, it means the start and end of a round of treasure hunt). The program can run thousands of episodes (or as many as you want) to train the RL agent.
The RL Agent: the RL agent has two main capabilities. Learning allows the agent to learn from each interaction with the environment and carries the learning to a new episode. There are different designs of the “brain”. The simplest is by using Q Learning. Alpha Go uses a Deep Neural Network. The agent chooses an action based on the learning and a situation provided by the environment.
The Environment: this is a representation of the world given the application. In our case, it’s the way bikes move in the city. The environment provides feedback based on the actions of the agent. Feedback includes rewards or penalties and the updated state of the environment. We will discuss this in more detail shortly.
What’s Next
I hope you enjoy this post and you are excited about the capability and potential of RL in the real world. Depends on how this article does, we will deep dive into the design, trade-offs, and do a detailed code walkthrough in the next article.
In the meanwhile, if you are want to learn more about the basics of developing RL, check out my new RL tutorial. We will make a fun treasure hunt program in about 100 lines of code, get familiar with the general RL architecture discuss above, and build a demo-ready portfolio.
Like What You Read? Follow me on Medium, LinkedIn, or Twitter.
Until Next Time.
Ian
Like what you read? You may also like these popular articles of mine:
Data Science is Boring
How I cope with the boring days of deploying Machine Learning
The Last Defense against Another AI Winter
The numbers, five tactical solutions, and a quick survey
The Last-Mile Problem of AI
One Thing Many Data Scientists Don’t Think Enough About
A Doomed Marriage of ML and Agile
Sebastian Thrun, the founder of Udacity, ruined my ML project and wedding
Bio: Ian Xiao is Engagement Lead at Dessa, deploying machine learning at enterprises. He leads business and technical teams to deploy Machine Learning solutions and improve Marketing & Sales for the F100 enterprises.
Original. Reposted with permission.
Related:
- The Last Defense Against Another AI Winter
- Data Science is Boring (Part 1)
- Data Science is Boring (Part 2)