 How YouTube is Recommending Your Next Video
How YouTube is Recommending Your Next Video
 How YouTube is Recommending Your Next Video
How YouTube is Recommending Your Next VideoIf you are interested in learning more about the latest Youtube recommendation algorithm paper, read this post for details on its approach and improvements.
By Tim Elfrink, Data Scientist at Vantage AI
In a recent paper [1] published by Google researchers and presented at RecSys 2019 (Copenhagen, Denmark) insight was provided in how their video platform Youtube recommends which videos to watch. In this blogpost I will try to summarise my findings after reading this paper.
The problem
When users are watching videos on Youtube, a list of recommended videos are displayed which the user might like in a certain order. The paper focuses on two objectives:
- Different objectives need to be optimised; the exact objective function is not defined but the objective is split in engagement objectives (clicks, time spend) and satisfaction objectives (likes, dismissals).
- Reduce selection bias that is implicitly introduced by the system as users are, as a result of the position, more likely to click on the first recommendation, even though lower placed videos might yield higher engagement and satisfaction .
How to effectively and efficiently learn to reduce such biases is an open question.
The approach
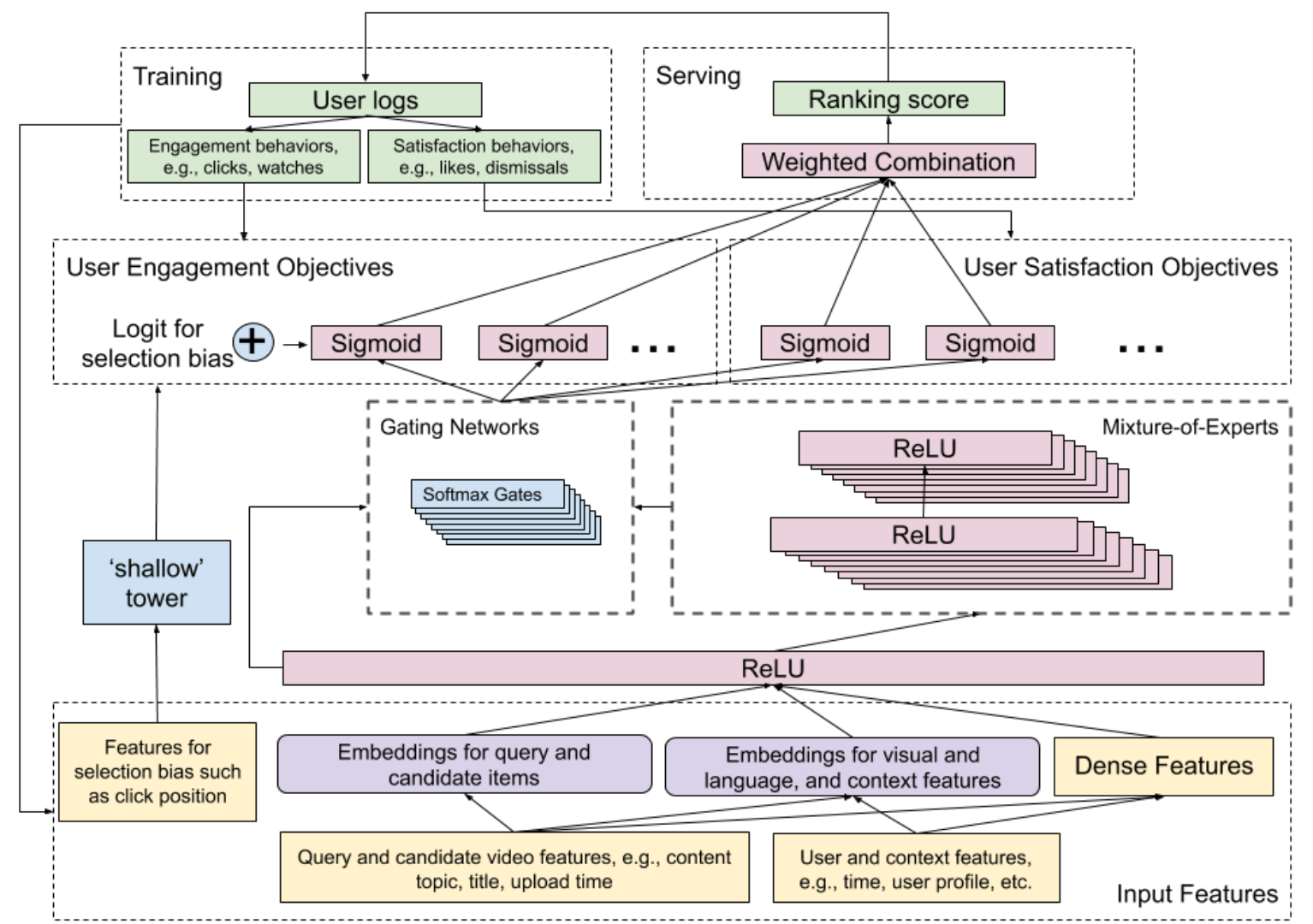
The described model in this paper focuses on the two main objectives. A Wide & Deep [2] model architecture was used which combines the power of a wide model linear model (memorisation) alongside a deep neural network (generalisations). The Wide & Deep model will generate a prediction for each of the defined (both engagement and satisfaction) objectives. The objectives are grouped in binary classification problems (i.e. liking a video or not) and regression problems (i.e. the rating of a video). A separate ranking model is added on top of this model. This is just a weighted combination of an output vector which are the different predicted objectives. These weights are manually tuned to achieve the best performance of the different objectives. Advanced methods are proposed such as pairwise or listwise approaches to boost performance, but they are not implemented into production due to the increasing computation time.
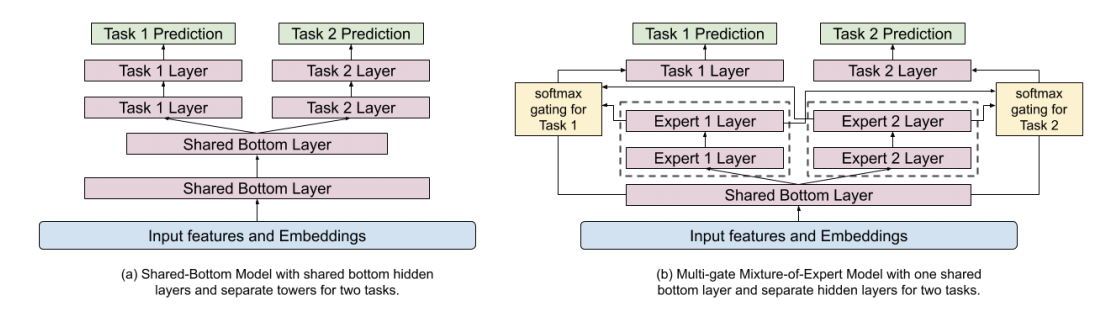
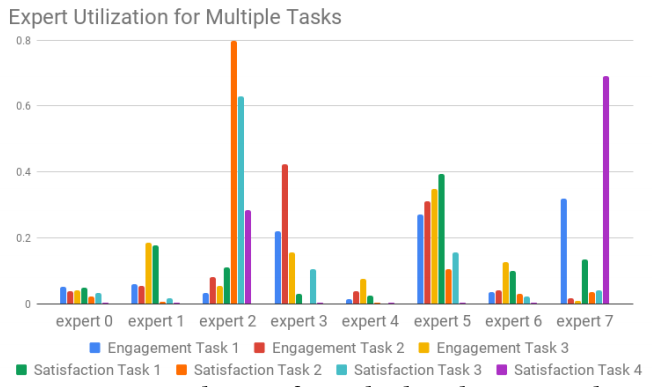
In the deep part of the Wide & Deep model a Multi-gate Mixture of Experts (MMoE) [3] model is adopted. Features of the current video (Content, title, topic, upload time, etc.) and the user that is watching (time, user profile, etc.) are used as input. The concept behind the MMoE model is based on efficiently sharing weights over different objectives. The shared bottom layer is split into multiple experts which all are used for predicting the different objectives. For every objective there is a gate function. This gate function is a softmax function which has input of the original shared layer and the different expert layers. This softmax function will determine which expert layers are important for the different objectives. As you can see in figure 3, different experts are more important for different objectives. Training in the MMoE model is less affected if the difference objectives have a low correlation compared to models with a shared-bottom architecture.
The wide part of the model is focusing on reducing the selection bias in the system introduced by the position of the recommended videos. This wide part is referred to as a “shallow tower” which can just be a simple linear model that is using simple features as the position videos got clicked on and the device that is used to watch the video. The output of the shallow tower is combined with the output of the MMoE model which is the key component of the Wide & Deep model architecture. In this way the model will focus more on the position of the video. During training a dropout rate of 10% is used to prevent the position feature to become too important in the model. If you would not use the Wide & Deep architecture and add the position as a single feature the model might not focus on that feature at all.
The results
The result of this paper demonstrate that replacing shared-bottom layers with MMoE is increasing the performance of the model for both engagement (time spent watching recommended videos) and satisfaction (survey responses). Increasing the number of experts in the MMoE and and number of multiplications further boost performance of the model. Due to computational limitations this number cannot be increased in a live setup.

Further results show that the engagement metric is improved by reducing the selections bias as a result of using the shallow tower. This is a significant improvement in comparison with just adding the input features in the MMoE model.

Interesting remarks
- Although Google has a great infrastructure for computation they still need to be careful about training and serving cost.
- By using a wide and deep model you can design a network that predefines some features that are important to you.
- MMoE models can be efficient when you need a model with multi-objectives.
- Even when having a great and complex model architecture, humans are still manually adjusting the weights in the last layer which determines the actual ranking based on the different objective predictions.
About the author
Tim Elfrink is a data scientist at Vantage AI, a data science consultancy company in the Netherlands. If you need help creating machine learning models for your data, feel free to contact us at info@vantage-ai.com.
Resources
[1] Original paper: https://dl.acm.org/citation.cfm?id=3346997
[2] Explanation of how Wide Deep learning works: https://ai.googleblog.com/2016/06/wide-deep-learning-better-together-with.html
[3] Explanation of MMoE with video: https://www.kdd.org/kdd2018/accepted-papers/view/modeling-task-relationships-in-multi-task-learning-with-multi-gate-mixture-
Original. Reposted with permission.
Related:
- An Easy Introduction to Machine Learning Recommender Systems
- How to build an API for a machine learning model in 5 minutes using Flask
- Order Matters: Alibaba’s Transformer-based Recommender System