Microsoft Introduces Icebreaker to Address the Famous Ice-Start Challenge in Machine Learning
The new technique allows the deployment of machine learning models that operate with minimum training data.

The acquisition and labeling of training data remains one of the major challenges for the mainstream adoption of machine learning solutions. Within the machine learning research community, several efforts such as weakly supervised learning or one-shot learning have been created in order to address this issue. Microsoft Research recently incubated a group called Minimum Data AI to work on different solutions for machine learning models that can operate without the need of large training datasets. Recently, that group published a paper unveiling Icebreaker, a framework for “wise training data acquisition” which allow the deployment of machine learning models that can operate with little or no-training data.
The current evolution of machine learning research and technologies have prioritized supervised models that need to know quite a bit about the world before they can produce any relevant knowledge. In real world scenarios, the acquisition and maintenance of high quality training datasets results quite challenging and sometimes impossible. In machine learning theory, we refer to this dilemma as the ice(cold)-start problem.
Knowing What You Don’t Know: The Ice-Start Challenge in Machine Learning
The ice-start problem/dilemma refers to the amount of training data required to make machine learning models effective. Technically, most machine learning agents need to start with a large volume training dataset and start regularly decreasing its size during subsequent training runs until the model has achieved a desired level of accuracy. The ice-start challenge refers to the ability of the model to operate effectively in the absence of a training dataset.
The solution to the ice-start problem can be described using the popular phrase “knowing what you don’t know”. In many situations in life, understanding the missing knowledge in a current context has proven to be equally or more important than the existing knowledge. Statistic nerds often refer to a famous anecdote of World War II to illustrate this dilemma.
During World War II, the Pentagon assembled a team of the country’s most renown mathematicians in order to develop statistical models that could assist the allied troops during the war. The talent was astonishing. Frederick Mosteller, who would later found Harvard’s statistics department, was there. So was Leonard Jimmie Savage, the pioneer of decision theory and great advocate of the field that came to be called Bayesian statistics. Norbert Wiener, the MIT mathematician and the creator of cybernetics and Milton Friedman, future Nobel prize winner in economics were also part of the group. One of the first assignments of the group consisted of estimating the level of extra protection that should be added to US planes in order to survive the battles with the German air force. Like good statisticians, the team collected the damage caused to planes returning from encounters with the Nazis.
For each plane, the mathematicians computed the number o bullet holes across different parts of the plane (doors, wings, motor, etc). The group then proceeded to make recommendations about which areas of the planes should have additional protection. Not surprisingly, the vast majority of the recommendations focused on the areas with that had more bullet holes assuming that those were the areas targeted by the German planes. There was one exception in the group, a young statistician named Abraham Wald who recommended to focus the extra protection in the areas that hadn’t shown any damage in the inventoried planes. Why? very simply, the young mathematician argued that the input data set( planes) only included planes that have survived the battles with the Germans. Although severe, the damage suffered by those planes was not catastrophic enough that they couldn’t return to base. therefore, he concluded that the planes that didn’t return were likely to have suffered impacts in other areas. Very clever huh?
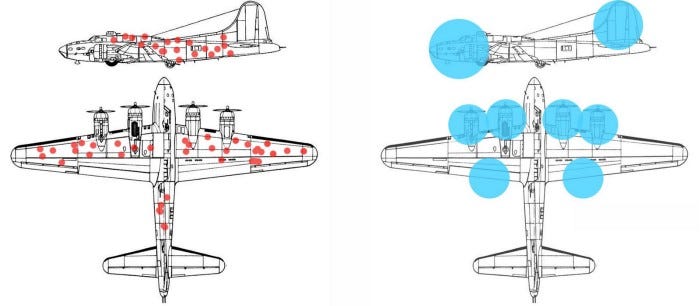
What this lesson teaches us is that understanding the missing data in a given context is as important as understanding the existing data. Extrapolating that to machine learning models, the key to address the ice-start problem is to have a scalable model that knows what it does not know, namely to quantify the epistemic uncertainty. This knowledge can be used to guide the acquisition of training data. Intuitively, unfamiliar, but informative features are more useful for model training.
Icebreaker
Microsoft Icebreaker is a novel solution to part of the ice-start challenge. Conceptually, Icebreaker relies on deep generative model that minimizes the amount and cost of data required to train a machine learning model. From an architecture standpoint, Icebreaker employs two components. The first component is a deep generative model (PA-BELGAM), shown in the top half of the model above, which features a novel inference algorithm that can explicitly quantify epistemic uncertainty. The second component is a set of new element-wise training data selection objectives for data acquisition, shown in the bottom half of the model.
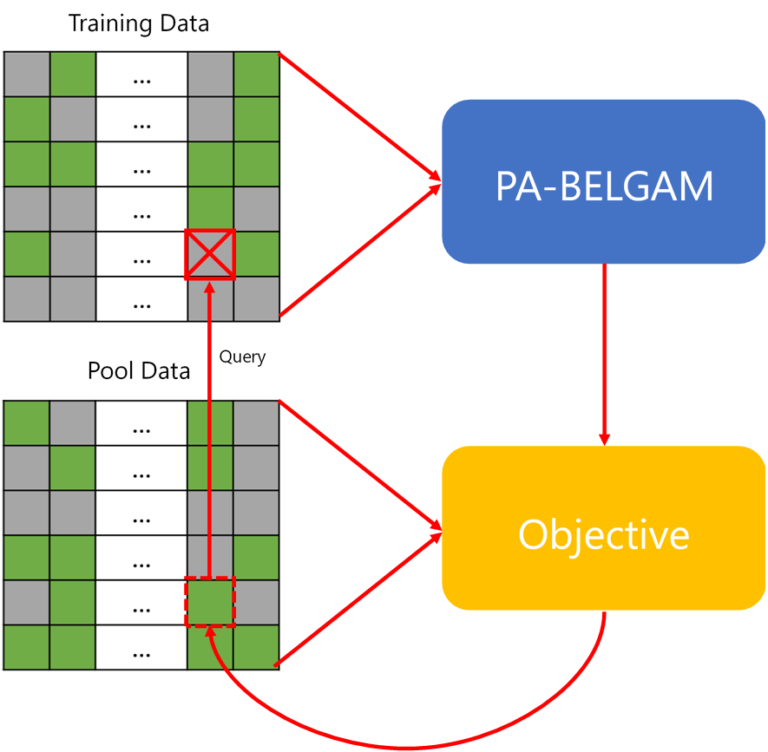
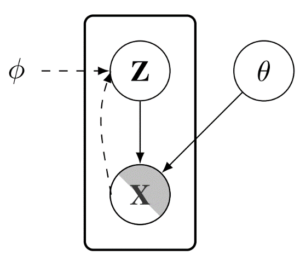
The core of Icebreaker is the PA-BELGAM model. This model is based on a version of a variational autoencoder that is able to manage missing elements and decoder weights. Instead of using a standard deep neural network as the decoder to map data from a latent representation, Icebreaker uses a Bayesian neural network, and we put a prior distribution over the decoder weights.
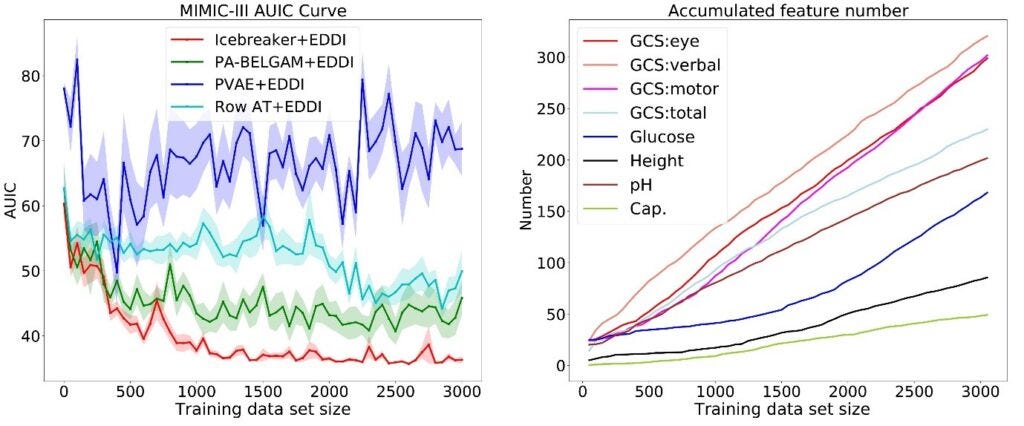
Microsoft evaluated Icebreaker across different datasets of different sizes. The model showed relevant improvements compared to state of the art models as shown in the following figure. The chart on the left that Icebreaker performs better than several baselines, achieving better test accuracy with less training data. The graph on the right shows the number of data points for eight features as the total size of our data set grows.
Microsoft Icebreaker is an innovative model to enable the deployment of machine learning models that operate with little or no-data. By leveraging novel statistical methods, Icebreaker is able to select the right features for a given model without requiring a large dataset. Microsoft Research open sourced an early version of Icebreaker that complements the research paper.
Original. Reposted with permission.
Related:
- The Rise of User-Generated Data Labeling
- This Microsoft Neural Network can Answer Questions About Scenic Images with Minimum Training
- Facebook Has Been Quietly Open Sourcing Some Amazing Deep Learning Capabilities for PyTorch