This Microsoft Neural Network can Answer Questions About Scenic Images with Minimum Training
Recently, a group of AI experts from Microsoft Research published a paper proposing a method for scene understanding that combines two key tasks: image captioning and visual question answering (VQA).

Understanding the world around us via visual representations of it is one of the magical cognitive skills of the human brain. In some context, the brain can be considered this giant engine that constantly processes visual signals, extracts the relevant knowledge and triggers the corresponding actions. Although we don’t quite yet understand how our brain forms fragments of knowledge from visual representations, the processes are embedded in our education methodologies. When we show a picture of a flower to a baby and tell him it’s a rose, that’s probably enough for the baby to start recognizing roses in the real world, whether they are in a vase or in a garden, one or many, red or white. At the same time is able to answer all sorts of questions related to roses. Our brain has a magical ability to generalize information from visual images and articulate those concepts via language. Recreating that level of scene understanding in artificial intelligence(AI) models has been an active area of research in the deep learning space for the last few years. Recently, a group of AI experts from Microsoft Research published a paper proposing a method for scene understanding that combines two key tasks: image captioning and visual question answering (VQA).
Scene understanding for deep learning models is a monumentally challenging task that involves many moving parts. If you think about it, we are talking about models that will take an image as an input and not only learn relevant concepts in it but associated them with language constructs in a robust enough way to be able to answer questions about the image. Typically, this process requires massive amounts of labeled data to understand the different objects present in a picture. However, that task is simply unmanageable to scale. From that perspective, the challenge of scene understanding models is not only the sophistication of the deep learning architecture but the challenge of minimizing the volume of labeled data needed during the training process.
A silver lining in this whole equation is the fact that the internet is full of text image pairs that describe the characteristics of specific scenes. The question then becomes, whether it would be possible to leverage the large amount of image-text pairs available on the web to mimic the way people improve their scene and language understanding. Can we build deep learning models that unifies machine capabilities to perform well on both vision-language generation tasks and understanding tasks?
Enter Microsoft Unified VLP
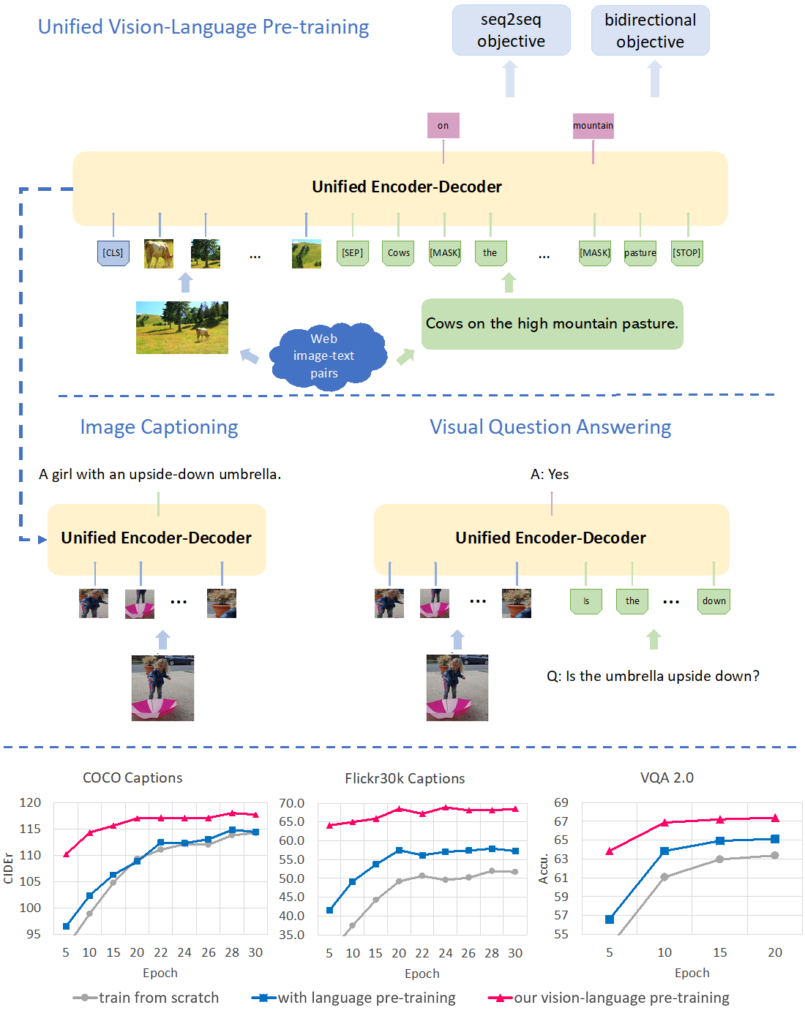
In the paper “Unified Vision-Language Pre-Training for Image Captioning and VQA”, Microsoft Research presented a deep learning architecture capable of both image captioning and visual question answering(VQA). The unified visual-language pre-training(VLP) model needs to be able to master two highly dissimilar tasks under the same structure. To achieve that, VLP uses a unified encoder-decoder model for general vision-language pre-training. The pre-trained model is fine-tuned for image captioning and visual question answering. More specifically, The VLP model uses a shared multi-layer Transformer network for encoding and decoding, pre-trained on large amounts of image-caption pairs available on the internet, and optimized for two unsupervised vision-language prediction tasks: bidirectional and sequence to sequence (seq2seq) masked language prediction.
If we need to summarize the benefits of the VLP architecture, they can be encapsulated in three key points:
VLP seeks to overcome the above limitations with an architecture that:
- deploys a shared multi-layer transformer network for encoding and decoding;
- is optimized for both bidirectional and sequence-to-sequence prediction; and
- incorporates special masks in a self-attention mechanism to enable a single model performing both generation and understanding tasks over a given scene.
The VLP architecture can be summarized in two main functional areas:
- Visual language transformer network
- Pre-training objectives.
The visual language transformer network unifies the transformer encoder and decoder into a single model. The pretraining objectives follow a similar technique to Google’s famous BERT architecture. In that model, 15% of the input text tokens are first replaced with either a special [MASK] token, a random token or the original token, at random with chances equal to 80%, 10%, and 10%, respectively. Then, at the model output, the hidden state from the last Transformer block is projected to word likelihoods where the masked tokens are predicted in the form of a classification problem. Through this reconstruction, the model learns the dependencies in the context and forms a language model.
VLP’s pretraining architecture is based on an input vector consisting of image, sentence and three special tokens ([CLS], [SEP], [STOP]). The image is processed as N Region of Interests and region features are extracted during the processing. The sentence is tokenized and masked with [MASK] tokens for the later masked language modeling task. Our Unified Encoder-Decoder consists of 12 layers of Transformer blocks, each having a masked self-attention layer and feed-forward module, where the self-attention mask controls what input context the prediction conditions on.
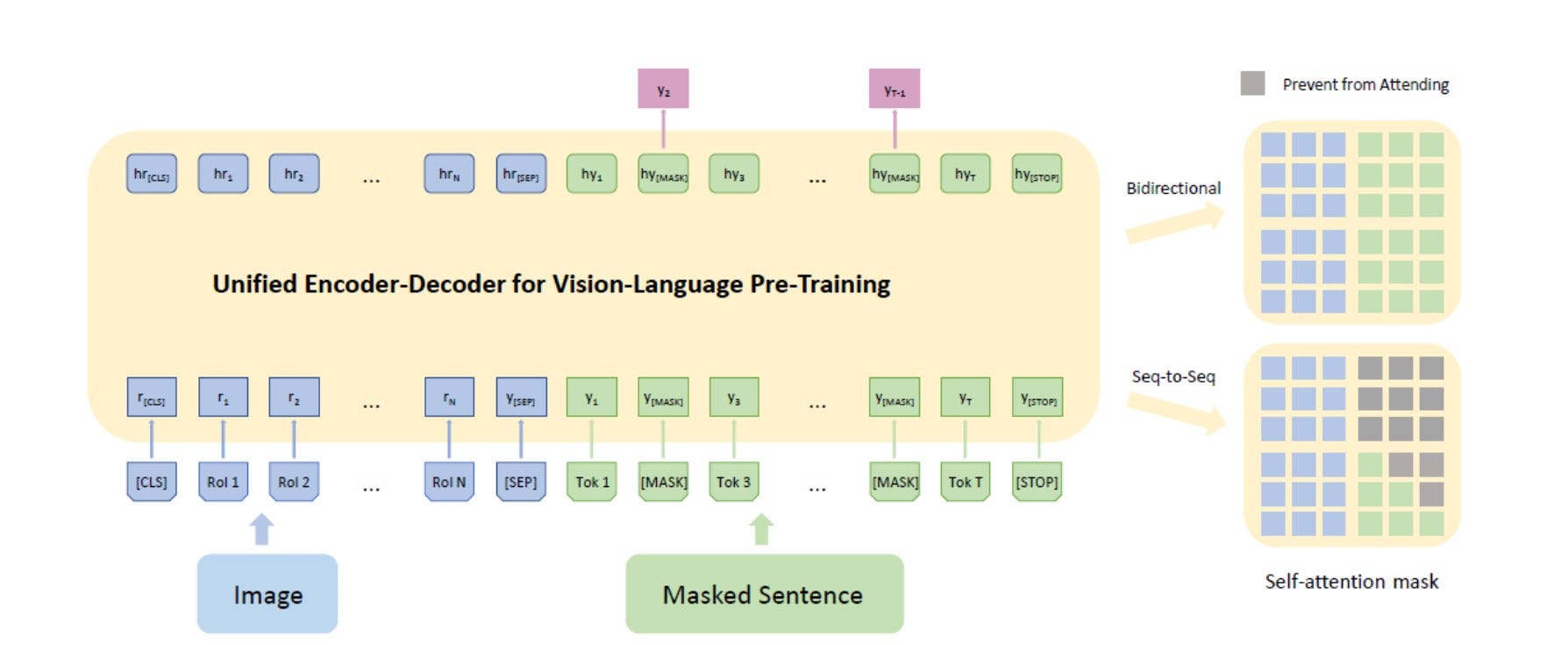
After the initial pretraining, the VLP model is put through different fine-tuning tasks to optimize its image captioning and visual question answering capabilities.
VLP in Action
Microsoft Research evaluated VLP’s ability to reason over images using three different benchmarks: : COCO, Flickr30K, and VQA 2.0. In all three scenarios, VLP was able to outperform state-of-the-art image-language models such as BERT. VLP’s response were not only richer in terms of details and context but the model was also able to answer very challenging questions about images in which other models simply failed. Following some of the details illustrated in the following picture, VLP is able to identify the similarity in clothing design among different people in the first photo and recognizes the person is not taking his own picture in the second photo.

Microsoft’s VLP is one of the first models that combine both vision and language understanding tasks with pretraining models under the same architecture. While these type of multi-modal, unified model seems constrained to research exercises today, they have shown enough potential to be included in mainstream deep learning applications in the near future. Microsoft Research open sourced the first implementation of its VLP model in GitHub which should help AI researchers and data scientists to improve upon it and work on similar ideas.
Original. Reposted with permission.
Related:
- Using Neural Networks to Design Neural Networks: The Definitive Guide to Understand Neural Architecture Search
- OpenAI Tried to Train AI Agents to Play Hide-And-Seek but Instead They Were Shocked by What They Learned
- Recreating Imagination: DeepMind Builds Neural Networks that Spontaneously Replay Past Experiences