 Microsoft Introduces Project Petridish to Find the Best Neural Network for Your Problem
Microsoft Introduces Project Petridish to Find the Best Neural Network for Your Problem
 Microsoft Introduces Project Petridish to Find the Best Neural Network for Your Problem
Microsoft Introduces Project Petridish to Find the Best Neural Network for Your ProblemThe new algorithm takes a novel approach to neural architecture search.
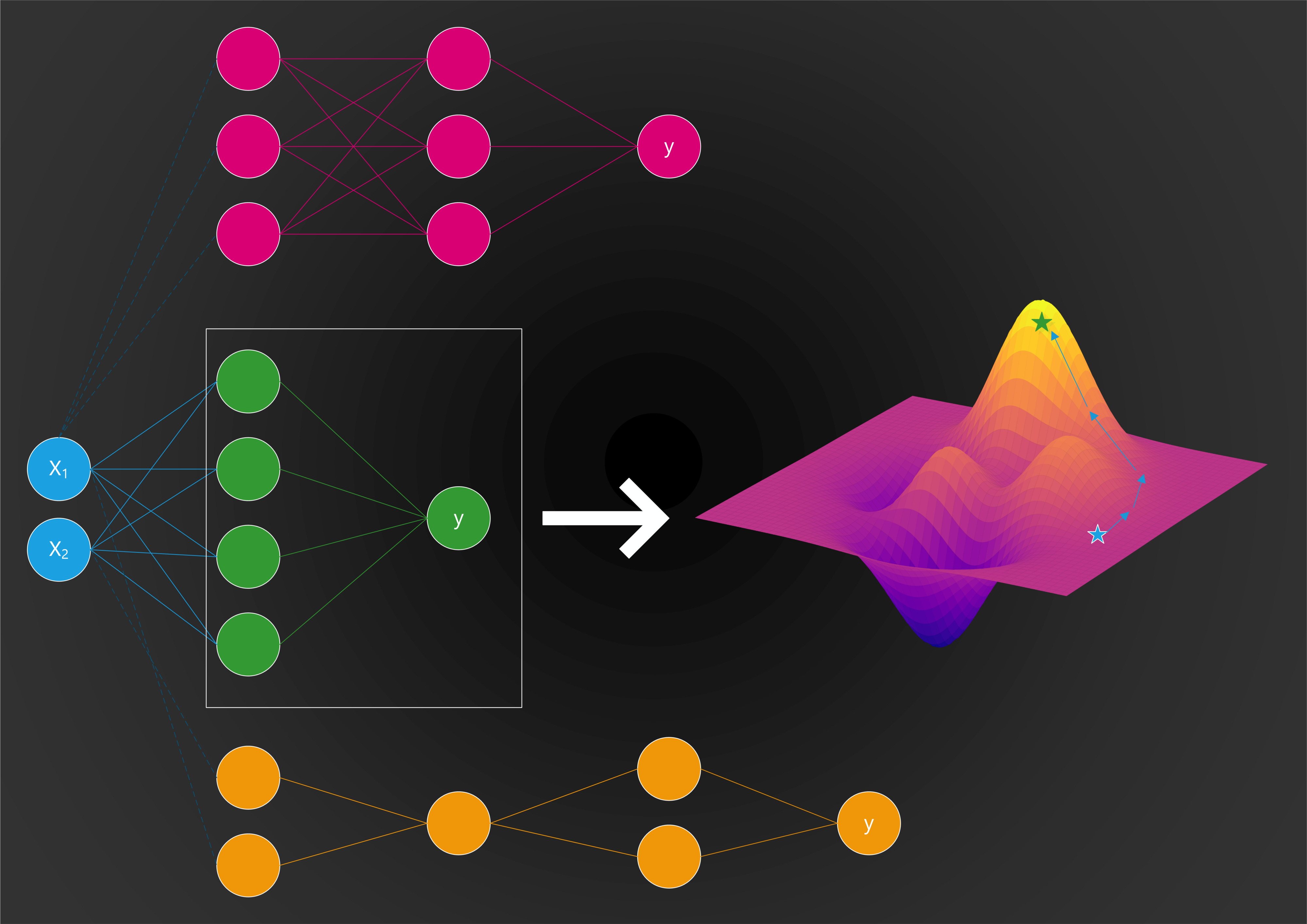
Neural architecture search(NAS) is one of the hottest trends in modern deep learning technologies. Conceptually, NAS methods focus on finding a suitable neural network architecture for a given problem and dataset. Think about it as making machine learning architecture a machine learning problem by itself. In recent years, there have been an explosion in the number of NAS techniques that are making inroads into mainstream deep learning frameworks and platforms. However, the first generation of NAS models have encountered plenty of challenges adapting neural networks that were tested on one domain to another domain. As a result, the search for new NAS techniques is likely to continue driving new innovations in the space. Recently, Microsoft Research unveiled Petridish, a NAS algorithm to optimize the selection of neural network architectures.
NAS exists because the process of designing neural networks is incredibly resource consuming. In the current deep learning ecosystem, relying on well-known, top-performing networks provides few guarantees in a space where your dataset can look very different from anything those proven networks have encountered before. In many cases, NAS methods often takes hundreds of GPU-days to find good architectures, and can be barely better than random search. There is another problem in machine learning that resembles the challenges of NAS techniques: feature selection.
Just like NAS methods, feature selection algorithms need to extract relevant features for a model given a specific dataset. Obviously, selecting a feature is drastically simpler than a neural network architecture but many of the principle of feature selection techniques served as inspiration to the Petridish team.
A Brief History of NAS
Given the recent popularity of NAS methods, many might think that NAS is a recent discipline. It is unquestionable that NAS has experienced a renaissance since 2016 with the publication of Google’s famous paper on NAS with reinforcement learning. However, many of its origin trace back to the late 1980s. One of the earlies NAS papers was the 1988 “Self Organizing Neural Networks for the Identification Problem”. From there, the space saw a handful of publication outlining interesting techniques but it wasn’t until the Google push that NAS got the attention of the mainstream machine learning community. If you are interested in the publication history of NAS methods, the AutoML Freiburg-Hannover website provides one of the most complete compilations up to this day.
The Two Types of NAS: Forward Search vs. Backward Search
When exploring the NAS space, there are two fundamental types of techniques: backward-search and forward-search. Backward-search methods have been the most common approach for implementing NAS methods. Conceptually, backward-search NAS methods, starts with a super-graph that is the union of all possible architectures, and learns to down-weight the unnecessary edges gradually via gradient descent or reinforcement learning. While such approaches drastically cut down the search time of NAS they have a major limitation in the case that they require human domain knowledge is needed to create a supergraph in the first place.
Forward-search NAS methods try to grow neural network architectures from small to large. This approach resembles many of the principles of feature selection algorithms in deep learning models. Unlike backward approaches, forward methods do not need to specify a finite search space up front making them more general and easier to use when warm-starting from prior available models and for lifelong learning.
Petridish
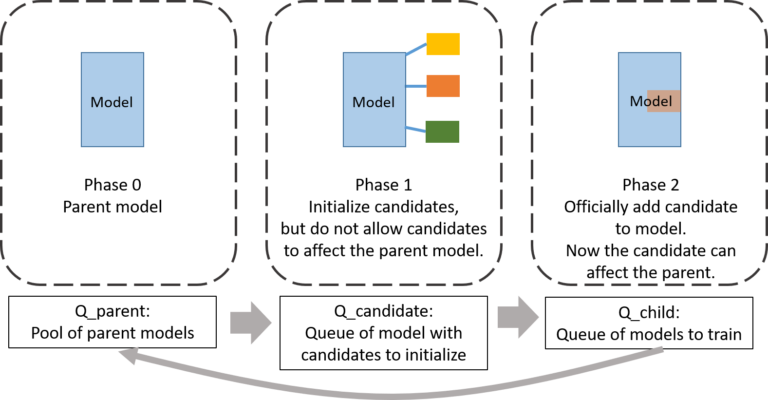
Petridish is a forward-search NAS method inspired by feature selection and gradient boosting techniques. The algorithm works by creating a gallery of models to choose from as its search output and then incorporating stop-forward and stop-gradient layers to more efficiently identify beneficial candidates for building that gallery, and uses asynchronous training.
The Petridish algorithm can be broken down in three fundamental phases:
- PHASE 0: Petridish starts with some parent model, a very small human-written model with one or two layers or a model already found by domain experts on a dataset.
- PHASE 1: Petridish connects the candidate layers to the parent model using stop-gradient and stop-forward layers and partially train it. The candidate layers can be any bag of operations in the search space. Using stop-gradient and stop-forward layers allows gradients with respect to the candidates to be accumulated without affecting the model’s forward activations and backward gradients. Without the stop-gradient and stop-forward layers, it would be difficult to determine which candidate layers are contributing what to the parent model’s performance and would require separate training if you wanted to see their respective contributions, increasing costs.
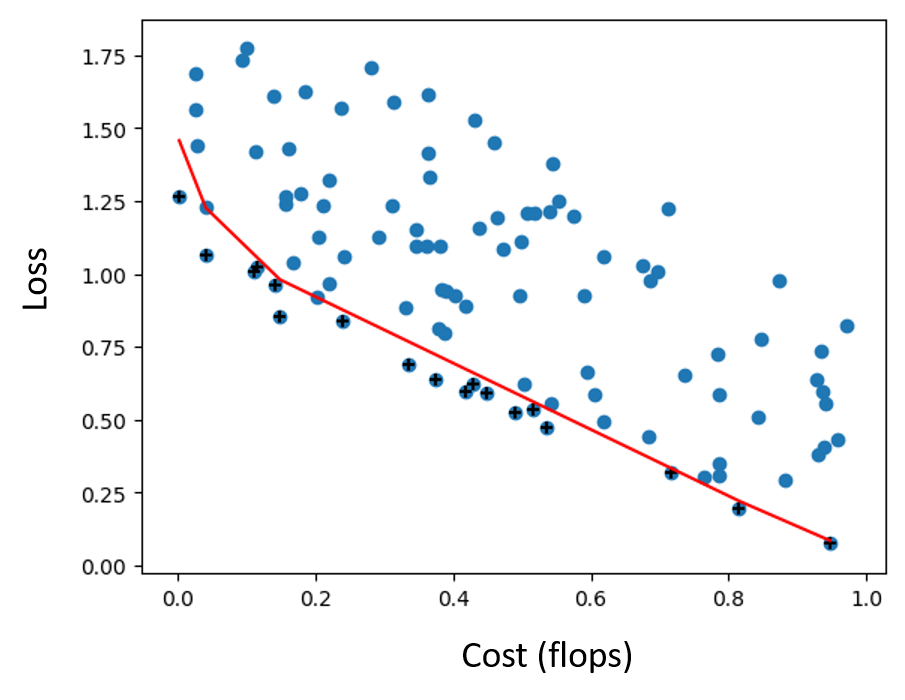
- PHASE 2: If a particular candidate or set of candidates is found to be beneficial to the model, then we remove the stop-gradient and stop-forward layers and the other candidates and train the model to convergence. The training results are added to a scatterplot, naturally creating an estimate of the Pareto frontier.
The incorporation of the Pareto frontier is an interesting addition to Petridish that allow researchers to more easily determine the architecture that achieves the best combination of properties they’re considering for a particular task. The estimate of the Pareto frontier makes it easier to see the tradeoff between accuracy, FLOPS, memory, latency, and other criteria. In the following figure, the models along the Pareto frontier (red line) make up the search output, a gallery of models from which researchers and engineers can choose.
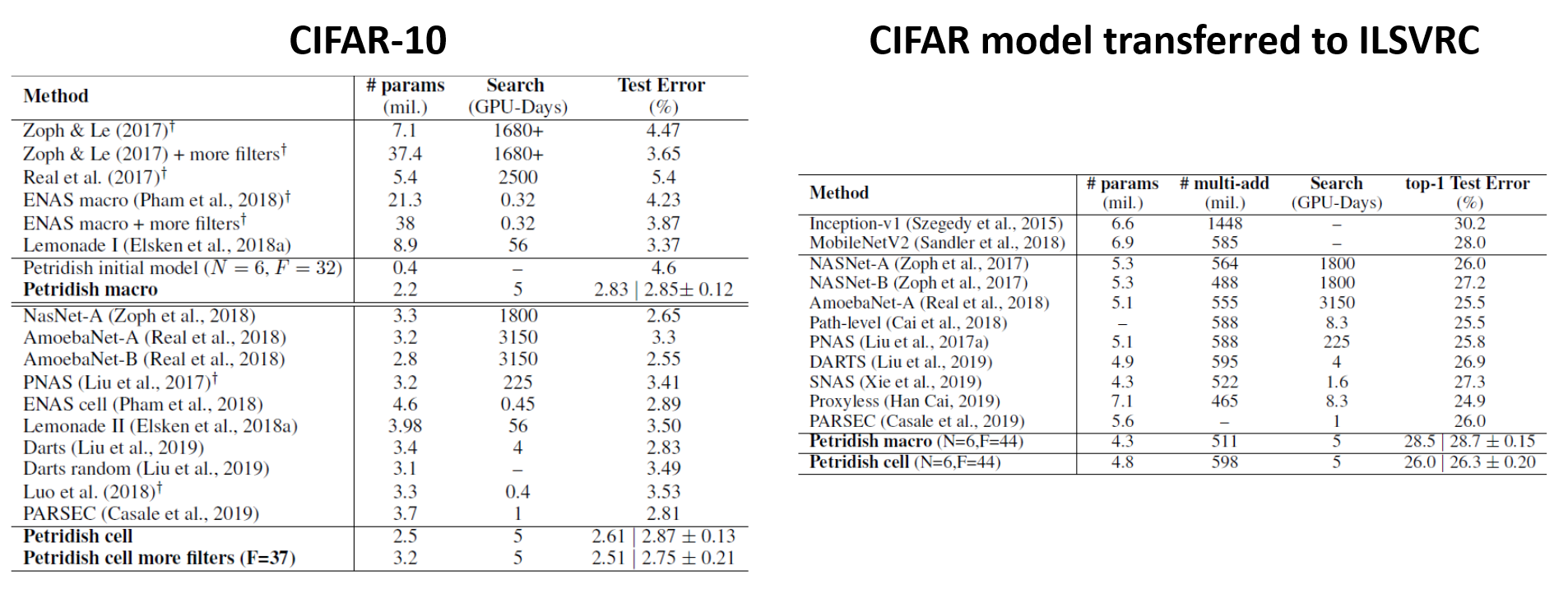
Microsoft Research evaluated Petridish across different NAS benchmarks. Specifically, Petridish was tested on image classification models using the CIFAR-10 dataset and then transferring the results to ImageNet. On CIFAR-10, Petridish achieves 2.75 ±0.21 percent average test error, with 2.51 percent as the best result, using only 3.2M parameters and five GPU days of search time on the popular cell search space. On transferring the models found on CIFAR-10 to ImageNet, Petridish achieves 28.7 ±0.15 percent top-1 test error, with 28.5 percent as the best result, using only 4.3M parameters on the macro search space. The initial tests were able to outperform state of the art NAS methods while maintaining viable levels of computing cost.
Petridish is an interesting addition to the fast growing ecosystem of NAS techniques. The fact that Petridis relies on forward-searching models makes it even more intriguing as most popular NAS methods relied on backward-search techniques. Microsoft already includes NAS models as part of its Azure ML platform so it would be interesting is Petridish becomes part of that stack.
Original. Reposted with permission.
Related:
- Microsoft Introduces Icebreaker to Address the Famous Ice-Start Challenge in Machine Learning
- Automated Machine Learning: How do teams work together on an AutoML project?
- Uber Creates Generative Teaching Networks to Better Train Deep Neural Networks