Uber Creates Generative Teaching Networks to Better Train Deep Neural Networks
The new technique can really improve how deep learning models are trained at scale.

A common analogy in artificial intelligence(AI) circles is that training data is the new oil for machine learning models. Just like the precious commodity, training data is scarce and hard to get at scale. Supervised learning models reign supreme in today’s machine learning ecosystem. While these type of models are relatively easy to create compare to other alternatives, they have a strong dependency in training data that results prohibited for most organizations. This problem becomes bigger with the scale of the machine learning models. Recently, Uber engineers published a paper proposing a new method called Generative Teaching Networks(GTNs) that create learning algorithms that automatically generate training data.
The idea of generating training data using machine learning is not exactly novel. Techniques such as semi-supervised and omni-supervised learning rely on that principle to operate in data scarce environments. However the data-dependency challenges in machine learning models are growing faster than the potential solutions. Part of these challenges have their roots in some of the biggest misconceptions in modern machine learning.
Misconceptions About Training Data
The traditional approach to train a machine learning model tells us that models should be trained using large datasets and they should leverage the entire dataset during the process. Although well established, that idea seems counterintuitive as it assumes that all records in the training dataset have equal weight which is certainly rare. New approaches such as curriculum learning and active learning have focused on extracting a distribution from the training dataset based on the examples that generate the best version of the models. Some of these techniques have proven quite useful in the emergence of neural architecture search(NAS) techniques.
NAS are becoming one of the most popular trends in modern machine learning. Conceptually, NAS help to discover the best high performing neural network architectures for a given problems by performing evaluations across thousands of models. The evaluations performed by NAS methods require training data and they can result cost prohibited if they use complete training datasets in each iteration. Instead, NAS methods have become extremely proficient evaluating candidate architectures by training a predictor of how well a trained learner would perform, by extrapolating from previously trained architectures.
These two ideas: selecting the best examples from a training set and understanding how a neural network learns were the foundation of Uber’s creative method for training machine learning models.
Enter Generative Teaching Networks
The core principle of Uber’s GTNs is based on a simple and yet radical idea: allowing machine learning to create the training data itself. GTNs leverage generative and meta-learning models while also driving inspiration from techniques such as generative adversarial neural networks(GANs).
The main idea in GTNs is to train a data-generating network such that a learner network trained on data it rapidly produces high accuracy in a target task. Unlike a GAN, here the two networks cooperate (rather than compete) because their interests are aligned towards having the learner perform well on the target task when trained on data produced by the GTN. The generator and the learner networks are trained with meta-learning via nested optimization that consists of inner and outer training loops. In the GTN model, the generator produces completely new artificial data that a never-seen-before learner neural network (with a randomly sampled architecture and weight initialization) trains on for a small number of learning steps. After that, the learner network, which so far has never seen real data, is evaluated on real data which provides the meta-loss objective that is being optimized.
The architecture of GTNs can be explained in five simple steps:
1) Noise is fed to the input generator which is used to create new synthetic data.
2) The learner is trained to perform well on the generated data.
3) The trained learner is then evaluated on the real training data in the outer-loop to compute the outer-loop meta-loss.
4) The gradients of the generator parameters are computed to the meta-loss to update the generator.
5) Both a learned curriculum and weight normalization substantially improve GTN performance.

GTNs in Action
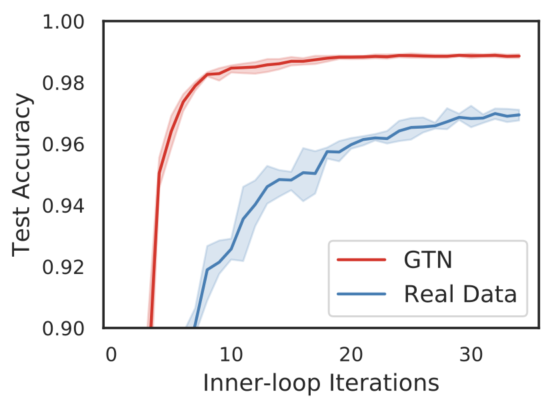
Uber evaluated GTNs across different neural network architectures. One of those scenarios was an image classification model trained using the famous MNIST dataset. After a few iterations, new learners trained using GTN were able to learn faster than the same models using real data. In this specific scenarios, the GTN-trained models achieved a remarkable 98.9 accuracy and did that in just 32 SGD steps (~0.5 seconds), seeing each of the 4,096 synthetic images in the curriculum once, which is less than 10 percent of the images in the MNIST training data set.
One of the surprising findings of using GTNs for image classification is that the synthetic dataset seem unrealistic to the human eye(see image below). Even more interesting is the fact that the recognizability of the images improves towards the end of the curriculum. Despite its alien appearance, the synthetic data proven to be effective when training neural networks. Intuitively, we would think that if neural network architectures were functionally more similar to human brains, GTNs’ synthetic data might more resemble real data. However, an alternate (speculative) hypothesis is that the human brain might also be able to rapidly learn an arbitrary skill by being shown unnatural, unrecognizable data.

GTNs are a novel approach to improve the training of machine learning models using synthetic data. Theoretically, GTNs could have applications beyond traditional supervised learning in areas such as NAS methods. Certainly, applying GTNs in Uber’s massive machine learning infrastructure should yield amazing lessons that will help to improve this technique.
Original. Reposted with permission.
Related:
- This Microsoft Neural Network can Answer Questions About Scenic Images with Minimum Training
- How LinkedIn, Uber, Lyft, Airbnb and Netflix are Solving Data Management and Discovery for Machine Learning Solutions
- Open Source Projects by Google, Uber and Facebook for Data Science and AI